SEO-Константа
Яндекс.Директ + оптимизация
Прогнозирование CTR рекламных объявлений на странице с результатами поиска является важной темой. Причиной этого является то, что правильный выбор рекламы сильно влияет на доходы поисковой системы, а так же на удовлетворённость рекламодателей и пользователей. Для рекламных объявлений с большой историей кликов легко предсказать CTR, используя статистические данные. Но для новой рекламы с малой историей кликов такой подход неточен и ненадёжен. Мы предлагаем модель предсказания CTR для таких новых объявлений. В отличие от предыдущей модели предсказания CTR новой рекламы, наша модель использует события — клики и пропуски (здесь и далее пропуск означает, что клик не был совершён). В дополнение к этому мы ввели несколько инноваций, которые увеличили производительность нашей модели. Оффлайновые и онлайновые опыты на реальном движке поисковой системы показали, что наша модель качественно превосходит базисы и подходы, предлагаемые в предыдущих статьях.
Контекстная реклама является основным источником дохода для поисковых систем. Для компаний, владеющих поисковыми системами, важно выбирать рекламу правильно, поскольку это серьёзно влияет на доход и впечатления пользователей. Также, данного вида реклама является прямой альтернативой продвижению сайтов в органической выдаче, которое манипулирует алгоритмами ранжирования поисковых машин.
Существуют несколько видов онлайновой рекламы, однако в этой статье мы ограничимся самой распространённой моделью: оплата за клик. Это значит, что поисковая система получает деньги каждый раз, когда пользователь делает клик по рекламному блоку. Такая модель подразумевает, что поисковый движок выбирает рекламу с наибольшей предполагаемой доходностью — вероятностью клика (CTR), умноженной на цену-за-клик рекламы.
Существует два типа слотов спонсированной поисковой рекламы: блок рекламы, расположенный справа от результатов поиска, и блок, расположенный над результатами поиска. В этой статье мы будем рассматривать только «верхнюю» рекламу.
В случае с рекламой, имеющей большую историю кликов, вероятность клика может быть рассчитана напрямую из статистических данных. В случае новой рекламы с малой историей кликов такой подход неприемлем: эмпирические расчёты непостоянны и ненадёжны. Проблема может быть решена с использованием других свойств рекламных блоков: заголовок, текст, ссылка, ключевые слова, история кликов похожей рекламы и т.д. Отсюда будем представлять рекламу как комбинацию определённого типа с определённым ключевым словом.
Реджелсон (Regelson) и другие [1] решили проблему предсказания CTR новой рекламы следующим образом. Они разделили рекламу по текстовой cхожести ключевых слов в иерархию кластеров. Далее, для предсказания CTR рекламы они использовали средний CTR рекламы в том же кластере, а так же средний CTR кластеров-предков. Ричардсон (Richardson) и другие [2] предложили более сложный подход. Они вычисляли несколько типов свойств каждой рекламы: CTR фразы рекламы (здесь и далее «фраза рекламы» означает ключевые слова рекламы), CTR похожих фраз, свойства, описывающие внешний вид рекламы, CTR домена целевой страницы, релевантность текста рекламы по отношению к её фразе и др. Затем они брали набор реклам с имеющимся CTR (отображённые более 100 раз) и рассмотрели логистическую модель регрессии, используя перечисленные свойства. Их подход продемонстрировал высокую производительность в тесте с учётом средней квадратной ошибки и информационной дивергенции между рассматриваемым и предсказываемым CTR.
