SEO-Константа
Яндекс.Директ + оптимизация
В исходном алгоритме PageRank для улучшения ранжирования результатов поиска вычисляется вектор PageRank с помощью ссылочной структуры Сети, чтобы выделить относительную «важность» Веб-страниц, не зависящую от конкретного запроса. Для достижения большей точности результатов поиска мы предлагаем вычислять набор PageRank векторов, основанных на темах-образцах, чтобы точнее определить важность страниц, в зависимости от заданной темы. Используя эти (заранее вычисленные) PageRank векторы для генерации значений важности документов в зависимости от темы запроса, мы покажем, что можем достичь более точного ранжирования, чем с одним сгенерированным вектором, никак не зависящим от темы. Для запроса из одного слова мы, исходя из темы запроса, просматриваем множества PageRank и ищем страницы, удовлетворяющие запросу, используя тему слов данных в поиске. Для контекстного поиска (например, когда поиск производится с помощью подсветки слов на веб-странице), просчитываются тематические PageRank множества с использованием контекста, в котором производится запрос.
За недавнее время для улучшения результатов поисковых запросов были разработаны различные методы ранжирования, основанные на ссылочной структуре Сети. Алгоритм HITS [14] основывается на вычислениях во время обработки запроса, выявляя хабы и авторити-документы, существующие в подграфе Сети, который содержит как сами результаты запроса, так и связанные с ним. [4] добавляет в алгоритм HITS анализ содержимого, улучшающий точность поиска с целью получения документов, связанных с темой запроса (в противовес получению документов, полностью удовлетворяющих нуждам пользователя). [8] использует HITS для автоматического составления списков основных тем.
Алгоритм PageRank, описанный в [7, 16] заранее вычисляет вектор ранжирования, который априори показывает оценки «важности» всех Веб-страниц. Этот вектор вычисляется один раз оффлайн и не зависит от поискового запроса. Когда делается запрос, эти оценки важности используются в сочетании с зависящими от запроса IR-оценками для ранжирования результатов поиска.PageRank имеет очевидное превосходство над алгоритмом HITS, поскольку время, необходимое на поиск уже вычисленного PageRank-вектора важности страницы, мало. Более того, при генерации PageRank используется весь Веб-граф, а не малое множество, а значит, он менее восприимчив к локальному ссылочному спаму (linkspam).
В этой статье мы предлагаем подход, который (аналогично HITS) позволяет запросу повлиять на основанные на ссылках оценки, но (аналогично PageRank) требует минимального времени на обработку. В нашей модели оффлайново вычисляется набор PageRank-векторов, зависящих от заданной темы, и для каждой страницы создаётся набор оценок важности по соответствующим темам. Идея сделать вычисление PageRank зависимым от темы была предложена в [6] для персонализации поиска, но никогда не была достаточно изучена.
Сделав PageRank зависимым от темы запроса, мы избежим такой проблемы, когда сильно связанные документы получают высокие оценки по запросам, не имеющих к ним отношения (одной из причин может являться продвижение сайтов в поиске) [3]. Страницы, сочтённые важными в одних множествах, могут быть опущены в других, вне зависимости от того, какие ключевые слова могут появиться на странице или тексте-ссылке, ведущем к этой странице [5]. Подход, названный Hilltop, создавался с аналогичной нашей целью [5], и создан для улучшения результатов популярных запросов. Hilltop генерирует оценки важности, зависящие от запроса, делая поиск и индексирование страниц, которые хорошо соотносятся с определёнными словами, основываясь на их внешних ссылках. Впрочем, поисковые запросы, для которых не найдено таких соотношений, не смогут быть обработаны алгоритмом Hilltop.
