SEO-Константа
Яндекс.Директ + оптимизация
Развитие интернета создаёт трудности для поисковых систем по мере того, как всё большее количество копий веб-документов наводняют поисковые результаты, тем самым ухудшая релевантность выдачи пользовательскому запросу. Для решения этой проблемы предлагается метод «описательных слов» для нахождения идентичных веб-документов. Он основывается на выборе N количества слов из индекса для определения «подписи» документа и может быть использован в любой поисковой системе, работающей с инвертированным индексом. Этот метод сравнивается с другим методом, основанным на «каскадном» анализе. При почти одинаковой точности выполняемых алгоритмов, метод «описательных слов» более эффективен при наличии инвертированного индекса.
Развитие интернета создаёт трудности для поисковых систем по мере того, как всё большее количество копий веб-страниц сайтов наводняют поисковые результаты, тем самым ухудшая релевантность выдачи пользовательскому запросу. Природа копий разнообразна: один и тот же документ, обработанный одним и тем же сервером, может иметь различия по техническим причинам – другой набор символов, формат, включение текстовой рекламы или текущей даты. С другой стороны, похожие документы генерируются в огромном количестве серверами баз данных, например, сообщениями на форумах, страницами с описанием каталога продукции в интернет-магазинах и т.д.
Вопрос определения максимально схожих копий был рассмотрен в работах [1,2,4,5] различных исследовательских групп. Предложенное решение может быть описано следующим образом: сканировать каждый документ, рассчитать значения хэшей («отпечатков») каждого фрагмента документа («каскада»), который может повторяться, а после этого протестировать полученную выборку по приемлемым критериям и использовать этот уменьшенный набор проверочных сумм («эскиз») во всех последующих операциях с выборкой. Фрагментами могут являться предложения [2], последовательность байтов [1], согласных букв [4] или слов [5]. Были предложены постоянные и переменные размеры эскизов: количество наименьших проверочных сумм и все проверочные суммы, делящиеся на целое число. В работе [3] был предложен метод выбора набора слов и улучшение модели векторного пространства для сравнения пар документов.
«Каскадный» метод уменьшает размер выборки для каждого документа и позволяет упростить задачу кластеризации. Но по-прежнему кластеризация документов остаётся вычислительно сложной операцией и, как правило, требует инверсии отношения документ –каскад. Мы применяем цифровую подпись, которая вероятностно-устойчива к небольшим изменениям документа, таким образом, процесс кластеризации становится лишним. В настоящее время все известные нам системы информационного поиска уже обладают базой данных «обратного (инвертированного) индекса» всех слов и соответствующих идентификаторов документов. Наличие общей статистики слов позволяет осуществлять рациональный выбор слов для точного и эффективного решения проблемы определения дубликатов. В то же самое время соответствующий каскадный подход представляется нам более сложным ввиду большого объёма набора включенных в него элементов.
Предположим, что у нас есть ряд документов, каждый документ является набором слов. Следовательно, мы имеем дело только с идентичностью лексики. Мы предлагаем алгоритм, который создаст «набор повторений». Точность алгоритма может быть выражена в вероятностях двух типов ошибок. «Альфа-ошибкой» называют ситуацию, когда алгоритм не обнаружил повторений, а «бета-ошибкой» — случай, когда алгоритм предположил ложное повторение. По всей видимости, ошибки могут исключать друг друга; однако не существует идеального алгоритма проверки.
Тем не менее, необходимо разделить задачу на две части: в первой создавать «набор повторений» и во второй проверять их.
Для начала необходимо выбрать некий набор из N количества слов, который мы назовём «набор описаний»; выбор слов будет обсуждаться позже.
Для каждого слова определим порог частоты bi и для каждого документа рассчитаем вектор, где i-ому компоненту вектора присваивается значение 1 в случае, когда значение относительной частоты i-ого слова из «набора описаний» в этом документе больше, чем определённый порог частоты. В противном случае присваивается значение 0. Этот бинарный вектор считается нечёткой цифровой подписью документа. Каждый вектор однозначно определяет класс похожих документов, поэтому его уникальный идентификатор может заменить соответствующий вектор. Векторы с тремя и менее словами выше порога частоты не принимаются в дальнейшем расчёте.
Сформулируем основной критерий для выбора слов.
«Качество» слова может быть определено как стабильность соответствующего компонента вектора по отношению к небольшим изменениям в документе. Это означает, что для «хорошего» слова i вероятность перехода (в дальнейшем λi) через пороговое значение минимальна для небольших изменений в документе. Очевидно, что вероятность изменения вектора для документа такова:
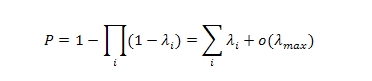
Выбранный порог bi удовлетворяет следующему критерию: значение λi минимально при условии, что обе части (выше и ниже порога) не слишком малы. Это условие необходимо для проверки, что почти все документы имеют ненулевые векторы.
Оптимальное количество слов (N) в «наборе описаний» было определено экспериментально.
Мы использовали нормализованное расстояние Левенштейна (редакционное расстояние) для определения похожести двух документов. Эти документы признавались одинаковыми, если различия между ними не превышали 8%. Это значение было получение в экспериментах, когда 6 экспертов привели 300 утверждений по схожести документов: мы попросили их рассказать, какие пары документов являются одинаковыми с точки зрения пользователя поисковой системы. Тексты были предварительно очищены от HTML-разметки. На данный момент наши методы не берут в расчёт важность несовпадающих слов, например частоту слов, которые являются важными в случаях с онлайн-магазинами и прочими документами из баз данных.
Было использовано 60 миллионов документов из индекса Яндекса [6], мы собрали кластеры повторений для нескольких размеров «набора описаний» и проверили каждый кластер на «почти полное сходство» (8%), как было описано выше. Расчётный размер выборок был ограничен пределами от 1600 до 3000 слов. Уменьшение размера «набора описаний» снижало частоту альфа-ошибок, но повышало частоту бета-ошибок. В определённый момент количество «правильно определённых» повторений прекратило увеличиваться, а количество ложных повторений оставалось низким. Выбранным размером набора было 2000 слов.
В этой таблице показано сравнение нашего метода с «каскадным» при одних и тех же условиях. «Каскады» рассчитывались [5] с 10 словами в каскаде, 48-битной проверочной суммой, модулем 16 и порогом похожести 7/8 из набора каскадов.
| Количество предложенных повторений | Различие < 8% | Различие < 15% | Различие < 30% | Расчётное время | |
| Метод «описательных слов» | 22 миллиона | 61% | 76% | 91% | ~1.5 часа |
| «Каскадный» метод | 19 миллионов | 66% | 80% | 94% | ~3.5 часа |
Таблица 1. Сравнения метода «описательных слов» и метода «каскадов».
Алгоритм использует только инвертированный (обратный) индекс, который применяется в большинстве поисковых систем. Он обладает высокой скоростью, а так же легко обновляется до более свежих версий из-за того, что «нечёткая цифровая подпись» является общим свойством документа и база данных не требует повторной кластеризации при каждой последующей переиндексации веб-документов в поиске. При почти одинаковой точности обоих алгоритмов, этот метод более эффективен при наличии инвертированного индекса. Данная информация будет безусловно полезна для тех компаний, которые осуществляют продвижение сайтов в поисковых системах Яндекс и Google.
Перевод материала «An Efficient Method to Detect Duplicates of Web Documents With the Use of Inverted Index» выполнил Роман Мурашов
Полезная информация по продвижению сайтов:
Перейти ко всей информации