SEO-Константа
Яндекс.Директ + оптимизация
С растущей популярностью браузерных тулбаров встаёт важная задача по использованию информации о пользовательском поведении из логов данных расширений. Анализ пост-кликовых поисковых маршрутов дал важную информацию о пользовательском поведении и помог улучшить существующие поисковые системы. Однако по-прежнему мало изучена полезность различных свойств поисковых маршрутов для использования в современных моделях ранжирования. Проведя крупномасштабное исследование и оценив работу многих характеристик в близких к реальным условиях мы пришли к выводу, что углублённое изучение пользовательского поведения за пределами клика по поисковому результату может способствовать развитию существующих алгоритмов ранжирования.
В последние несколько лет данные о пользовательском поведении играют всё более важную роль в различных задачах информационного поиска. Наиболее известным способом выяснения предпочтений пользователей и их удовлетворённости поиском является анализ кликов по результатам на странице поисковой выдачи. Косвенная информация о пользовательской реакции в большом объёме передаётся через клики, однако её ценность и надёжность находятся под вопросом, так как большую часть своих действий пользователи главным образом совершают уже после клика по поисковым результатам.
Ввиду своей растущей популярности, браузерные расширения частично компенсируют нехватку данных о поведении пользователей после клика, записывая в лог их последующие действия в браузере. В [1] наглядно показано, что основные статистические показатели о взаимодействии пользователя с веб-страницами, например, длительность пребывания, можно с уверенностью использовать в моделях ранжирования документов. Однако общая последовательность веб-страниц, которые пользователь продолжает посещать с целью получения искомой информации после клика на странице результатов (т.н. пост-кликовый поисковый маршрут), мало изучена в качестве источника данных для улучшения ранжирования своих документов. Мы считаем, что основательный анализ поисковых маршрутов может помочь в дальнейшем развитии существующих моделей информационного поиска, наряду с уже известными характеристиками наподобие длительности визита.
Крупномасштабное изучение различных особенностей поисковых маршрутов, представленное в данной работе, является продолжением предыдущих работ по исследованию данных о пользовательском поведении и его применения в информационном поиске. По аналогии с [7] мы отображаем поисковые маршруты как древовидные структуры, где в качестве корней выступают кликнутые результаты поиска, а звенья дальнейших переходов по гиперссылкам являются ветвями структуры. Поисковый маршрут, рассматриваемый как древо, так же наследует и его характеристики: число узлов, глубину, ширину и среднюю длину ветви. В дополнение к этим особенностям, мы так же исследуем ещё один ряд характеристик, включая количество шагов по маршруту и продолжительность бездействия пользователя, наблюдаемого после каждого шага. Некоторые свойства маршрутов уже изучались ранее в таких теоретических исследованиях как [7], но, насколько нам известно, их реальная полезность для информационного поиска не оценивалась по IR-метрикам. Большинство характеристик, будучи извлечёнными на уровнях документа или домена кликнутого результата, существенно повышают производительность базового поискового алгоритма, включающего в себя современные особенности пост-поисковых маршрутов. Это подтверждает вышеупомянутое предположение о том, что можно узнать больше о релевантности кликнутого результата, если опираться не только на длительность пользовательского визита.
Таким образом, вклад данной работы заключается в (1) проведении серьёзного исследования множества характеристик поисковых маршрутов и их ценности для систем информационного поиска и (2) выводе, что глубокое изучение характеристик поисковых маршрутов способно предоставить некоторые дополнительные сведения, важные в ряде задач информационного поиска.