[17] предлагает использование набора Веб-страниц, которые содержат определённые условия в роли набор зависимостей, влияющих на вычисление PageRank, с целью получения условий, по которым конкретная страница имеет наивысший рейтинг. Этот подход к улучшению ранжирования поисковых запросов с помощью генерации PageRank-вектора для каждого возможного условия запроса представлен в [18] и имеет хорошие результаты. Но такой подход требует значительного времени для вычислений и хранения данный и не имеет простой возможности для расширения до использования контекстного поиска. Наш способ сделать вычисление PageRank зависимым уникален в своём роде, благодаря использованию малого набора общих базовых тем, взятых из Open Directory, в сочетании с униграммной языковой моделью, используемой для классификации поискового запроса и поискового контекста.
В своей работе мы рассматриваем два случая. В первом мы предполагаем, что пользователь, нуждающийся в определённой информации, подаёт запрос поисковой системе традиционным способом – введя этот запрос в поисковую строку. В этом случае мы определяем наиболее близкие запросу темы и используем подходящие тематические PageRank-векторы для ранжирования страниц, удовлетворяющих запросу. Таким образом оценка важности повлияет на предпочтительную ссылочную структуру страниц, относящихся к данному запросу. Как и обычный PageRank, тематический PageRank может быть использован как часть оценивающей функции, которая принимает в расчёт и другие IR-зависимые оценки. Во втором случае предполагается, что пользователь просматривает документ (это может быть Веб-страница или почтовое сообщение) и выделяет в нём текст, по которому хотел бы найти больше информации. Понятие такого контекстного поиска обсуждается в [10]. Например, если запрос «архитектура» произведён выделением слова в документе про строение ЦПУ. Основываясь на контексте поиска, выбираются соответствующие тематические PageRank-векторы, и мы получаем возможность предоставить более подходящие результаты поиска. Заметьте, что даже если запрос сделан традиционным способом, без выделения слова, история поисковых запросов тоже являет собой контекст. Ещё одним источником контекста является сам пользователь. Например, его закладки и история просмотров могут быть использованы при выборе подходящих PageRank-векторов, зависимых от темы поиска. Эти различные источники контекста обсуждаются более подробно в разделе “Источники контекстного поиска”.
Рассмотрим ещё раз, как работает наш метод. Во время оффлайн-обработки результата краулинга, мы генерируем 16 тематических PageRank-векторов, каждый из которых своей темой связан через URL-ссылку с категорией более высокого уровня на Open Directory Project (ODP) [2]. Во время поиска мы просчитываем схожесть запроса (и, если возможно, пользовательский контекст) с каждой из этих тем. Затем вместо использования одного вектора глобального ранжирования мы берём линейную комбинацию контекстно-зависимых векторов, отобранных с помощью сходства запроса (и любого доступного контекста) с темой. Используя набор векторов для ранжирования, мы сможем более точно определить самые важные из них для нашего запроса. Поскольку вычисления по ссылкам производятся оффлайн, на этапе предобработки, то время, затрачиваемое на произведение поиска ненамного больше, чем при использовании обычного алгоритма PageRank.
Рассмотрим алгоритм PageRank [16, 7, 11]. Идея основывается на том, что если страница u имеет ссылку на страницу v, то автор u косвенно придаёт важности странице v. К примеру, Yahoo! является важной страницей, потому что многие другие имеют ссылки на неё. Таким же образом страницы, на которые Yahoo! даёт ссылки, тоже могут быть важными. Какую же важность придаёт страница u тем страницам, на которые ссылается? Пусть Nu – это полустепень исхода страницы u, Rank(p) – важность (то есть PageRank) страницы p. Тогда связь (u,v) предоставляет Rank(u)/Nu единиц ранга странице v. Это ведёт к последующему вычислению, которое выдаст вектор ранжирования Rank→* по всем Веб-страницам. Если взять N за количество страниц, то каждой странице будет присвоено начальное значение 1/N. Пусть Bv – это множество страниц, ссылающихся на v. Тогда при каждой итерации ранг изменяет следующим образом:
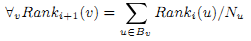
Вычисления продолжаются до тех пор, пока Rank→не стабилизируется в каком-то промежутке. Итоговый вектор Rank→* содержит вектор PageRank всей Сети. Этот вектор вычисляется всего один раз после получения информации из Сети; итоговые значения потом используются при ранжировании поисковых результатов [1].
