SEO-Константа
Яндекс.Директ + оптимизация
Растущая важность поисковых систем для коммерческих веб-сайтов породила такое явления, которое сегодня называется поисковым спамом, целью которого является перенаправление пользователей на определённые веб-сайты. Поисковый спам – неприятность, как для поисковых систем, так и для рядовых пользователей: людям требуется больше времени для поиска по-настоящему релевантной информации, а системам требуется больше вычислительной мощности для обработки разрастающегося корпуса данных, что, в свою, очередь увеличивает затраты на обработку каждого запроса. Как следствие, поисковые системы стараются всеми силами исключать спамовые страницы из их индекса.
Мы предполагаем, что некоторые спамерские страницы можно идентифицировать путём статистического анализа: определённые классы спамовых страниц, в частности, автоматически сгенерированные роботами, сильно отличаются по своим характеристикам от нормальных веб-страниц. Мы изучили вариативность данных свойств, включая ссылочную структуру, содержание страницы и её историю развития (эволюцию), в результате чего обнаружили отклонения в статистическом распределении этих особенностей, с высокой точностью характеризующие ресурс как спамовый.
В данной работе описаны все исследованные свойства, даны статистические распределения и показаны различия с нормальными веб-страницами, которые сильно коррелируют с поисковым спамом.
Системы информационного поиска занимают важную роль в онлайн-жизни пользователей: большинство людей перестали пользоваться своими закладками и вместо этого полагаются на такие поисковики как Google, Yahoo! и MSN Search (с 2009 года Bing — прим. пер.) для быстрого доступа к требуемому контенту. Как следствие, коммерческие веб-сайты вошли в ещё большую зависимость от своих позиций в поисковой выдаче, чем это было раньше. Фактически, высокие позиции (наличие сайта в топ-10) в выдаче популярных поисковых систем являются определяющим фактором коммерческого успеха веб-сайта.
По этой причине развилась структура SEO-специалистов (англ. SEO – search engine optimization, оптимизация под поисковые системы), работающих с сайтами в Интернете. SEO-компании предлагают коммерческим веб-сайтам свои услуги, так как обладают необходимыми знаниями о специфике работы поисковых систем. Таким образом для успешного продвижения бизнеса в Сети, получения высокого числа посетителей и заказов, множество фирм ищет тех, кто оказывает услуги по продвижению сайтов в регионах или в масштабах целой страны.
Зачастую, SEO-специалисты помогают веб-дизайнерам в создании хорошо структурированного тематического контента, корректным образом обогащая его ключевыми словами (т.е. определяя границы релевантности поисковым запросам). К сожалению, некоторые из них пытаются не только создать релевантные страницы, но так же и «накрутить» рейтинги веб-сайта, перегружая страницы ключевыми фразами вне зависимости от их реальной релевантности. На сегодняшний день такие попытки обмана поисковой системы легко вычисляются и по отношению к недобросовестным сайтам применяются санкции. Как следствие, SEO-оптимизаторы идут дальше: вместо перегрузки страницы ключевыми фразами ими создаётся множество страниц узкой направленности, которые привлекают посетителей, а далее консолидируют трафик на целевые ресурсы через гиперссылки. К тому же, ими преследуется и цель увеличения PageRank [11] целевой страницы: каждая из динамически созданных страничек имеет определённое минимальное значение PageRank, которое она отдаёт для одобрения другой страницы. Множество мелких одобрений способствуют росту PageRank продвигаемой страницы. Поисковые системы стараются противодействовать подобным способам накрутки, ограничивая число веб-страниц на отдельно взятом сайте, которые может обработать краулер во время индексирования. В качестве ответной меры, SEO-оптимизаторы подменяют DNS-сервера, которые изменяют имена хостов внутри домена (и обычно привязывают их к единственному IP-адресу).
Подавляющее большинство SEO-страниц существуют исключительно для манипулирования поисковой выдачей и перенаправления трафика на «оптимизированные» сайты. Другими словами, SEO-страницы работают на роботов поисковиков и чаще всего абсолютно бесполезны для посетителей-людей. В дальнейшем мы будем использовать термин «спам-страницы» для обозначения таких документов. Поисковые системы имеют приоритетную цель фильтрации спам-страниц для улучшения эффективности своей работы. В данной статье описывается ряд способов детекции поискового спама.
