SEO-Константа
Яндекс.Директ + оптимизация
В этой статье мы покажем способ извлечения пользовательских новостных запросов из логов поисковых машин. Данный метод использует частоту запросов и поиск по подборке последних новостей. Новостные запросы могут быть полезны как для уточнения информации, требуемой пользователем, так и для эффективной обработки новостей в режиме онлайн. Проведенное исследование доказывает, что наш алгоритм имеет высокую степень точности.
Логи пользовательских запросов поисковой системы являются богатым источником ценной информации о предпочтениях пользователя, стратегии поиска и т.д. Они стали мощным инструментом для улучшения эффективности поиска и взаимодействия конечного пользователя с поисковой системой. [Приватные и неоднозначные логи запросов поисковой машины содержат в себе не только сами пользовательские запросы, но и то, как складывалось поведение пользователя на поиске непосредственно. Основа качественного поиска сегодня, в частности поиска по контексту, заключается именно в использовании накопленного в течение множества лет логов запросов. По этой причине мы не можем говорить о внезапном появлении какой-то крупной поисковой машины на рынке поисковых услуг, поскольку для предоставления качественного поиска ей потребовалось бы располагать подобного рода материалам. Такие же поисковые системы, как Яндекс, Google, Yahoo!, Bing очень неохотно делятся этой ценнейшей информацией. Занимаясь анализом поведения своих пользователей, поисковики возвращают полученную ранее информацию в виде последующего улучшения качественной составляющей поиска, показов контекстной рекламы и т.д. – прим. К.С.] Существует большое количество статей по анализу логов веб-запросов. Недавно появилось несколько научных публикаций, которые сфокусировались на анализе временного журнала запросов. Например, статья [1] рассматривает тематическое разнообразие запросов на протяжении дня. Chien и Immorlica [2] выделяют семантически релевантные запросы, основанные на похожем временном поведении по их популярности.
В этой статье мы показываем метод для извлечения запросов, относящихся к недавним, нынешним или грядущим событиям в реальной жизни, отражённым в новостях или в новостных запросах. Наш подход является в определённой степени дополняющим метод, описанный в [3]. В то время как Henzinger et al. извлекает запросы из стенограмм телевещания, таким образом запуская «беззапросный поиск новостей», нашей целью является извлечение запросов, относящихся к событиям реальной жизни из логов органического поиска, используя частоту запросов и сопоставляя их с лентами текущих новостей.
Новостные запросы могут использоваться как для устранения неоднозначности в определении информационных требований пользователя (например, предлагая пользователю ссылку на онлайн-трансляцию новостей), так и для высокоэффективной обработки онлайн-новостей, включая кластеризацию, реферирование и ранжирование.
Статья кратко описывает метод для извлечения новостных запросов из сервиса Яндекс.Новостей (news.yandex.ru), который использует лог запросов и инфраструктуру поисковой системы общего назначения Яндекс (yandex.ru).
Значимость запроса в отрезке времени по отношению к другому отрезку времени определяется как соотношение соответствующих частот запросов:
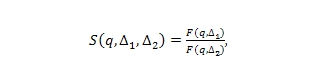
где F(q, ∆) – частота q во времени ∆.
Мгновенная новизна запроса определяется как значимость запроса в последний час по сравнению с предыдущим днём:
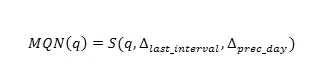
Для подавления некоторой временной неоднородности (таких, как запросы погоды утром и запросы взрослой тематики по ночам [Действительно, в поисковых машинах существуют целые отделы по обработке запросов взрослой тематики (после коммерции, они занимают лидирующее положение в общем потоке), основная цель которых заключается в недопущении случайного появления подобного рода документов по нетематическим для них запросам. Считается, что являясь неоднородным по своей временной составляющей, основной поток взрослых запросов приходится на ночное время, а запросы, например, связанные с погодой и курсами валют на утреннее, поэтому суточная составляющая является одним из факторов их ранжирования. Это верно не только для новостных, но и для обычных запросов – прим. К.С.]) мы определяем часовую новизну запроса как значимость запроса в последний час по сравнению с тем же часом в усреднённом значении по предыдущей неделе:
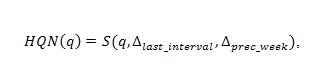
где ∆prec_week – сумма отрезков времени, соответствующих 7 часам в предыдущие 7 дней.