Проблемой вышеописанного опыта является то, что его модель была протестирована на рекламе с большой историей кликов. Но задача состоит в том, чтобы предсказать CTR новой рекламы. Это поднимает некоторые вопросы для рассмотрения: имеет ли новая реклама принципиальные отличия от рекламы, имеющей некую историю кликов (Вопрос 1)? Необходимо ли обучить модель, используя рекламу с большой историей кликов в качестве опытных образцов, после чего применить её к новой рекламе(Вопрос 2)? Как доказать, что обученная модель работает качественно (проблема в том, что мы не можем определить точность расчёта предсказаных CTR новой рекламы, потому что у них отсутствуют готовые (рассмотренные) значения CTR) (Вопрос 3)? Как изменить подход, предложенный Ричардсоном, так, чтобы при этом не повлиять на набор рекламы с большой историей (Вопрос 4)?
В этой статье мы продемонстрируем разницу между типичной новой рекламой и типичной рекламой с большой историей кликов (В1) и рассмотрим проблему, которую вызывает эта разница (В2). Затем мы опишем наш алгоритм, основанный на другой целевой функции — он предсказывает события (совершение или несовершение клика), вместо предсказывания CTR. Это изменение позволяет нам включить новую рекламу в тестовый набор (В4). Также мы рассмотрим некоторые из новых свойств рекламы, введённых нами. Далее мы опишем оффлайновые и онлайновые эксперименты (В3) с реальным поисковым движком, которые покажут, что наш алгоритм превосходит базовый и предложенный Ричардсоном. [2]
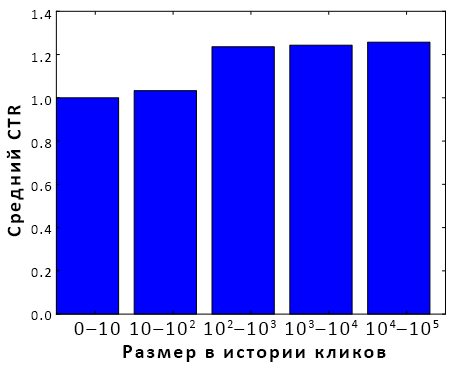
График 1: Зависимость CTR от размера истории кликов
Высокий CTR рекламы с большой историей кликов. Мы ввели алгоритм, сходный с алгоритмом, предложенным Ричардсоном, и провели онлайн-опыт. Полностью результаты приведены в разделе 4. Сейчас же мы сфокусируемся на одной его особенности: значения CTR новой рекламы, предсказываемые алгоритмом, были статистически выше, чем уже имеющиеся. В самом деле, и поисковая система и рекламодатели заинтересованы в длительном отображении рекламы с высоким CTR, чтобы бесполезная и спамерская реклама блокировалась или удалялась как можно скорее, или просто редко отображалась. Поэтому реклама с большой историей кликов в основном имеет высокий CTR. График 1 показывает разницу CTR между новой рекламой и рекламой с большой историей кликов. Алгоритм, который был обучен на рекламе с высоким CTR, скорее всего и будет предсказывать высокий CTR. Такая зависимость алгоритма может привести к серьёзной потере доходов: новая реклама получит значения CTR большие реальных. Как следствие, некоторые из хороших рекламных блоков, которые отображались успешно и раз за разом, будут заменены новой рекламой, которая фактически хуже. В итоге делается меньше кликов, чем могло быть, поисковая система зарабатывает меньше денег, рекламодатели привлекают меньше потенциальных клиентов, а пользователи оказываются неудовлетворенными.
Целевая функция. Ричардсон [2] использовал рекламу с готовым CTR (то есть с большой историей кликов) как объекты, для которых нам нужно сделать предсказания. Он использовал CTR такой рекламы как целевые значения. Такой подход имеет вышеназванные проблемы. Мы же предлагаем использовать представления рекламы как входные данные, а клики (и отсутствие кликов) как целевые значения. В общем случае, реклама может иметь несколько представлений, которые иногда кликаются, а иногда нет. Мы объединяем все такие случаи в два типа записей:
| Id объявления | значения | Weight1 | 1 |
| Id объявления | значения | Weight0 | 0 |
Где Weight1 — это количество совершённых кликов по рекламе, Weight0 — количество раз, когда реклама была показана, но не кликнута. Теперь мы можем обучить любой классифицирующий алгоритм, который учитывает вес тренировочных примеров и обеспечивает уверенный уровень предсказаний. Каждая новая реклама будет входным значением для алгоритма, а уровень уверенности, возвращаемый алгоритмом, является приблизительным значением CTR данной рекламы. Мы испробовали два классификатора: логистическая регрессия и стохастическое повышение градиента на регрессиионных деревьях. Последний показал более высокую производительность, поэтому мы использовали его во всех экспериментах, описанных далее.