В предыдущих работах мы собрали широкую статистическую базу веб-страниц. В первой работе [5] мы обработали 429 миллионов HTML-страниц и сохранили данные обо всех содержащихся в них гиперссылках. Во второй работе [8] мы многократно обрабатывали 150 миллионов HTML-страниц в неделю в течение 11 недель и создали вектор характеристик для каждой из них, что позволило оценить тенденцию к изменению и частоту обновления каждой страницы, наряду с несколькими другими особенностями. В данной работе мы рассчитали статистические распределения для ряда свойств в полученной базе данных. Нами было обнаружено, что в части рассчитанных распределений находится чёткая корреляция с поисковым спамом. Как следствие, мы предположили, что статистический анализ является хорошим способом идентификации определённого вида спам-страниц (в частности, автоматически сгенерированных). Возможность идентификации большого числа веб-страниц в масштабах веба особенно важна для поисковых систем не только из-за исключения их из корпуса, но так же и для создания обучающей выборки для алгоритмов машинного обучения, нацеленных на идентификацию дополнительных спам-страниц.
Наше исследование основано на коллекции документов из экспериментов [5, 8]. Первая выборка (DS1) включает в себя еженедельный повторный краулинг 150 миллионов веб-страниц в течение 11 недель с ноября 2002 по февраль 2003. Каждая скачанная страница имеля код HTTP-статуса, дату скачивания, размер документа, число неизменяющихся слов в теле документа, проверочную сумму страницы (checksum) и shingle-вектор (вектор характеристики, позволяющий определить объём обновлённого контента от сеанса к сеансу). Кроме того, мы сохранили целиком текстовые данные 0.1% всех скачанных страниц, выбранных на основе хэша URL. Ручная обработка 751 страницы из выборки сохранённых страниц показала, что 61 из них является спам-страницей, что определило распространённость в 8.1% спам-страниц в данной выборке с шагом уверенности в 1.95% при 95% точности определения.
Вторая выборка (DS2) является результатом однократного сеанса краулинга. Он проводился с июля по сентябрь 2002, начиная со стартовой страницы Yahoo! и охватывает 429 миллионов HTML-страниц и 38 миллионов HTTP-редиректов. Для каждой скачанной страницы мы сохранили её URL и все URL гиперссылок в теле документа. Для каждого HTTP-редиректа мы сохранили как источник, так и целевую URL перенаправления. Средняя HTML-страница содержала 62.55 ссылок, при медианном числе ссылок на страницу в 23 штуки. Если принимать в расчёт только точные ссылки на странице, то среднее число ссылок 42.74, а медианное – 17. К сожалению, мы не сохранили все текстовые данные скачанных страниц. Для количественной оценки распространённости спама мы проверяли настоящие версии страниц случайной выборки в 1000 URL из DS2. Среди этих страниц 465 не могли быть скачаны или не содержали текстовых данных. Из оставшихся 535 страниц 37 (6.9%) являлись спамовыми.
Ссылочный спам является частным случаем поискового спама, когда недобросовестные SEO-специалисты пытаются накрутить знчение PageRank страницы p, создавая множество страниц-рефералов. Так как значение PageRank страницы p является функцией как от числа одобряющих страниц, так и от их качества и, принимая во внимание тот факт, что чёрные SEO-оптимизаторы не контролируют большого числа качественных страниц, можно провести параллель между соотношением числа высоко- и низкокачественных страниц-рефералов.
Можно ожидать, что URL автоматически сгенерированных страниц будут отличаться от созданных людьми. Например, в них будет больше цифр, знаков и бессмысленных наборов букв. Однако, когда мы изучили выборку DS2 с целью поиска спам-корреляций, подобные случаи не были обнаружены.
Но мы обнаружили несколько свойств компонентов хостов URL, которые могут помочь в обнаружении спама. В частности, выяснилось, что длинные имена хостов с большим количеством символов, точек, дефисов и цифр зачастую являются спамовыми. 80 из 100 самых длинных имён обнаруженных хостов соответствовали специфическим сайтам для взрослой аудитории, из которых 11 имели коммерческую основу. На рисунке 1 показано распределение длин имён хостов. На оси абсцисс показан рост символьной длины, на оси ординат – количество экземпляров в выборке DS2.