Процесс так же может быть описан как нижеследующий поиск собственного вектора, что даст нам хорошее представление о PageRank. Пусть M – это квадратная стохастическая матрица, соответствующая направленному графу Сети G, и предполагается, что все вершины G имеют хотя бы одно ребро. Если между страницами i и j имеется ребро (ссылка), то элемент матрицы mij имеет значение 1/Nj. Пусть все остальные значения равны 0. Одна итерация из предыдущей формулы соответствует умножению матрицы на вектор: M x Rank→. Повторное умножение Rank→ на M выдаст основной собственный вектор Rank→* матрицы M. Другими словами, Rank→* является решением
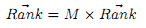
Поскольку M является стохастической переходной матрицей графа G, PageRank можно рассматривать как стационарное распределение вероятностей по страницам, вызванное любой «прогулкой» по сети.
«Подводным камнем» здесь является то, что сходимость PageRank гарантируется только в случае, когда матрица M является неприводимой (то есть когда граф G является сильно связным) и непериодической. Последнее гарантируется в случае с Веб, тогда как предыдущее верно только при добавлении фактора затухания 1 – α в ранжировании. Мы можем найти новую матрицу M’, в которую добавим транзитивные рёбра вероятности α/N между каждой парой вершин в G.
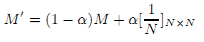
Это нововведение улучшает качество вектора PageRank добавлением фактора затухания 1 – α, который ограничивает эффект спада ранга [6], и дополнительно обеспечивает сходимость уникального вектора ранжирования. Подставив M’ вместо M в формуле 2, вычисление PageRank примет следующий вид:
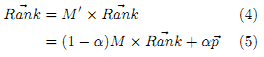
Где p→ = [1/N] N x 1. Ключ к созданию тематического вектора PageRank в том, что мы можем усилить эффективность поиска страниц из определённых категорий, используя неоднородный N x 1 настраиваемый вектор для p→ ([6]). Заметьте, что привязка включает в себя предоставление дополнительного ранга определённым узлам при каждой итерации в вычислении. Это не просто этап пост-обработки, совершаемый в стандартном векторе PageRank.
В условиях модели случайного блуждания вектор персонализации представляет собой дополнение к полному набору ориентированных рёбер, где вероятность перехода по транзитивному ребру (u,v) дана в виде αpv. В таком случае мы будем обращаться к решению Rank→* формулы 5, где α = α* и p = p*, как к PR→(α*,p*). Правильно выбрав p→, можно создать вектор ранжирования по определённым категориям страниц. Фактор зависимости α определяет степень зависимости вычисления от p→.
Наш подход к созданию тематического вектора PageRank включает в себя оффлайновое вычисление оценок важности, аналогично обычному PageRank. Но мы вычисляем множество оценок важности для каждой страницы; мы вычисляем оценки важности страниц относительно различных тем. Во время поискового запроса эти оценки комбинируются в зависимости от темы поиска и формируют составной вектор PageRank из страниц, подходящих запросу. Этот вектор может использоваться в сочетании с другими системами оценки, основанными на IR, чтобы произвести окончательное ранжирование отобранных страниц в соответствии с запросом. Поскольку функционал коммерческих поисковых движков нам неизвестен, влияние их работы на результат не рассматривается. Мы считаем, что улучшения в точности PageRank передадутся в поисковые ранжировки, даже если были задействованы сторонние IRсистемы.