С точки зрения поисковой системы интегрирование данных о пользовательском поведении в существующую систему ранжирования наиболее практично осуществлять посредством разработки новых факторов, отражающих разные методы взаимодействия пользователя с веб-сайтом. [1] была одной из первых работ, в которой характеристика пользовательского поведения извлекалась из логов посещений и использовалась с целью улучшения качества ранжирования. Помимо изучения особенностей поведения, авторы так же уделили внимание общей статистике пользовательского взаимодействия с веб-страницей при различной длине визита. В [4] было показано, что можно узнать больше важных деталей об опыте пользователя, анализируя такие элементы сессии как перемещения курсора мыши и скроллинг страниц. Что касается данной работы, мы также собираем характеристики «кроме длительности визита», но делаем это намного глубже первой страницы в поисковом маршруте. Так же возможно использовать данные о пользовательском поведении разработав модель оценки поиска текста на основе языковой модели первоначальных запросов, которые ведут к исследуемому документу через поисковый маршрут, полученный из лога тулбара [2]. В [8] показано, что в совокупности информация поисковых маршрутов намного ценнее, чем данные, получаемые при сравнении первой и последней страницах маршрута по характеристикам релевантности, тематического охвата, разброса тем, новизны и полезности. В данной работе поисковые маршруты изображены по предложению из [7] как древовидные структуры. Кроме того, мы используем некоторые свойства графа, рассмотренные в той же работе. В [5] показано, что эти свойства весьма полезны при поиске наилучшего маршрута. В [3] бинарность кликов по результату, характеризовавшая наличие пост-кликового маршрута, использовалась в обучении классификатора по определению шумовых кликов.
Все эксперименты, описанные в данной работе проводились с использованием данных о поведении пользователей, хранимых в анонимизированном логе тулбара для популярного поискового браузера с миллионной аудиторией по всему миру. Каждая из записей в логе содержала уникальный (анонимный) идентификатор пользователя тулбара, время и подробности пользовательского действия, такого как, например, поданный запрос, URL посещённой страницы или закрытие окна браузера. Мы извлекли все записи из логов тулбара за трёхмесячный период с 11 декабря 2012 по 10 марта 2013. В данных содержалось 3 млрд. пользовательских запросов, 5.3 млрд. поисковых маршрутов и 16 млрд. посещений страниц 2,7 млрд различных документов.
Из этих данных мы извлекли поисковые маршруты, которые начинались с запроса пользователя и состояли из последовательности посещений тем же пользователем веб-страниц, вероятнее всего отвечающих его информационным нуждам. В целях понижения шума от страниц, не относящихся к интересу пользователя, выраженному начальным запросом, мы завершали поисковые маршруты в случаях, когда (1) пользователь подавал новый запрос, (2) пользователь возвращался на домашнюю страницу, вводил URL в адресную строку браузера или переходил на веб-страницу через закладки браузера, (3) наблюдалось более 30 минут пользовательской неактивности, (4) пользователь закрывал окно браузера. Этот список правил схож со списком в [7], определяющим поисковый маршрут, кроме правила «проверять e-mail или авторизацию в сервисе», которое, скорее, мешает, так как пользователь может продолжать поиск, кликая по гиперссылке, которая ведёт его на сайт с требованием авторизации.
В данном разделе мы кратко описываем способ создания поисковых маршрутов, похожий на предложенный в [7]. Как упоминалось выше, мы рассматриваем каждый поисковый маршрут как структуру, схожую с древовидной. Узлы данных древ соответствуют уникальным страницам, а направленные рёбра соответствуют переходам пользователей по гиперссылкам. Таким образом, продвижение по гиперссылкам отражается как переходы по ветвям древа. Кроме того, если пользователь неоднократно возвращается к какой-либо странице, посещённой на одном из предыдущих шагов, этот переход считается за возвращение к соответствующему ранее посещённому узлу древа. После этого, переходы к новым страницам по гиперссылкам генерируют новые ветви деревьев. Если пользователь возвращается к странице результатов и кликает по новому документу, мы создаём новое древо. См. пример древовидной структуры на Рисунке 1. В следующем подразделе опишем характеризующие поисковый маршрут свойства, которые мы используем как факторы ранжирования в дальнейшем.