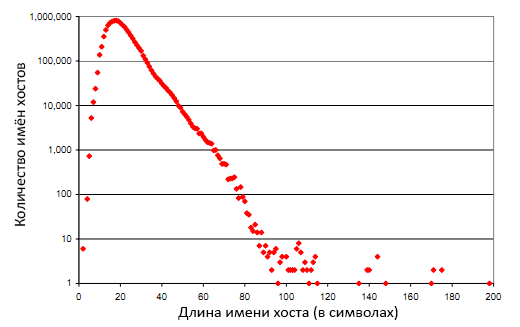
Рисунок 1. Распределение символьной длины имён хостов.
Одним из распространённых мнений в сообществе SEO является утверждение, что поисковые системы (в частности, Google) при получении запроса q будут выше ранжировать целевую URL u если в компоненте хоста содержится q. SEO-специалисты стараются использовать эту особенность, раскручивая страницы, содержащие в URL популярные запросы, релевантные их бизнесу, а затем настраивая DNS-сервера для обработки имён хостов. Настройка относительно проста, так как DNS-сервера могут быть сконфигурированы для обработки имён хостов в любом домене с эквивалентным IP-адресом. Например, на момент написания этой работы домен highriskmortgage.com относится к IP-адрему 65.83.94.42 (прим. пер. — на 2013 год IP 64.95.64.218).
Так как спамеры обычно генерируют большое число имён хостов, можно вычислить эту технологию спама путём определения числа хостов, относящихся к одному и тому же IP-адресу (или сети IP-адресов). На рисунке 2 показано распределение имён хостов по IP-адресам. На оси абсцисс показано, сколько хостов в норме привязывается к одному IP-адресу, а на оси ординат – число IP-адресов. Точка с координатами (x,y) показывает, что существует y IP-адресов с такой характеристикой, что каждый IP-адрес относится к x хостам. 1 864 807 IP-адресов в DS2 относятся к единственному имени хоста, 599 632 к двум, 1 IP-адрес относится к 8 967 154 именам хостов (правая крайняя точка). 3.46% страниц в DS2 обслуживаются с IP-адресов, которые привязаны к 10000 разных символьных имён хостов. Выборочная проверка этих URL показала, что они в подавляющем большинстве являются спам-страницами.
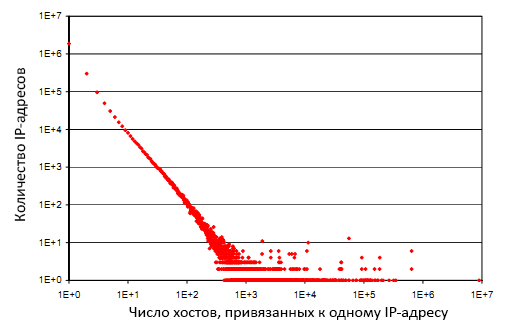
Рисунок 2. Распределение числа разных хостов, соответствующих одному и тому же IP-адресу.
Применяя аналогичную методику к DS1, 2.92% из всех страниц были маркированы как потенциально спамовые. Ручная проверка 250 страниц показала, что 167 (66.8%) были спамовыми, 64 (25.6%) ложно определёнными, а 19 (7.6%) – были отнесены к спаму из-за сообщений об ошибках (404, и т.д.), несмотря на то, что код статуса HTTP был 200 (OK).
Стоит отметить, что данная метрика маркирует спамовыми страницами в 20 раз больше URL по сравнению с метрикой, основанной только на именах хостов.
Следующим мнением в сообществе SEO является то, что Google PageRank передаёт больше веса по исходящим ссылкам (логично, что одобрение внешнего ресурса важнее самоодобрения) и страница приобретает больший вес, если ссылается на различные веб-сайты (такие страницы считаются «хабами»). Многие SEO-оптимизаторы стараются сыграть на этом, раскручивая страницы с реферальными ссылками на множество других хостов, но обычно всех хосты относятся к одному или нескольким различным IP-адресам.