Итоговая новизна запроса определяется как минимум мгновенной и часовой новизны запроса:
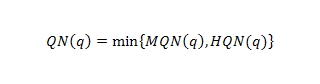
Для определения свежих запросов очень редкие запросы исключаются; остальные нормализуются (этот шаг включает учет морфологии, перевод регистра и удаление некоторых символов, например, вопросительных знаков). Запросы со степенью новизны, превышающей определённый заранее лимит, считаются свежими.
Новостные запросы являются подклассом свежих запросов. Для того, чтобы их извлечь, во-первых, убираются наиболее общие запросы (менее чем 0.1% релевантных документов в базе Яндекса). Во-вторых, релевантные новости должны укладываться в трёхчасовой интервал даты запроса. Для запросов превышающих 0.01% от всех релевантных документов в базе, поиск подборок новостей ограничен только заголовками.
Описанный процесс извлекает десятки тысяч свежих запросов и, затем, от десятка до сотен связанных с ними новостных запросов из более чем одного миллиона запросов ежечасно. Мы оцениваем долю новостных запросов в 0.01-0.1% (однако доля возрастает десятикратно, когда происходит важное событие). При извлечении из общего потока узкого класса запросов мы ставим своей целью достижении более высокой точности, нежели чем полноты результатов. Также, извлечённые запросы имеют ряд интересных особенностей.
Первая особенность заключается в том, что новостные запросы имеют отличное распределение длины по сравнению с обычными веб-запросами. [Как будет показано ниже (да и вообще) логи поисковой машины очень короткие, хотя за последнее время в сегменте российского интернета наметилась тенденция к увеличению их длинны (в среднем от 2-3 слов), что косвенно может являться сигналом о достижении определенного пользовательского уровня – прим. К.С] График 1 показывает распределение длин запросов, относящихся к трагедии в Беслане 1-3 сентября, 2004 г. (однако этот вид распределения типичен для новостных запросов в целом).Статистика веб-запросов происходит из одночасового лога одной из интерфейсных машин Яндекса. Большая часть (33%) веб-запросов состоит из одного слова, в то время как большая часть (37%) новостных запросов состоит из двух слов. Из новостных запросов 81% состоит из нескольких слов.
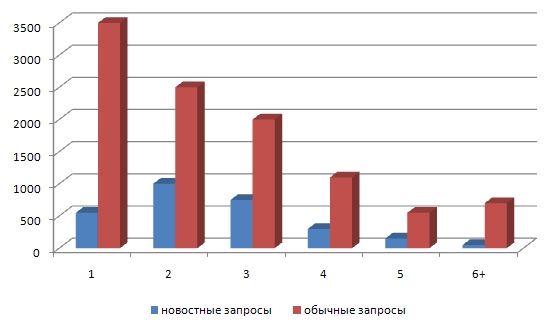
График 1. Длины новостныхобычных веб-запросов
Новостные запросы не просто длиннее: в них сконцентрированы ключевые слова-описания, часто соединяя вместе важные свойства событий (т.е. место, дату, актёров или тип мероприятия). Эта особенность проиллюстрирована тремя парами запросов-образцов, относящихся к трём событиям (пресс-конференция президента Путина, анонс номинантов на Оскар и предупреждение о компьютерном вирусе) (см. Таблицу 1). Кластеризация новостей в Яндекс.Новостях позволяет сегментировать лексически разные запросы, относящиеся к событиям. Отсюда используя относительно прямолинейный способ, мы можем получить дополнительную важную информацию, которая позволит обрабатывать новости более надёжно и точно. Извлечение только многословных элементов из новостей потребовало бы тяжеловесных лингвистических методов.
| пресс-конференция путина |
| пресс-конференция в кремле |
| компьютерный вирус 3 февраля |
| вирус nyxem |
| горбатая гора энга ли |
| номинанты на оскар |
Таблица 1. Извлечённые образцы событийных запросов (31 января, 2006).