Этот раздел описывает значения, использованные нами в реализации алгоритма Ричардсона и реализации нашего алгоритма. Ричардсон предлагал следующее:
Мы использовали всё указанное и обнаружили, что последние две группы значений не дают существенного прироста производительности, и поэтому не включили их в нашу реализацию алгоритма Ричардсона. Другие упомянутые выше значения были включены в набор значений нашей реализации алгоритма Ричардсона. Теперь мы опишем наши значения, не использовавшиеся Ричардсоном.
IDF слов в фразе. Ричардсон предлагал использовать количество слов в фразе рекламы при вычислениях. Это довольно сильный фактор: чем больше слов, тем выше CTR. Мы предлагаем брать в расчёт IDF (обратную частоту документов) слов в фразе. Кроме этого, мы предлагаем использовать ещё три значения: суммарную, производную и среднюю IDF ключевых слов. Таблица 1 демонстрирует высокую корреляцию CTR и суммарной IDF ключевых слов. Здесь и далее мы заменили реальные значения CTR их пропорциональными значениями из-за проприетарности информации такого рода.
| Сумма IDF слов | Среднее значение CTR |
| [0.0, 13.0] | 1.0000 |
| [13.0, 15.0] | 1.1282 |
| [15.0, 16.5] | 1.1273 |
| [16.5, 18.0] | 1.1697 |
| [18.0, 19.5] | 1.1986 |
| [19.5, 21.0] | 1.2058 |
| [21.0, 23.0] | 1.2491 |
| [23.0, 25.5] | 1.2554 |
| [25.5, ∞] | 1.2500 |
Таблица 1: зависимость CTR от суммарной IDF ключевых слов
Статистика правосторонней рекламы. Как мы упоминали выше, в этой статье мы предсказываем CTR новой рекламы, расположенной над результатами поиска. Иногда реклама имеет большую историю кликов располагаясь справа, но у её верхнего аналога история кликов может быть мала. Поэтому мы предлагаем использовать историю кликов правой стороны для введения новых трёх факторов: количество показов, количество кликов по рекламе справа и CTR рекламы справа. Наши вычисления показывают, что эти факторы имеют положительную корреляцию с CTR рекламы, но подробности мы опускаем из-за нехватки места.
Реклама, сходная по фразе и тексту. Ричардсон использовал средний CTR реклам, имевших одинаковые ключевые слова. Мы дополнительно взяли в расчёт рекламы, которые текстово похожи по заголовку и содержанию. Вычисление Ричардсона основано на количестве одинаковых слов в сравниваемых текстах. Наш метод аналогичен, но мы берём в расчёт IDF ключевых слов. Так мы использовали факторы, основанные на среднем CTR среди рекламы с одинаковыми ключевыми словами, названиями и содержимым. Такие факторы существенно улучшают качество нашей модели предсказания.
Прежде чем представить описание опытов, мы вкратце опишем схему предсказания CTR рекламы (любой, не только новой) в нашем поисковом движке. Модель предсказания основана на наборе факторов, и одним из сильнейших является эмпирический CTR со сглаженным независимым значением. Сейчас поисковый движок использует простой подход; заданное значение является линейной функцией двух значений: количество слов в фразе рекламы и уровень релевантности фразы рекламы к её тексту. В наших опытах, оффлайновых и онлайновых, мы использовали значение CTR, выдаваемое нашим алгоритмом заданное значение CTR рекламы. Формула сглаживания структурирована таким образом, что чем короче история кликов, тем сильнее эффект заданного значения. То есть, наибольшее улучшение произошло для рекламы с малой историей кликов; это будет продемонстрировано далее.