Эта схема выявляется расчётом среднего отношения хоста-машины веб-сайта. Мы определяем это отношение как размер выборки имён хостов, на которые ссылается набор ссылок самой страницы, поделённый на размер выборки отдельных машин, к которым относятся хосты (предполагается, что два имени хоста относятся к разным машинам, если они соответствуют неидентичным наборам IP-адресов). Соотношение хостов-машин отдельной машины определяется как среднее отношение хостов-машин всех страниц, обслуживаемых данной машиной. Если отношение имеет высокое значение, то большая часть страниц, обслуживаемых данной машиной, ссылаются на множество различных веб-сайтов (т.е. имеют непотистские ссылки), но на самом деле выдают одобрение одной и той же цели. Другими словами, машины с высоким значением отношения хостов-машин с высокой вероятностью являются спам-сайтами.
На рисунке 3 показаны отношения хостов-машин всех машин в выборке DS2. На оси абсцисс показано само отношение, а на оси ординат – число страниц, обслуживаемых данной машиной. Каждой точке соответствует одна машина; точка с координатами (x,y) показывает, что в DS2 содержится y страниц от данной машины, и что среднее отношение хостов-машин равно x. Мы обнаружили, что если отношение хостов-машин превышает 5, то, скорее всего, машина является спамовой. 1.69% от всех страниц в DS2 соответствуют этому критерию.
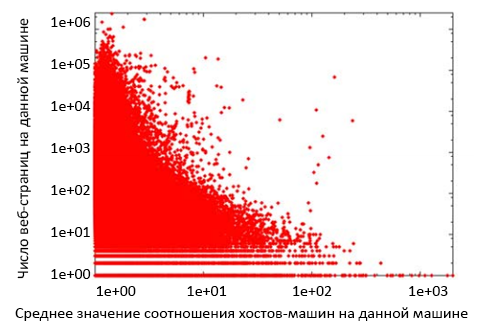
Рисунок 3. Распределение соотношений «хостов-машин» по всем ссылкам на странице, усреднённое по всем страницам веб-сайта.
Веб-страницы, связанные гиперссылками формируют структуру под названием «граф». Пользуясь терминологией теории графов, полустепень исхода веб-страницы эквивалентна числу гиперссылок в её теле (т.е. исходящих), а полустепень захода – числу входящих ссылок.
Рисунок 4. Распределение полустепеней исхода.
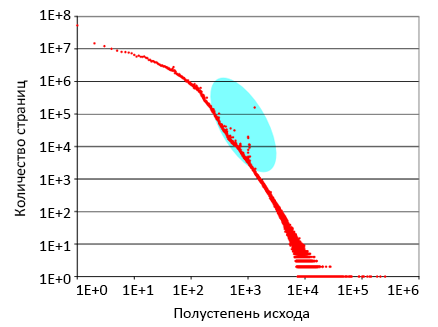
Рисунок 4. Распределение полустепеней исхода.
На рисунке 4 показано распределение полустепеней исхода. На оси абсцисс отображена полустепень исхода; на оси ординат – число страниц в выборке DS2 с данной полустепенью исхода. Обе оси откладываются по логарифмической шкале. 53.7 миллиона страниц в DS2 с нулевой полустепенью исхода не включены в граф. Как видно на рисунке, граф линеен в широком диапазоне, выполняя закон распределения Ципфа. Голубой овал выделяет элементы графа, демонстрирующие девиантное поведение. К примеру, существует 158290 страниц с полсутепенью исхода равной 1301; однако в соответствии с графиком распределения полустепеней исхода ожидается около 1700 страниц с таким значением. В целом, только 0.05% страниц в DS2 имеют полустепень исхода троекратно превосходящую нормальные значения по распределению Ципфа. Мы изучили эти страницы и, фактически, все они оказались спамовыми.
На рисунке 5 показано распределение полустепеней захода. Как и на рисунке 4, ось абсцисс показывает полустепень захода страницы, а ось ординат – число веб-страниц в DS2, обе оси отложены по логарифмической шкале. Данный граф имеет линейный характер распределения в более обширном диапазоне, чем предыдущий, и точнее соответствует закону Ципфа. Однако здесь наблюдается и большее число экземпляров, выбивающихся из общей картины. Например, в DS2 существует 369457 веб-страниц с полустепенью захода равной 1001, но по результатам распределения следует ожидать только 2000 таких страниц. Таким образом, 0.19% страниц в DS2 имеют троекратное отличие от нормальных значений по закону Ципфа. В процессе изучения этих страниц, так же было обнаружено, что они являются спамовыми.