Первым шагом в нашем методе будет генерация набора зависимых PageRank-векторов с помощью набора базовых тем. Этот шаг выполняется один раз, оффлайново, во время обработки содержимого краулинга Сети. Для вектора персонализации от p→, описанного в разделе “Тематический PageRank”, мы используем URL, предоставленные в различных категориях ODP. Мы создадим 16 различных зависимых PageRank-векторов, используя ссылки под каждой из 16-ти высших категорий ODP как векторы персонализации. То есть: пусть Tj – это множество ссылок из ODP в категории cj. Тогда при вычислении PageRank-вектора для темы cj вместо однородного затухающего векторa p→ = [1/N]Nx1мы подставим неоднородный вектор от p→ = от vj→, где
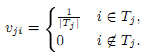
Вектор PageRank для темы cj обозначим как PR→(α,vj). Также, в целях сравнения, мы сгенерируем один независимый вектор PageRank (обозначим его как NoBias). Выбор значения α будет обсуждён в разделе “Мера сходства методов ранжирования”.
Второй шаг нашего метода исполняется непосредственно во время запроса. Пусть дан запрос q, и контекст запроса q’. Другими словами, если запрос был произведён выбором элемента q на какой-либо веб-странице u, то q’ состоит из элементов на самой странице u. Для поисковых запросов сделанных вне контекста, напрямую, примем q = q’. Используя униграммную языковую модель, настроенную на поиск максимальных схожестей, мы вычислим классовые вероятности для каждой из 16-ти высших категорий ODP для q’. Пусть q’i – это i-тый элемент в запросе (или контексте запроса) q’. Тогда по запросу q, для каждого cj мы вычислим следующее:
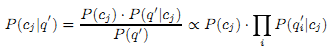
P(q’i|cj) легко вычисляется через классовый вектор Dj. Значение P(cj) вычисляется не так просто. Мы предпочли сделать его однородным, хотя мы и могли персонализировать результаты запроса под каждого пользователя, разнообразив это распределение. Другими словами, для пользователя k мы можем использовать распределение Pk(cj) , которое отражает его интересы. Такой метод обеспечивает альтернативную систему пользовательской персонализации, вместо прямого перебора вектора затухания p→, как было предложено в [7,6].
Используя текстовый поиск, мы получаем ссылки на все документы, содержащие оригинальный запрос q. И наконец, мы вычисляем оценки важности для каждой из полученных URL следующим образом. Пусть rankjd – это ранг документа d, данный вектором ранжирования PR→(α,vj) (например, ранговый вектор темы cj). Для сетевого документа d мы вычисляем зависимую от поискового запроса оценку важности sqd:
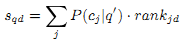
Результаты ранжируются согласно составной оценке sqd.
Это вычисление контекстно-зависимого вектора PageRank имеет следующую вероятностную интерпретацию в условиях модели “случайного блуждания” [7]. Пусть wj – это коэффициент, используемый для придания веса j-му ранговому вектору, и Σjwj = 1 (например, пусть wj = P(cj|q)). Тогда равенство
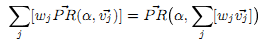
будет верным, что показано в приложении A. Таким образом, мы видим, что случайное блуждание по Сети формирует зависимую от темы поиска оценку sqd. С вероятностью 1 – α случайный сёрфер на странице u перейдёт с неё на внешнюю ссылку (причём эта ссылка выбирается в общем случае случайно). И с вероятность α P(cj|q’) сёрфер вместо этого перейдёт на одну из страниц в Tj (в котором каждая страница выбрана случайно). В более сложном случае вероятность того, что сёрфер находится на странице v, даётся составной оценкой sqd, описанной выше. Получается, что темы теперь имеют влияние на окончательную оценку пропорционально их сходству с запросом (или контекстом запроса).
В качестве источника веб-данных мы использовали последний сеанс краулинга из веб-базы Стэнфорда [12], проведённый в январе 2001 и содержащий около 120 млн. страниц. В нашем содержимом краулинга 280000 URL из 3 млн. находилось в ODP. Для наших экспериментов мы использовали 35 образцов запросов, данных в [9]. Запросы сведены в Таблицу 1.
