SEO-Константа
Яндекс.Директ + оптимизация
Так как поисковые системы стараются улучшить и релевантность выдачи и уменьшить скорость своего отклика, они постоянно сталкиваются с растущими затратами на обслуживание автоматизированного (не-человеческого) трафика. Сторонние приложения взаимодействуют с системами информационного поиска по ряду причин, например, для отслеживания позиций сайта, имитации пользовательской активности и т.д. В данной работе мы исследуем автоматизированный (машинный) трафик в потоке запросов крупной поисковой системы. Мы определяем такой трафик как любой поисковый запрос, генерируемый в реальном времени не пользователем-человеком, а машиной. Для начала мы предоставляем примеры различных категорий логов запросов, сгенерированных ботами. Затем мы определяем различные характеристики, которые показывают различия между машинными и человеческими запросами. Далее мы классифицируем эти характеристики по двум категориям, относя их либо к интерпретации физической модели взаимодействия человека с поисковой системы, либо к поведенческим паттернам машинных взаимодействий. Мы считаем, что эти характеристики являются фундаментом для классификатора потока запросов.
Мировая Паутина очень быстро стала де факто основным источником и способом получения информации. Эта смена статуса позволила Интернету перевратиться в многомиллиардную долларовую индустрию в течение нескольких лет. Кроме того, повсеместное распространение Интернета так же превратило его в благоприятную среду для разнообразных исследований. Одним из таких исследований является информационный поиск. Важной задачей на сетевой арене является борьба с почтовым и ссылочным видами спама. Почтовый спам нацелен на то, чтобы заставить получателя приобретать определённые товары, покупка которых требует раскрытия банковских паролей и прочей конфиденциальной информации. Такой тип писем практически всегда является автоматизированным. В одном из исследований утверждалось, что 85% всего почтового спама, что составляет более половины всей корреспонденции, генерируется всего лишь шестью ботнетами.
Что касается ссылочного спама, генератор пытается манипулировать поисковой системой с целью повышения собственного ранга. К примеру, большое число автоматически сгенерированных веб-страниц могут использоваться для передачи ранг небольшому числу коммерческих сайтов [5].
В данной работе мы концентрируемся на неисследованном виде автоматизации поисковых запросов. Мы определяем «законные» запросы как те, что вручную вводятся пользователями для поиска информации. Весь прочий трафик считается автоматизированным. Машинный трафик является серьёзной проблемой, так как он подрывает эффективность работы поисковой системы. Так как поисковые системы доступны для публичного использования, существует множество автоматических систем, использующих их в своих целях. Бот – сущность, генерирующая автоматизированный трафик – может создавать запросы по ряду причин, большая часть которых безопасна, но и не приносит большого дохода.
В качестве примера, боты-определители позиций периодически проверяют веб-страницы для определения их ранжирования по паре «запрос-URL». Компании, специализирующиеся на поисковой оптимизации (SEO) и продвижении сайтов часто используют таких ботов для оценки позиций сайтов своих клиентов. Если позиции слишком низкие, то пользователю требуется генерировать множество запросов типа «следующая страница» чтобы найти свою цель в поисковой выдаче. Так как SEO-компании имеют множество клиентов, на практике такие действия выливаются в значительное количество трафика от пользователя с одним и тем же идентификатором. Как пример, рассмотрим пользователя на Рисунке 1. Данный бот подаёт запросы приблизительно каждые 7 секунд с полуночи до 6 утра, а затем с менее высокой частотой (примерно каждые 30 секунд) до конца дня. Общее число запросов составляет около 4,500, что явно превышает норму человека при типичном сёрфинге в сети.
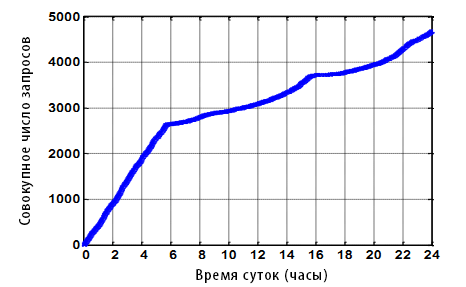
Рисунок 1. Время суток и собрание запросов одного ID пользователя.
Для детекции автоматизированного трафика есть несколько веских причин. Самой важной является точное отделение человеческих запросов от машинных, так как это улучшит впечатление пользователя от работы с системой в разных аспектах. Во-первых, для «законных» запросов может быть снижен отклик системы; поисковые системы всегда стараются улучшить Качество Обслуживания (quality of service, QoS) для своих пользователей. Путём уменьшения общего количество обслуживаемого трафика или, хотя бы, путём переупорядочивания запросов, можно ускорить работу системы для пользователей-людей (или поддерживать работу системы с меньшими затратами на оборудование). Кроме того, некоторые поисковые системы учитывают данные о кликабельности сайтов в их выдаче, так что таким образом возможно и увеличить релевантность документов по данному запросу, если отсеивать «неживой» трафик [11] [13]. «Живой» трафик, являющийся обратной связью от пользователей, можно использовать для обновления ранжирования соответствующих URL. Можно расширить фидбек за пределы обычных кликов и включить так же отсутствие клика для понижения позиций всех URL, которые были проигнорированы пользователем. Если четвёртый результат в выдаче кликался в три раза чаще, чем первый результат, то это может быть индикатором того, что он ранжируется слишком низко. Однако такой тип ранжирования провоцирует весьма подозрительное поведение – например, SEO-компании могут с лёгкостью создать бота, который будет кликать на URL клиентов. Такой тип автоматизированного прокликивания линков обычно относят к кликовому мошенничеству.