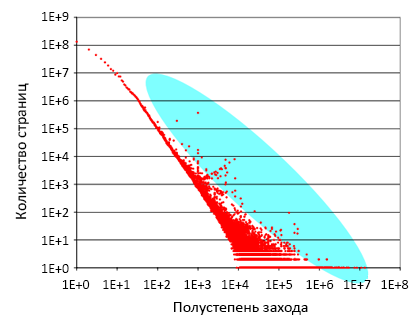
Рисунок 5. Распределение полустепеней захода.
Как упоминалось ранее, SEO-оптимизаторы зачастую используют метод накрутки через настройку веб-серверов для непрерывной генерации веб-страниц на лету с целью создания ссылочного спама или перегрузки ключевыми словами. В результате подобные сервера создают бесконечный Веб – они динамически создают страницы по любым запросам, возвращая ссылки на них в выдаче. Опытный SEO-манипулятор будет создавать страницы с определёнными изменениями, однако таких случаев немного. Как следствие, автоматически сгенерированные страницы легко отличить от других по их броской шаблонности. В частности, можно легко обнаружить десятки спамерских веб-сайтов, генерирующих страницы с одинаковым числом слов в теле документа.
В данных DS1 записано число неизменных слов в каждой скачанной HTML-странице. На рисунке 6 показаны различия в количестве слов на всех веб-страницах с данным именем хоста. При построении графика были исключены хосты с нулевым средним значением количества слов на страницах. На оси абсции показана вариативность количества слов, а на оси ординат отображается число страниц в DS1, скачанных с данного хоста. Обе оси откладываются по логарифмической шкале. Голубым прямоугольником отмечены веб-сервера, имеющие как минимум 10 страниц с одинаковым числом слов. В DS1 находится 944 таких хоста, под обслуживанием которых 323454 страниц (0.21% от всех страниц). Случайным образом отобрав 200 страниц и обработав данные вручную, выяснилось, что 55% из них являются спамовыми, 3.5% не содержат текстовой информации, а 41.5% выдают ошибк доступа.
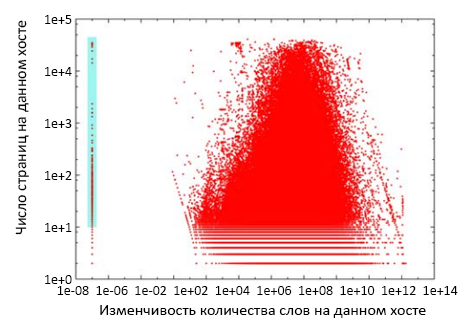
Рисунок 6. Вариативность числа слов на всех страницах, обслуживаемых хостом.
Некоторые динамические спам-сайты создают страницы для запрошенного URL без использования самого URL в генерации. Эта методика спама может быть обнаружена при помощи оценки эволюции как отдельных веб-страниц, так и целых сайтов. В целом, эволюция Веба протекает медленно: 65% всех страниц не меняются в течение недели и только 0.8% всех страниц меняются целиком [8]. На этом фоне легко заметить, что спамовые страницы, генерируемые в ответ на HTTP-запрос вне зависимости от запрошенного URL будут кардинально изменяться при каждой загрузке. Логично, что при поиске подобных спам-сайтов необходимо в первую очередь обратить внимание на сайты с высоким средним значением изменчивости веб-страниц.
На рисунке 7 показано среднее значение еженедельных изменений на всех веб-страницах данного сервера. На оси абсцисс показывается балл изменения страницы; 0 соответствует полному изменению, 85 характеризует отсутствие изменений. На оси ординат показана число пар успешных скачиваний с данного IP-адреса (изменения от недели 1 к неделе 2, от недели 2 к неделе 3, и т.д.). Элементы выборки представлены точками; каждой точке соответствует определённый IP-адрес. Голубым прямоугольником выделены IP-адреса, по которым почти все страницы кардинально изменялись еженедельно. В выборке присутствует 367 серверов с таким свойством, обслуживающих 1409353 страниц (0.93% от всех страниц в коллекции). Обработав 106 страниц из этой зоны, было обнаружено, что 103 (97.2%) из них являются спамовыми, 2 возвращают ошибку доступа, а 1 страница была наполнена взрослой тематикой, что квалифицируется как ложное срабатывание.