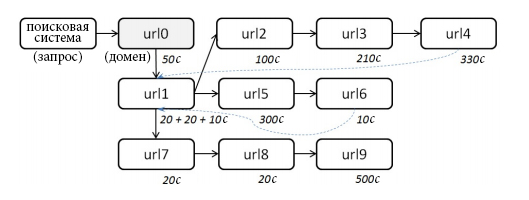
Рисунок 1. Поисковый маршрут, показанный как древо. 10 узлов, глубина 4, ширина 3, длина ветви 3, 12 шагов, повторных посещений 2, длительность 1590 секунд, удовлетворяющих шагов 6, длинных шагов 3.
Помимо вышеописанных характеристик, которые отражают свойства древа маршрута и, следовательно, зависят непосредственно от топологии древа, существуют иные характеристики, отражающие особенности перемещения пользователя по древу маршрута.
На рисунке 1 показан пример поискового маршрута с изображённым значением вышеописанных характеристик.
После извлечения характеристик каждого маршрута, они все были объединены одним из двух способов: на уровне первого документа поискового маршрута (агрегация URL-уровня) и на уровне домена документа (агрегация домен-уровня). В качестве результатов каждого метода агрегации были получены образцы поисковых маршрутов, ассоциированных либо с документами, либо с доменами. Для каждой вышеописанной характеристики были рассчитаны её среднее значение (av), стандартное отклонение (std), 10-й и 90-й перцентиль (10th, 90th), максимум и минимум (max, min) для последующего использования в качестве факторов ранжирования. Далее мы проводим исследование зависимости описанных характеристик от темы домена веб-страницы.
В данном разделе мы изучаем распределение характеристик поискового маршрута по различным темам исходных веб-страниц. На данном шаге мы пользуемся проприетарной БД доменов, вручную рассортированных по темам. Мы разработали наивный байесовский классификатор, обученный по этим данным используя униграммные свойства доменных страниц. Каждому домену второго уровня, страницы которого представлены в данных поисковых маршрутов, классификатор назначает тему, выбранную из отсортированной базы данных. Для каждой нужной характеристики, собранной на уровне домена (см. Раздел 4.3), мы рассчитываем её среднее значение по всем страницам в пределах той же темы. Таким образом для всех тем были получены средние значения каждой характеристики. Для данной характеристики выполняется ранжирование всех тем в соответствии с назначенным средним значением. Результаты сведены в Таблицу 1.
| Узлы | Глубина | Ширина | |||
| Частная жизнь | 2.20 | Частная жизнь | 1.91 | Спорт | 1.26 |
| Спорт | 2.15 | Отдых | 1.85 | Отдых | 1.24 |
| Отдых | 2.14 | Спорт | 1.83 | Частная жизнь | 1.24 |
| Автомобили | 2.06 | Автомобили | 1.80 | Автомобили | 1.21 |
| Бизнес | 1.98 | Бизнес | 1.76 | Трудоустройство | 1.21 |
| Длина ветви | Шаги | Повторные посещения | |||
| Частная жизнь | 2.65 | Частная жизнь | 2.68 | Развлечения | 0.70 |
| Отдых | 2.63 | Спорт | 2.64 | Спорт | 0.56 |
| Автомобили | 2.59 | Отдых | 2.63 | Частная жизнь | 0.55 |
| Бизнес | 2.58 | Автомобили | 2.54 | Отдых | 0.54 |
| Спорт | 2.58 | Бизнес | 2.42 | Автомобили | 0.53 |
| Разнообразие | Удовлетворительные шаги | Длинные шаги | |||
| Компьютеры | 1.13 | Общество | 0.24 | Отдых | 1.15 |
| Развлечения | 1.12 | Сми | 0.20 | Общество | 1.11 |
| Трудоустройство | 1.12 | Развлечения | 0.20 | Автомобили | 1.10 |
| Общее | 1.12 | Наука | 0.20 | Спорт | 1.08 |
| Культура | 1.09 | Отдых | 0.19 | Трудоустройство | 1.05 |
Таблица 1. Темы с максимальным средним значением маршрутных характеристик, собранные по доменам.