Оффлайн-опыты. Для наших испытаний мы использовали информацию их двух миллионов реклам, которые отображались более 250 раз. Этот набор был использован для вычисления значений, основанных на CTR подобных реклам. Затем мы собрали логи кликов за неделю из миллиона случайно выбранных реклам. Этот набор был использован в качестве опытного. Для каждой записи в тестовом наборе наш алгоритм обеспечивал значение — уверенность клика. Эти значения использовались как заданные значения CTR в схеме предсказания CTR, описанной выше.
Алгоритм предсказания обеспечивает вычисления CTR, то есть дробные числа, в то время как события, определяемые истинностью (совершённый или несовершённый клик), выдают двоичные значения: единицы и нули. Мы предлагаем два способа измерения точности предсказаний: средняя квадратная ошибка (mean squared error – MSE) и корреляция Пирсона (Pearson correlation – PC). Пусть {yi}Ni=1 – бинарная последовательность событий (клики и не клики), {wi}Ni=1 — соответствующий вес, то есть количество повторов данный событий в наборе, и ctrN — соответствующие предсказанные CTR. Тогда:
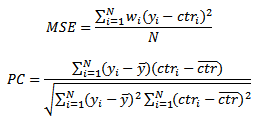
В экспериментах мы использовали корреляцию Пирсона как главный показатель производительности, поскольку мы эмпирически знаем, что это сильно коррелирует с доходностью нашей поисковой системы. В то же время корреляция Пирсона инварианта при линейных изменениях вводных значений, поэтому мы попытались максимизировать корреляцию Пирсона и нуждались в том, чтобы внедрение нашего алгоритма не повлекло увеличение MSE. Эти условия были выполнены во всех опытах, описываемых далее. Производительность каждой модели измерялась на четырёх подмножествах тестового набора. Первые три подмножества содержали рекламу с определёнными количествами показов: 10, 20 и 50. Последнее подмножество представлял полный тестовый набор.
Группы значений. Мы рассмотрели эффекты различных групп значений, описанных выше:
Мы последовательно, один за другим в порядке, указанном выше, добавили каждую из групп в наборы значений нашей модели. На каждом шаге модель обучалась. Изображение 2 демонстрирует эффект каждой группы значений, оказываемый на различные подмножества тестового набора.
Самой значительной является первая гистограмма, показывающая результаты работы для новой рекламы (10 или меньше показов в истории кликов). Каждая группа факторов увеличивает качество алгоритма. Фильтрование обучающего набора. Как было сказано в разделе 2, реклама с большой историей имеет больший CTR, чем новая. Поскольку наша задача предсказать CTR новой рекламы, мы пробовали разные методы фильтрования обучающего набора для улучшения производительности. Мы последовательно фильтровали рекламу, имеющую более 10, 20, 30, 50, 75, 100, 150, 200 показов. Качество тестового набора улучшилось на 5%. Здесь и далее мы заменяли реальные значения линейных корреляций пропорциональными значениями из-за проприетарности информации такого рода.
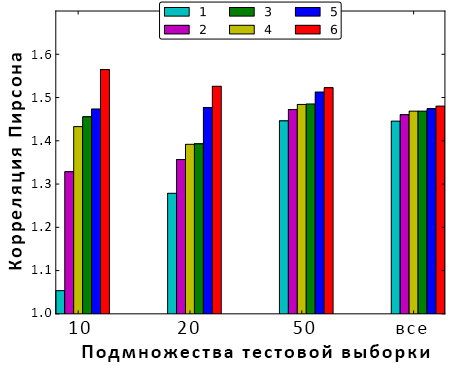
Изображение 2: результаты различных наборов значений на различных подмножествах тестового набора.