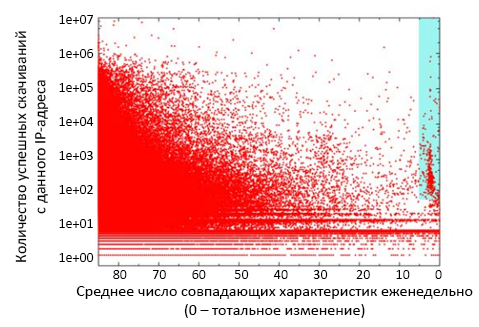
Рисунок 7. Среднее еженедельное изменение всех страниц, обслуживаемых данным IP-адресом.
Логично предположить, что подобный анализ отнесёт новостные сайты в категорию спама по причине частого обновления страниц. Однако среди полученных спамовых результатов не было ни одного новостного сайта. Это объясняется тем, что большинство новостных порталов имеют динамическую главную страницу, которая ссылается на постоянные веб-страницы с новостными статьями. Так как метод оценки в первую очередь анализирует среднее значение изменения на всех страницах сайта, новостные порталы не попадают «под горячую руку».
В разделе «Характеристики контента» было отмечено, что спам-сайты заполнены большим числом шаблонных страниц. В некоторых случаях страницы создаются при помощи включения различных ключевых фраз в шаблон. Зачастую, отличия на подобных страницах минимальны. Таким образом можно вычислять эту методику спама при помощи формирования кластера из очень похожих страниц и анализируя его алгоритмом шинглов Андрея Бродера [3]. Сам же алгоритм кластеризации описан в работе [9].
На рисунке 8 показано распределение размеров кластеров, содержащих почти идентичные страницы с дубликатами в DS1. На оси абсцисс располагается размер кластера (т.е. число веб-страниц, разбитых поклассово), а на оси ординат – число существующих кластеров такого размера в DS1. Обе оси откладываются по логарифмической шкале, на графике отражено распределение Ципфа.
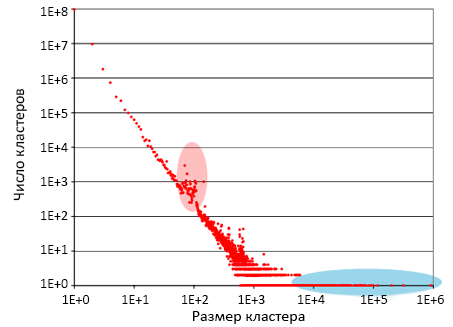
Рисунок 8. Распределение размеров кластеров почти одинаковых документов.
По результатам обработки было выявлено две группы элементов, выбивающихся из общего ряда. Изучение группы кластеров, маркированной красным овалом показало, что ни один из рассматриваемых сайтов не является спамовым: данные дубликаты появились в ходе естественного распространения информации по Сети (репосты, зеркала документации и т.д.). Однако в кластерах, отмеченных голубым овалом преобладали другие результаты: 15 из 20 крупнейших кластеров оказались спамовыми. В них содержалось 2080112 веб-страниц из выборки DS1 (1.38% от всей коллекции).
Henzinger et al. [10] определил, что веб-спам является приоритетной проблемой современных поисковых систем. Davison [7] проводил исследования по обнаружению непотистских ссылок, т.е. ссылочного спама. Amitay et al. [1] разработал техники идентификации ссылочного спама на основе пространства характеристик. В нашей же работе идёт фокусировка не столько на поиск наличия ссылочного спама, сколько на выявление самих спам-страниц.
Все наши методики основываются на внимательном поиске аномальных явлений в статистических данных краулинга. В нескольких работах уже проводились подобные исследования, однако их внимание было направлено на поиск общих тендеций, а не отклонений от нормы.