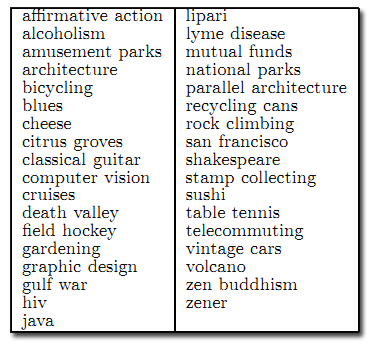
Таблица 1. Использованные запросы.
Мы использовали два способа сравнения ранжирования. Первый способ, обозначенный OSim(τ1, τ2), отражает степень совпадения между топ n URL двух рангов, τ1 и τ2. Мы определяем совпадение двух наборов A и B (каждый размером n) как |A∩B|/n. В нашем сравнении мы будем использовать n = 20. Мера совпадения OSim даёт неполную картину сходства двух рангов. Поэтому мы используем вариант измерения дистанцированности (т.е. различия) Кендалла τ. Для согласованности с OSim мы представим наше определение как меру сходства (в противовес дистанции) таким образом, что значения, стремящиеся к 1 показывают более близкую согласованность. Допустим, есть два частично упорядоченных списка URL, τ1 и τ2, каждый длиной n. Пусть U будет общим URL в τ1 и τ2. Если δ1 = U – τ1, тогда τ1‘ будет расширением τ1, где τ1’ содержит δ1, появляющийся после всех URL в τ1. Мы расширяем τ2 по аналогии с выходом τ2‘. Наша мера сходства KSim определяется как:
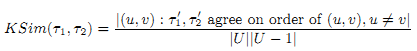
Другими словами KSim(τ1, τ2) является вероятностью совпадения τ1’ и τ2’ по относительному упорядочиванию случайно выбранной пары определённых узлов (u, v) ∋ UxU.
В этом разделе мы оцениваем эффекты тематической зависимости расчёта PageRank. Во-первых, стоит отметить, что выбор фактора зависимости α1 влияет на степень зависимости результирующего вектора от тематического вектора. Например, при α = 1 URL-ам в наборе зависимостей Tj будет дана оценка 1/|T|, а всем остальным URL – 0. И наоборот, если α стремится к 0, содержимое Tj становится нерелеватно при простановке конечных оценок.
Опытным путём было выяснено, что лучше всего использовать α = 0.25. Мы не фокусировались на оптимизации α после того, как узнали, что ранжирование поисковых результатов малочувствительно к выбору α. Например, для α=0.05 и α = 0.25 мы измерили среднее сходство ранжирований в нашем тестовом наборе запросов по каждому из наших PageRank векторов. Результаты сведены в Таблицу 2. Видно, что среднее совпадение между топ-20 результатами по обоим значениям α очень высоко.
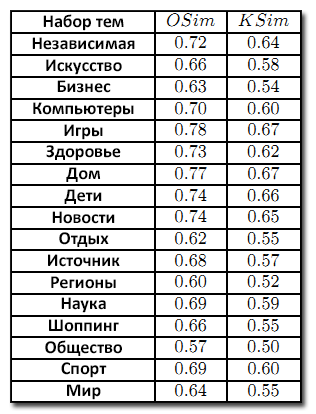
Таблица 2. Среднее сходство сортировок для α = {0.05,0.25}.
Отличия между разными тематически-зависимыми векторами PageRank гораздо выше, включая отличия, вызванные выбором α. Мы рассчитали средние значения парного сходства по нашей тестовой выборке запросов с разными тематическими векторами. 5 наиболее схожих пар в соответствии с метрикой OSim даны в Таблице 3. Таблица 4 показывает, что парные сходства ранжирования другими векторами стремятся к нулю. Узнав, что тематические PageRank вектора ранжируют результаты индивидуально, мы провели дальнейшее исследование по улучшению ранжирования для выбора наилучшего вектора для заданных запросов.