Более того, интенсивность извлечённых запросов является хорошим индикатором нынешних информационных потребностей пользователя. Как доказано нашими результатами, заинтересованность интернет-пользователя (по всей видимости, подогретая телевидением) растёт быстрее, чем отклик онлайн-источников новостей, что делает новостные запросы полезным параметром для ранжирования новостей.
Яндекс обрабатывает около миллиона запросов в час в дневное время суток, что делает невозможной оценку значительной части лога вручную. Мы выбрали четыре одночасовых промежутка между 10 утра и 7 вечера в два последовательных рабочих дня в декабре 2005. Тестовая выборка включала в себя все запросы, автоматически определённые как новостные, а так же 2% случайно выбранных запросов из оставшихся с соответствующими интервалами. Тестовая выборка содержала 831 запрос, из которых 244 (30%) были автоматически определены как новостные.
Выборка была предоставлена эксперту, который определял категорию запроса. Эксперт отвечал на вопрос «Верно ли предположение, что подавляющее большинство пользователей, подавших запрос, в данное время интересуются свежими новостями?» Результаты оценки описаны в Таблице 2 (число пропусков умножено на 50; из-за нехватки места мы не ссылаемся на значения полноты и точности по частоте более 10%). Данные позволяют нам сделать несколько замечаний.
Во-первых, совпадение мнений эксперта и алгоритма растёт постепенно от первой оценённой части к последующей. Это можно объяснить ростом компетентности эксперта во время оценки, так как двигаясь от первых запросов эксперт получает более полный взгляд на релевантные события.
Во-вторых, в обоих случаях, полнота утренних запросов значительно ниже, чем полнота вечерних. Это можно объяснить программными особенностями алгоритма. По причинам производительности, свежие запросы определяются на основе статистики запросов для всего предшествующего дня (см. Раздел 2). Таким образом, если событие произошло вчера, а релевантные статьи и запросы так же датированы вчерашним днём, следующим утром алгоритм будет ошибаться в категоризации запросов как новостных.
| 13:00, 7.12 | 18:00, 7.12 | 10:00, 8.12 | 15:00, 8.12 | |
| Пропуски | 9*50 | 7*50 | 7*50 | 5*50 |
| True | 122 | 130 | 101 | 145 |
| False | 30 | 24 | 12 | 27 |
| Точность | 0.80 | 0.84 | 0.89 | 0.84 |
| Полнота | 0.21 | 0.21 | 0.22 | 0.37 |
| F1 | 0.34 | 0.41 | 0.35 | 0.51 |
Таблица 2. Результаты оценки.
Представленный способ для извлечения новостных запросов из органического поиска имеет высокую точность. Извлечённые запросы могут быть эффективно использованы для улучшения взаимодействия пользователя с поисковой системой, онлайн-обработки новостей, их также должно учитывать продвижение сайтов на поиске Яндекса. Результаты, отражённые в Разделе 4 показывают, что определение новостных запросов в утренние часы может быть улучшено путём сравнения статистики запросов не с предыдущим днём, но с плавающим интервалом. Кроме того, мы планируем провести эксперимент с периодичностью в 15 минут с целью повышения чувствительности нашего алгоритма, что также очень важно для задачи обработки новостей.
Перевод материала «Extracting News-Related Queries from Web Query Log» выполнил Роман Мурашов
Комментарии [указаны отдельно] Константин Скоморохов
Полезная информация по продвижению сайтов:
Перейти ко всей информации