SEO-Константа
Яндекс.Директ + оптимизация
Алгоритм гиперссылочного ранжирования Google PageRank является популярным методом упорядочивания интернет-страниц, назначающий значение «авторитетности» вне зависимости от запроса и интересов самого пользователя. Расширения же Google PageRank, чувствительные к запросу и пользовательским предпочтениям, которые используют базисный набор смещенных векторов PageRank, были предложены с той целью, чтобы персонализировать функцию ранжирования наиболее гибким, разрешимым способом. Мы аналитически сравнили три последних подхода к персонализации Google PageRank и обсудили компромиссы каждого из них.
В этом разделе мы даем определение классическому алгоритму ранжирования Google PageRank [7], а также вводим те обозначения, которые будем использовать в дальнейшем. В основе определения Google PageRank лежит следующее важное предположение. Ссылку со страницы u ∈ Web на страницу v ∈ Web можно рассматривать как доказательство того, что v является «авторитетным» документом, чем очень часто злоупотребляется при продвижении сайтов. В частности, в количественном выражении, значение авторитетности, которое присуждается странице v от u, пропорционально авторитетности u и обратно пропорционально числу страниц, на которые ссылается документ u. Поскольку сама авторитетность странички u не известна, определение авторитетности для каждой страницы i ∈ Web требует итеративного вычисления до достижения точки конвергенции, когда вся система приходит в состояние равновесия. Мы опишем эквивалентную формулировку относительно случайного блуждания по ориентированному веб-графу G. Пусть u → v обозначает наличие ребра от u к странице v на графе G. Пускай deg(u) будет полустепенью исхода страницы u на G. Рассмотрим случайного пользователя (серфера), который посещает страницу u в заданный момент времени k. На следующем временном шаге серфер равномерно выбирает случайный узел vi из числа соседних исходящих ссылок с u{v|u → v}. Другими словами, в момент времени k + 1, пользователь переходит на узел vi ∈ {v|u→ v} с вероятностью 1/deg(u). PageRank (голосующая способность) страницы i определяется как вероятность того, что на том или ином временном шаге k>K наш серфер находится на странице i. При достаточно большом К и с незначительными изменениями в модели случайного блуждания эта вероятность является уникальной, и может быть проиллюстрирована следующим образом. Рассмотрим цепь Маркова, индуцированную случайным блужданием по графу G, где состояния системы задаются узлами на G, а стохастическая матрица переходных вероятностей, описывающая переход от i к странице j, задается как Р с Pij = 1/deg(i). Если Р – апериодическая и неразложимая матрица, то Эргодическая Теорема гарантирует нам то, что стационарное распределение случайного блуждания уникальное [6]. В контексте вычисления PageRank, стандартный способ гарантирует, что P является неразложимой матрицей, и, добавляя новое множество завершенных исходящих переходов с малыми вероятностями переходов ко всем узлам, создает полный (и, таким образом апериодический и сильно связанный) граф переходов 1. Пусть Е будет nxn одноранговой строчечной стохастической матрицей E = evT, где e является n-вектором, все элементы которого ei = 1; v является n-вектором, все элементы которого неотрицательны, а их сумма равна 1. Определим новую неразложимую цепь Маркова AT следующим образом 2:
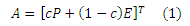
С точки зрения случайного блуждания, эффект E заключается в следующем. На каждом временном шаге с вероятностью (1−c) наш с вами серфер, который посещает любой узел, перейдет к случайной интернет-странице (вместо того чтобы следовать по исходящей гиперссылке). Положение случайного перехода выбирается в соответствии с распределением вероятностей, данном в v. Принятые здесь искусственные переходы E называются телепортацией. Если вектор v неоднородный, так что Е добавляет искусственные переходы с неоднородными вероятностями, то результирующий вектор PageRank может быть смещенным по отношению к определенного вида страницам. Именно по этой причине, мы ссылаемся на v как на персонализированный вектор.
Пусть n- число страниц в Глобальной паутине. Пусть x(v) обозначает n-мерный вектор персонализированного PageRank, который соответствует n-мерному вектору персонализации v. x(v) можно вычислить путем решения следующей задачи нахождения его собственных значений, где A = cPT + (1 − c)veT:
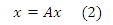
Переписав это уравнение следующим образом, видим, что:
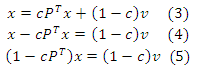
I−cP является матрицей со строгим диагональным преобладанием, так что она обратимая. Поэтому (I − cP)T = I − cPT также обратимо. Таким образом, получаем, что:
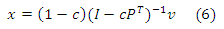
Пусть Q = (1−c)(I −cPT)−1. Пусть v = ei, где ei является і-м элементарным вектором 3. Мы видим, что і-й столбец матрицы Q равняется x(ei), т. е. вектор персонализированного PageRank соответствует вектору персонализации ei. Столбцы охватывают полный базис для векторов персонализированного PageRank, поскольку любой вектор персонализированного PageRank может быть выражен в виде выпуклой комбинации столбцов Q. Для любого вектора персонализации v, соответствующий вектор персонализированного PageRank задается Qv. Эта формулировка соответствует оригинальному подходу персонализации Google PageRank, предложенному Пейджем и соавторами в работе [7], что позволяет персонализировать произвольные множества страниц. К сожалению, первый подход, который использует полный базис для персонализированного PageRank недопустим на практике. Вычисление плотной матрицы Q в оффлайновом режиме непрактично, поскольку вычисление x(v) во время выполнения запроса использует Степенной метод. Тем не менее, здесь мы можем вычислить низкоранговые аппроксимации Q, обозначенные как Q’, которые позволяют принести нам некоторую выгоду при вычислении полностью персонализированногоPageRank. Вместо того чтобы использовать полный базис (т.е. столбцы Q), мы можем использовать на свое усмотрение редуцированный базис, например, с использованием только k ≤ n векторов персонализированногоPageRank, каждый из которых представляет собой столбец (или, в общем, выпуклую комбинацию столбцов) матрицы Q. В этом случае, мы не можем выразить все вектора персонализированного PageRank, а только те, которые соответствуют выпуклым комбинациям векторов PageRank по множеству редуцированного базиса:
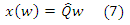
,где w — стохастический k-вектор, представляющий веса по k базисным векторам. Каждый из следующих трех подходов аппроксимируют матрицу Q с некоторой аппроксимацией Q’, хотя они существенно различаются как по своим вычислительным требованиям, так и по степени достижения детализации, относительно самой персонализации.