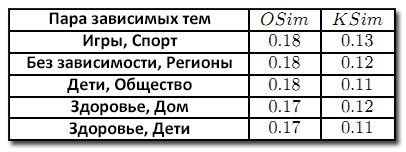
Таблица 3. Пары тем, наиболее схожие при сортировке.
| Незав. | Искус ство | Бизнес | IT | Игры | Здо ровье | Дом | Дети | Нов ости | Отдых | Ссылка | Рег ионы | Наука | Шоп пинг | Общ ество | Спорт | Мир | |
| Незав. | 1 | ||||||||||||||||
| Искусство | 0.09 | 1 | |||||||||||||||
| Бизнес | 0.08 | 0.06 | 1 | ||||||||||||||
| IT | 0.10 | 0.08 | 0.08 | 1 | |||||||||||||
| Игры | 0.07 | 0.12 | 0.08 | 0.11 | 1 | ||||||||||||
| Здоровье | 0.07 | 0.07 | 0.08 | 0.06 | 0.09 | 1 | |||||||||||
| Дом | 0.07 | 0.07 | 0.07 | 0.06 | 0.09 | 0.12 | 1 | ||||||||||
| Дети | 0.08 | 0.08 | 0.04 | 0.06 | 0.09 | 0.11 | 0.09 | 1 | |||||||||
| Новости | 0.07 | 0.09 | 0.07 | 0.07 | 0.11 | 0.09 | 0.07 | 0.09 | 1 | ||||||||
| Отдых | 0.09 | 0.09 | 0.06 | 0.08 | 0.09 | 0.06 | 0.08 | 0.08 | 0.06 | 1 | |||||||
| Ссылка | 0.07 | 0.07 | 0.05 | 0.08 | 0.08 | 0.09 | 0.06 | 0.10 | 0.06 | 0.05 | 1 | ||||||
| Регионы | 0.12 | 0.09 | 0.07 | 0.06 | 0.06 | 0.08 | 0.08 | 0.08 | 0.07 | 0.10 | 0.07 | 1 | |||||
| Наука | 0.11 | 0.08 | 0.08 | 0.07 | 0.09 | 0.11 | 0.06 | 0.09 | 0.08 | 0.06 | 0.10 | 0.08 | 1 | ||||
| Шоппинг | 0.05 | 0.07 | 0.07 | 0.06 | 0.09 | 0.06 | 0.07 | 0.05 | 0.05 | 0.08 | 0.04 | 0.06 | 0.04 | 1 | |||
| Общество | 0.10 | 0.10 | 0.06 | 0.06 | 0.07 | 0.10 | 0.09 | 0.11 | 0.09 | 0.08 | 0.09 | 0.11 | 0.10 | 0.05 | 1 | ||
| Спорт | 0.07 | 0.09 | 0.07 | 0.07 | 0.13 | 0.09 | 0.10 | 0.08 | 0.10 | 0.10 | 0.07 | 0.09 | 0.07 | 0.09 | 0.07 | 1 | |
| Мир | 0.10 | 0.06 | 0.06 | 0.07 | 0.07 | 0.06 | 0.05 | 0.06 | 0.06 | 0.07 | 0.06 | 0.08 | 0.07 | 0.05 | 0.07 | 0.06 | 1 |
Таблица 4. Парное сравнение тематических сортировок (KSim).
В этом разделе мы рассматриваем эффективность ранжирования при его уточнении путём использования нескольких векторов PageRank. При данном запросе нашей первой задачей было определить какой из ранжирующих векторов подходит в данном случае лучше всего. Мы обнаружили, что используя количество P(cj|q) как описано в разделе “Оценка важности во время запроса” позволяет узнать, какие темы ближе всего ассоциированы с запросом. В частности, для большей части тестовых запросов категории ODP с наивысшими значениями P(cj|q) являются самыми релевантными данному запросу. При расчёте комбинированной оценки sqd в наших экспериментах, мы решили использовать взвешенную сумму только векторов ранжирования, ассоциированных с тремя категориями с высшими значениями P(cj|q), а не со всеми темами. Основываясь на данных из эксперимента, видно, что не требуется включать оценки из тематических векторов с низкими ассоциативными значениями P(cj|q).