Как видно, некоторые из тем попадают на первое место естественным образом, если рассматриваются с точки зрения особенностей маршрута. К примеру, пользователь, изучающий веб-сайт по продаже машин, не может знать заранее, какой именно автомобиль он ищет. Пользователи так же зачастую исследуют несколько страниц, посвящённых разным местам отдыха, чтобы узнать побольше возможностей. Подобные наблюдения можно так же вывести и для характеристик глубины, ширины и шагов. Наибольшее число удовлетворительных шагов достигается темами «Общество», «СМИ» и «Наука», контент которых состоит, в основном, из статей для внимательного ознакомления. Помимо результатов из Таблицы 1, мы так же показываем некоторые закономерности в конце списка тем. Среди тем с маленьким количеством удовлетворительных шагов встречаются «Частная жизнь» и «Автомобили», при довольно высоком общем числе шагов в каждой из тем. Несмотря на большое количество посещений, пользователи не любят оставаться надолго на страницах доменов данных тем. Эти результаты свидетельствуют о том, что характеристики маршрутов могут содержать полезную информацию для поисковых систем, а также для компаний, занимающихся продвижением сайтов на поиске. Далее мы опишем методы оценки характеристик маршрута и их применение в информационном поиске.
При оценке характеристик маршрута мы полагаемся на крупную выборку пользовательских запросов, случайным образом отобранную из логов крупной поисковой системы. Выданный крупнейшими поисковыми системами топ документов по каждому запросу был передан экспертам для присуждения каждому документу точной оценки по шкале «идеально», «превосходно», «хорошо», «неплохо» и «плохо». В общем выборка содержала 50 тыс. запросов и 1,5 млн. оценённых пар запрос-документ. По всем оценкам мы обучили в качестве модели ранжирования градиентные древа решений Фридмана. Затем мы сравнили производительность предложенных характеристик с производительностью набора основных характеристик (Basic): вариант оценки BM25, PageRank и CTR, собранных на уровнях документа и домена и 7 модификаций продолжительности визита, рассмотренные в [1, Таблица 4.1]: Время-На-Странице — Время-На-Домене и Средняя-Продолжительность-Визита — Доменное-Отклонение. Этот набор основных характеристик достаточно эффективен, прост для понимания и включает в себя широкий ряд уже известных характеристик на основе продолжительности визита.
| Запрос | Основной набор | Основной набор + домен-агрегация | Основной набор + домен-агрегация | Основной набор + url-агрегация | Основной набор + url-агрегация |
| все | 55.77% | 57.95% | +0.66% | 58.05% | +0.82% |
| из 1 слова | 67.62% | 67.78% | +0.23% | 67.47% | -0.21% |
| из 2 слов | 64.72% | 64.89% | +0.27% | 64.91% | +0.29% |
| из 3 слов | 59.08% | 59.63% | +0.93% | 59.48% | +0.67% |
| более 4 слов | 50.15% | 50.75% | +1.2% | 50.92% | +1.54% |
| популярные | 55.91% | 67.16% | +0.36% | 67.11% | +0.30% |
| непопулярные | 49.88% | 50.34% | +0.91% | 50.55% | +1.33% |
Таблица 2. Оценки NDCG@10, полученные основной моделью, использующей характеристики URL-агрегации и домен-агрегации. Составляющие 45.18% выборки запросы с частотой более 10 в неделю считаются популярными. Отличия, выделенные жирным статистически значимы при степени уверенности в 0.99%.