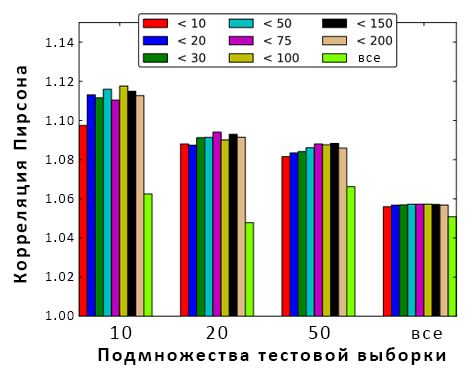
Изображение 3: результаты различных наборов значений на различных подмножествах тестового набора.
Онлайновые опыты. Мы сравнили качество предсказания кликов нашей модели с базовой моделью. Наша модель превзошла базовую. Результаты приведены в таблице 2. Этот эксперимент был проведён оффлайново с помощью поисковых логов. Оффлайновые эксперименты способны лишь измерить точность предсказаний, но они не могут вычислить глобальный эффект (например, общий CTR и среднюю цену-за-клик) реализации нового алгоритма. Поэтому мы провели онлайновый эксперимент как описано ниже.
Мы сравнили три модели предсказания описанные выше: оригинальная модель с заданным значением CTR, вычисляемое простым линейным подходом, модель с заданным значением, представленным нашим алгоритмом и модель, предлагаемая Ричардсоном. А точнее, мы произвели два опыта: в первом мы сравнили алгоритм Ричардсона с оригинальной моделью, а во втором сравнили наш алгоритм с оригинальным. Каждый опыт проводился по одной схеме. Для части поисковых запросов использовалась оригинальная формула, которая выбирала какую рекламу отобразить, для другой части запросов использовалась формула-конкурент. Мы сравнивали модели по общему среднему CTR. Результаты представлены в таблице 3. Наша модель продемонстрировала более высокую производительность. Таблица 4 предоставляет более детальный обзор эффекта нашей модели на новой рекламе. Мы разделили новую рекламу на две группы по числу показов и истории кликов. Для обеих групп мы наблюдали увеличение среднего CTR и уменьшение кликов-за-цену, последнее изменение обычно приветствуется рекламодателями.
| Фильтрация по количеству показов | MSE, % | Лин. кор., % |
| Без фильтрации | -0.291 | +1.503 |
| 0 — 10 | -2.165 | +25.274 |
| 11 — 20 | -1.953 | +15.030 |
| 21 — 50 | -0.826 | +4.081 |
| 51 — 100 | -0.134 | +0.818 |
| 101 — 200 | -0.125 | +0.221 |
| 201 — * | -0.162 | +0.318 |
Таблица 2. Оценка качества нашей предсказательной модели. Фиксируются улучшения по сравнению с базовой моделью на различных подмножествах тестовой выборки.
| Алгоритм | CTR |
| Ричардсона | 0.5% |
| Наш | 1.5% |
Таблица 3. Результаты онлайновых опытов. Фиксируются улучшения по сравнению с базовой моделью.
| История | CTR | Оплата за клик |
| 0 — 10 показов | +22.7% | -26.6% |
| 10 — 50 показов | +21.0% | -7.3% |
Таблица 4. Результаты онлайновых опытов для новых объявлений. Фиксируются улучшения по сравнению с базовой моделью.
Мы предложили алгоритм предсказания CTR новой рекламы с малой историей кликов. Алгоритм не зависит от рекламы с большой историей кликов и, следовательно, избегает переоценки CTR. Мы также ввели несколько новых значений и использовали их в своей модели. Оффлайновое и онлайновое тестирование показало, что наша модель превосходит базовую и предложенные в предыдущих статьях.
Перевод материала «Predicting CTR of New Ads via Click Prediction» выполнил Максим Евмещенко
Полезная информация по продвижению сайтов:
Перейти ко всей информации