Мы провели эксперимент по сравнению нашего запросо-зависимого подхода с обычным PageRank. Случайным образом были отобраны 10 запросов из тестовой выборки и были приглашены 5 добровольцев. Для каждого запроса добровольцу было показано 2 ранжирования результатов: одно содержало топ 10 результатов, ранжированных независимым PageRank вектором, а другое – топ 10 результатов, ранжированных комбинированной оценкой sqd. Добровольцев попросили выбрать все URL, являющиеся релевантными запросу по их мнению. Далее, добровольцев попросили оценить, какой метод ранжирования был лучше. Однако пользователи не знали ничего о внутренних механизмах ранжирования. Первая тестовая группа предпочитала ранжирование тематическим PageRank. Пусть URL считается релевантной, если 3 из 5 добровольцев сказали так. Тогда точностью будет являться часть из 10 URL, которая была оценена как релевантная. Точность двух методов ранжирования показана на Рис. 1. Средняя точность тематического PageRank намного выше, чем точность оценки независимого PageRank. Более того почти для всех запросов большинство пользователей предпочитали ранжирование оценок тематическим PageRank. Результаты показывают, что эффективность запросо-зависимой оценки может быть увеличена при замене вектора PageRank на его тематический аналог.
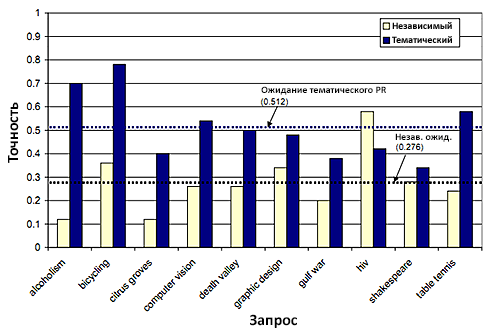
Рисунок 1. Средняя точность по 10 запросам.
В предыдущем разделе тематические вектора ранжирования выбирались при использовании наиболее близких к запросу тем. Если проводится контекстный поиск, например, подстветкой слова на веб-странице, то в таком случае контекст может использоваться вместо запроса, чтобы определить тему поиска. Используя контекст можно определить смысл запроса и выдать результаты, которые наиболее полно удовлетворяют намерения пользователя. Далее мы описываем пример контекстного запроса.
Будем считать, что запрос «сплин» взят из нашей тестовой выборки. Это слово имеет несколько значений: например, может относиться к музыкальной группе, а так же может обозначать лёгкую меланхолию. Допустим, есть две веб-страницы, на каждой из них слово «сплин» используется в разных смыслах. Предположим, что пользователь читает одну из этих страниц и выделяет слово, чтобы потом провести по нему поиск. За время запроса задачей нашей системы является определение, какая тема лучше всего подходит запросу в нужном контексте. Для этого мы рассчитываем P(cj|q’) в контексте q’ всей страницы, а не для отдельного слова. Для первой страницы (обсуждение группы) argmax cj P(cj|q’) будет отнесён к Искусству, а для второй (меланхолия) argmax cjP(cj|q’) – к Здоровью. Следующим шагом будет использование текстового индекса для составления списка URL всех документов, содержащих слово «сплин» — выделенное слово, по которому задаётся запрос. Наконец, URL ранжируются с использованием подходящего вектора, который был выбран, используя значение P(cj|q’) (Искусство или Здоровье). В результате экспериментов было выяснено, что тематическая релевантность страниц при использовании такого контекстного поиска на порядок превышает точность ранжирования независимым вектором PageRank.
В предыдущем разделе мы рассмотрели только один возможный источник поиска по контексту, однако существуют и другие варианты. Например, можно использовать историю запросов пользователя, предшествующую последнему запросу. Запрос «баскетбол» предшествующий запросу «Джордан» явно указывает на тему поиска. Источниками, помимо истории, могут являться графы переходов пользователя, закладки и архивы электронной почты. При использовании упомянутых источников контекстного поиска, тематический PageRank имеет ряд особенностей при персонализации выдачи.