Мы разделили все запросы в выборке на две равные части, первая из которых предназначалась для обучения моделей, а вторая – для оценки. В Таблице 2 показана производительность трёх моделей, обученных с использованием: (1) основного набора характеристик, (2) основного набора и домен-агрегации и (3) основного набора и URL-агрегации. Характеристики и доменной и URL-агрегаций демонстрируют свою полезность на тестовой выборке. Модель, обученная на основном наборе характеристик без 7 модификаций продолжительности визита получила оценку на уровне NDCG@5 = 55.9%. Следовательно, URL-характеристики поисковых маршрутов дают 0.82% прироста в дополнение к 2.9%, полученным от характеристик продолжительности визита. Мы так же измерили производительность всех трёх моделей на различных классах запросов отдельно. Мы обнаружили, что характеристики поисковых маршрутов ещё более полезны для длинных и редких запросов. Это объясняется следующим: будучи собранными на уровнях документов и доменов наши характеристики передают важную информацию о пользовательском поведении даже в сложных ситуациях, где основные характеристики пользовательского поведения не так информативны. Для подтверждения этого предположения мы разбили всех запросы в тестовой выборке на 4 почти равных части, соответствующих разным уровням доступности данных о поисковом маршруте среди маршрутов, имеющих как минимум 2 шага, инициированных данным запросом. Полученные результаты в Таблице 3 показывают, что характеристики маршрутов становятся ещё более ценны для запросов с нехваткой поисковых маршрутов. В Таблице 4 мы собрали топ-10 характеристик в соответствии с их вкладом, который измеряется как взвешенное улучшение функции потери по всем использованиям характеристики в процессе обучения. Характеристики поисковых маршрутов выделены курсивом.
| Запрос | Основной набор | Основной набор + домен-агрегация | Основной набор + домен-агрегация | Основной набор + url-агрегация | Основной набор + url-агрегация |
| Блок 1 | 44.11% | 44.60% | +1.1% | 44.98% | +1.97% |
| Блок 2 | 59.61% | 60.01% | +0.67% | 59.85% | +0.39% |
| Блок 3 | 65.84% | 66.12% | +0.42% | 66.09% | +0.37% |
| Блок 4 | 67.01% | 67.34% | +0.49% | 67.31% | +0.45% |
Таблица 3. Оценки NDCG@10, полученные на 4 различных уровнях доступности данных от блока 1 (наименьшая доступность) до блока 4 (максимальная доступность).
| # | Основной набор + домен-агрегация | Основной набор + домен-агрегация | Основной набор + url-агрегация | Основной набор + url-агрегация |
| 1 | QueryDomCTR | 20.2 | QueryDomCTR | 21.7 |
| 2 | BM25 | 17.7 | BM25 | 20.2 |
| 3 | QueryUrlCTR | 14.2 | QueryUrlCTR | 13.1 |
| 4 | QDwellTimeDev | 11.0 | QDwellTimeDev | 10.9 |
| 5 | PageRank | 5.2 | AvSatSteps | 5.1 |
| 6 | AvSatSteps | 2.5 | PageRank | 4.7 |
| 7 | AvDwellTime | 2.2 | TimeOnDomain | 2.6 |
| 8 | DwellTimeDev | 1.7 | CumulativeDev | 1.8 |
| 9 | 90thDwellTime | 1.4 | 90thDwellTime | 1.7 |
| 10 | 10thDwellTime | 1.3 | AvDwellTime | 1.7 |
Таблица 4. Топ-10 характеристик, упорядоченных по их вкладу.
Мы провели крупномасштабное исследование пост-кликовых поисковых маршрутов и их ценности для информационного поиска. Нами был рассмотрено множество характеристик маршрутов в качестве потенциального источника информации о пользовательском поведении после клика на странице выдачи результатов. Подробное изучение доказало значительную ценность характеристик поискового маршрута для основной модели информационного поиска. Насколько нам известно, большинство характеристик поискового маршрута ранее не оценивались IR-метриками. Мы считаем, что дальнейший углублённый анализ поисковых маршрутов, включая исследование новых характеристик и различных способов их агрегации может ещё больше помочь улучшению существующих моделей поиска по сравнению с уже используемыми свойства пользовательского поведения.
Материал «Through the Looking Glass: utilizing Rich Post-search Trail Statistics for Web Search» перевел Роман Мурашов
Полезная информация по продвижению сайтов:
Перейти ко всей информации