Broder et al. проводил исследований ссылочной структуры веб-графа [4]. Результаты его экспериментов наглядно показали, что распределения полустепеней исхода и захода выполняются по закону Ципфа. Broder упоминал, что отклонение от закона распределения может характеризовать спамовые секторы. Bharat et al. развил работу Broder углубившись в исследования не только ссылочной структуры между отдельными страницами, но так же и анализируя связи более высокого уровня: между сайтами и доменами верхнего уровня (доменные зоны) [2].
Cho и Garcia-Molina [6] изучили ряд страниц на 270 веб-серверах, которые изменялись ежедневно. Fetterly et al. [8] продолжил их дело, начав исследование объёма еженедельно изменяющийся информации на 150 миллионах страниц (часть наших результатов, описанных в данной работе основываются именно на собранной Fetterly коллекции). Наблюдения показали, что неожиданно высокие показатели изменчивости немецких веб-сайтов задаются, в основном, поисковым спамом.
Ранее мы использовали аналогичную коллекцию данных для изучения эволюции кластеров почти идентичного контента [9]. В ходе работы выяснилось, что самые большие кластеры соответствуют спамовым сайтам, каждый из которых работал с крупным числом страниц, имеющих минимальные отличия.
В данной работе был описан ряд методик по определению спам-страниц. Множество SEO-оптимизаторов пытаются раскрутить сайты своих клиентов именно такими способами, внедряя сотни веб-страниц в корпус поисковой системы. Например, подъём значения PageRank веб-страницы требует множества поощрений с внешних ресурсов. Единственным путём для быстрой накрутки значения PageRank является автоматическая генерация страниц с одобряющими ссылками.
Основная мысль исследования заключается в том, что автоматически сгенерированные веб-страницы значительно отличаются от созданных вручную. Одним из броских отличий является явная шаблонность страниц с низким или нулевым уровнем отличий между ними. Менее заметным отличием (и более существенным для оптимизаторов) является тот факт, что высокоранжируемые страницы по определению отличаются от прочих. Например, эффективный ссылочный спам требует высокой полустепени захода, а спам-техника по ключевым фразам – высокое содержание популярных запросов на самой странице.
В нашей работе были рассмотрены свойства, которые, по нашему мнению, являются адекватными индикаторами спам-страниц. В их число входят:
Мы опробовали все способы, которые не нуждаются в данных о ссылках (кроме техник по детекции девиантов в полустепенях захода и исхода и определении соотношения хостов-машин) на реальной коллекции данных DS1. Наши методики отнесли 7,475,007 веб-страниц в категорию потенциального спама на основе оценки как минимум одним способом (4.96% от всех страниц в DS1 из предположительно 8.1%+-2% настоящих спам-страниц). Ложные срабатывания, учитывая повтор результатов от разных алгоритмов, составляют 14% от полученного списка подозрительных кандидатов. Большая часть этих ошибок зависят от неточностей в обработке имён хостов. Судя по результатам в обработанной выборке DS2, методики, неприменимые к DS1 (так как в этой коллекции не используется ссылочная информация) могли бы обнаружить ещё 1.7% дополнительных спам-страниц в DS1.
В наши планы по дальнейшим исследованиям входит оценка качества работы наших техник в совокупности и по отдельности. Тесты будут проводиться на единой коллекции документов, которые содержат полный текст веб-страниц и все ссылки в теле. Более амбициозной целью является использование семантических техник для определения спама по наличию конкретных слов и словесных паттернов в теле веб-страницы.
Техники детекции поискового спама имеют критическую важность для поисковых систем. Они могут быть использованы в качестве фактора ранжирования, при планировании краулинга (методом исключения заведомо спамовых ресурсов), а так же (в экстремальных условиях) для исключения низкокачественного контента из поискового индекса. Использование данных техник позволяет поисковым системам формировать более релевантную выдачу, одновременно уменьшая размер индекса. Конкретнее, описанные методы могут применяться для создания крупной коллекции спам-страниц, которую, в свою очередь, можно использовать в обучении алгоритмов по детекции спама.
Перевод материала «Spam, Damn Spam, and Statistics: Using Statistical Analysis to Locate Spam Web Pages» выполнил Роман Мурашов
Полезная информация по продвижению сайтов:
Перейти ко всей информации