Гибкость. Для любого вида контекста можно рассчитывать контекстную оценку PageRank, используя классификатор в определении сходства контекста с базовыми темами и затем взвешивании тематических векторов PageRank. Можно использовать такие источники как электронная почта, закладки, история посещений и запросов.
Прозрачность. Зависящие от темы вектора ранжирования дают явные результаты. Если мы видим, что наша система отдаёт предпочтение определённым темам, классификатор можно дополнительно настроить на контекстный поиск или подправить веса тем вручную. При использовании пользовательского контекста, сами пользователи могут выбирать те темы в системе, которые наиболее точно отражают их интересы.
Приватность. Некоторые виды контекстного поиска поднимают вопросы о неприкосновенности личной информации. Естественно, отсылать личные данные пользователя поисковым системам без их ведома является явны нарушение прав. Однако программа-клиент (например, веб-браузер) может создавать персональный профиль пользователя локально на личном компьютере и отсылать на сервер только суммарную информацию, содержащую веса, назначенные базовым темам. Вариант передачи информации, что пользователь заинтересован в теме «Компьютеры», является гораздо более мягким по отношению к правам, нежели передача полного графа посещений веб-страниц. Пользователи будут гораздо больше удовлетворены, если в переданной информации будет только категория их поиска, а не сам текст документа, который они читают, ведь это может быть частная неприкосновенная информация, не предназначенная для третьих лиц.
Эффективность. С небольшим количеством категорий (в ODP их всего 16) как обработка за время запроса, так и оффлайновая подготовка в нашем методе занимают мало времени и могут легко быть введены в инфраструктуру индексирования Веба.
На данный момент ведутся работы по улучшению алгоритма тематического PageRank. Нахождение дополнительных источников контекстного поиска и их правильное использование являются приоритетной задачей. Кроме того, проводится исследование по определению лучшего набора базовых тем. Возможно, имеет смысл использовать более глубокие вложенные темы второго и третьего уровня в иерархии Open Directory Project, а не просто брать темы верхнего уровня. Однако увеличение числа тем вызывает проблему эффективности , так как затраты на расчёт тематических векторов линейно зависят от числа базовых тем.
Так же разрабатывается иной метод создания вектора затухания p→, использующегося для создания тематических векторов ранжирования. Данный метод имеет возможности подстраиваться под изменения ODP, вносимые редакторами. На данный момент, вектор p→ для темы cj приравнивается к vj→, который, в свою очередь определяется в уравнении 6. В усовершенствованном методе мы сначала обучаем классификатор по набору базовых тем, используя ODP, а потом уже распределяем веса тем по всем страницам в Сети. Если вес темы на странице u категории cj будет обозначен как wuj. Тогда уравнение 6 пример вид:
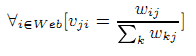
Таким образом, мы хотим ещё больше повысить точность работы тематического PageRank.
Допустим, имеется набор векторов {PR→(αvj→)} с постоянным значением α. Для краткости, пусть rj→ = PR→(αvj→). Пусть r‘→ = Σj[wjrj→] и v‘→ = Σj[wjvj→]. Считается, что r‘→ = PR→(αv‘→). Другими словами, вектор персонализации p→ приравнивается к v‘→. Так как каждый rj→ удовлетворяет уравнение 5, можно доказать:
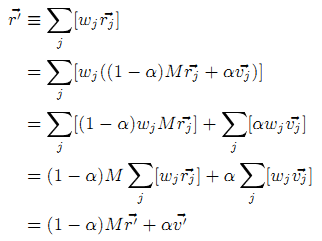
Выражаем благодарности профессору Jeff Ullman за бесценные комментарии и отзывы. Так же, благодарим Glen Jeh, профессора Jennifer Widom, Aristides Gionis и всех анонимных комментаторов с полезными отзывами.
Полезная информация по продвижению сайтов:
Перейти ко всей информации