Topic-Sensitive PageRank. Схема Тематического PageRank, предложенная Хавеливала [2], вычисляет nxk аппроксимацию к Q, используя k-тематик, например, если обратиться к древовидной структуре каталогов, то авторами работы было использовано 16 верхних тематических уровней Open Directory [1]. Колонка j в Q’ задается x(vj), где vj является плотным вектором, который построен с использованием тематического классификатора Tj; (vj)i представляет собой (нормализованную) степень принадлежности страницы i к теме j. Отметим, что в этой схеме каждый столбец Q’ должен быть сгенерирован независимо, так что набор k должен быть достаточно небольшого размера (например, k = 16). Эта схема использует довольно грубый базисный набор, что делает его более подходящим для модуляции рейтингов, основанных на теме запроса и его контексте, а не для построения действительно «персонализированной» выдачи, учитывающей предпочтения какого-либо конкретного пользователя. Использование качественного набора репрезентативных базисных тематик гарантирует, что аппроксимация Q’ будет полезной. В Тематическом PageRank, Q’ полностью генерируется в оффлайновом режиме. Выпуклые комбинации берутся во время исполнения запроса, используя его контекст, чтобы вычислить соответствующие веса темы. С точки зрения модели случайного серфера, эта схема ограничивает выбор на совершение операции телепортации таким образом, что случайный пользователь может телепортироваться к теме Tj с некоторой вероятностью wj, а затем переместиться на определенную страницу i с вероятностью (vj)i.
Modular PageRank. Методология Модульного PageRank, предложенная Йехом и Видомом [3], вычисляет матрицу nxk с помощью k колонок матрицы Q, соответствующих высокоранжируемым страницам. Кроме того что эта работа обеспечивает эффективную схему вычисления указанных k векторов, в которой частичные вектора вычисляются оффлайново, а затем составляются во время исполнения запроса, она позволяет получить на практике k ≥ 104. С точки зрения модели случайного серфера, эта схема ограничивает выбор на операцию телепортации таким образом, что случайный пользователь может телепортироваться к определенным страницам с высоким рейтингом, а не произвольно выбранным наборам интернет-документам. Прямое сравнение относительной детализации этого подхода и Тематического PageRank представляется достаточно затруднительной задачей; хотя в этом сценарии базисный набор векторов персонализированного PageRank гораздо больше и они должны образовываться из векторов персонализации v с нечётными ненулевыми элементами, соответствующих высокоранжируемым интернет-страницам. Однако больший размер базисного набора действительно учитывает более тонкую модуляцию рейтинга.
BlockRank. Алгоритм BlockRank, предложенный Камваром и соавт. [4], вычисляет матрицу nxk, соответствующую k «блокам». Например, в этой работе, каждый блок соответствует хосту, такому как www-db.stanford.edu или nlp.stanford.edu. В данной работе вычисляется матрица Q’, в которой колонки j соответствует x(vj), где vj представляет локальный PageRank страниц в блоке j. Алгоритм BlockRank имеет возможность использовать внутреннюю структуру сетевого блока для эффективного вычисления многих из указанных блок-ориентированных базисных векторов, так что получение на практике k ≥ 103 вполне допустимо. С точки зрения модели случайного серфера, эта схема ограничивает выбор на операцию телепортации таким образом, что случайный пользователь может телепортироваться к блоку Bj с вероятностью wj, а затем телепортироваться на определенную страницу i в блоке Bj с вероятностью (vj)i, а не на произвольные множества страниц. Опять же, прямое сравнение гранулярности описанного подхода с предыдущими двумя представляется затруднительным. Однако подход BlockRank допускает большое число базисных векторов без ограничения того, что соответствующие вектора персонализации будут получены из страниц с высоким рейтингом.
Эта статья основана на работе частично поддержанной Национальным научным фондом по Гранту № IIS-0085896 и Гранту № CCR-9971010, а частично в ходе научно-исследовательского сотрудничества, возникшего между NTT Communication Science Laboratories, Nippon Telegraph и Telephone Corporation и CSLI. Исследовательский проект Стэндфордского университета «Concept Bases for Lexical Acquisition and Intelligently Reasoning with Meaning».
Перевод материала «An Analytical Comparison of Approaches to Personalizing PageRank» выполнил Сергей Неиленко
Полезная информация по продвижению сайтов:
Перейти ко всей информации