В одно время кликовое мошенничество по коммерческим запросам было серьёзной проблемой [3] [10] [11]. Подобные действия от компаний-конкурентов могут быть направлены на прокликивание платных объявлений в поисковой выдаче с целью увеличить затраты их бизнес-противников на рекламу. Другой формой кликового мошенничества является незаконный бизнес, позиционирующий себя как поисковые системы среднего пошиба, предоставляющий платные услуги по рекламе и перенаправлению незаконного клик-трафика. Не так давно в исследовании Click Forensics утверждалось, что кликовое мошенничество по коммерческим результатам в 4 квартале 2007 составляло 16% от всего рекламного трафика, что превысило на 2% показатели за 4 квартал 2006 года. В отчёте уточняется, что реклама в поисковых системах подвергается кликовому мошенничеству в меньшей мере, около 6% [3], что по-прежнему остаётся высоким показателем. В данной работе мы фокусируемся на автоматизированном трафике и кликах по некоммерческим результатам, у которых нет потенциальной выгоды от использования конверсии (т.е. метрики Cost-Per-Action, Цена Действия) в виде вторичного индикатора [10] законной активности.
Детекция машинного трафика может усложняться по некоторым причинам. Во-первых, идентификация пользовательских сессий является непростой задачей. Одним из методов для достижения этого является использование кукисов (cookie). Куки помещаются на компьютер целевого пользователя, когда он посещает сайт через свой браузер. Некоторые пользователи запрещают добавление куки, поэтому каждый их визит считается за посещение сайта новым пользователем. В подобных случаях для анализа используется IP-адрес запроса, если имеется подтвеждение, что он принадлежит только одному, а не нескольким пользователям.
Второй проблемой в детекции неживого трафика является то, что даже эксперты не всегда могут отличить машинный трафик от человеческого. Несмотря на то, что современные технологии автоматизированного трафика могут иметь довольно простую реализацию, сложнейшие ботнеты существенно повышают шансы программистов имитировать паттерны человеческого трафика [4].
Наконец, самой сложной проблемой является то, что паттерны поведения машины меняются со временем. Это означает, что узконаправленные шаблонные решения эффективны только в краткосрочном периоде. Например, бот может пользоваться одним и тем же IP-адресом продолжительное время, что позволяет на определённый срок заблокировать запросы с этого адреса. Подобные решения приводят к созданию чёрных списков IP-адресов, типам user agent, рефералам и т.д., которые приходится регулярно обновлять.
Наша работа вносит следующий вклад в решение проблемы автоматизированного трафика:
Работа организована следующим образом: смежные работы описаны в Разделе 2. В разделе 3 мы описываем данные поисковых запросов, использующиеся в исследовании. Раздел 4 посвящён поведенческим особенностям современных ботов. В Разделе 5 мы подроьно рассматриваем обнаруженные характеристики. Мы классифицируем эти особенности в две группы: характеристики физической модели и поведенческие характеристики. Результаты использования этих характеристик в классификации трафика и заключение размещены в последнем разделе.
Существует не так много работ, направленных на классификацию автоматизированного трафика в логах запросов. Agichtein, Brill, Dumais и Ragno разработали модели, изображающие пользовательское поведение при веб-поиске [1]. В данной работе авторы заинтересованы в моделировании пользователей, влияющих на релевантность ранжирования, но некоторые характеристики модели могут быть использованы для отделения людей от машинного трафика. Эти особенности показывают, что настоящие пользователи поставляют больше кликовых данных при взаимодействии с поисковыми системами, чем боты. Авторы рассматривают отклонения от нормального поведения, к примеру, растущее отношение количества запросов к количеству кликов по паре «запрос-URL». Кроме того, в них заключено время посещения страницы, переформулировка запроса и длина запроса.
Исследования по изучению кликового мошенничества в спонсированных результатах поиска концентрировались на паттернах трафика и пользовательском поведении. Эти работы не определяют машинный трафик в отношении органических результатов поиска, но они рассматривают саму природу потока запросов. Daswani и др. [4] анализируют крупный ботнет под названием ClickBot.A и подробно описывают его функциональность и технические возможности, комментируя исходный код. Данный ботнет представляет определённый интерес, так как он использует контролируемый запуск приложений, чтобы избежать своего обнаружения. Данный бот создаёт свои копии на более чем 100 000 компьютеров, имеющий уникальный IP-адрес и каждая копия кликает не более чем по 20 целям. Авторы исследования не предоставляют метод детекции этого ботнета.
Отчёт Tuzhilin [11] описывает проблемы детекции кликового мошенничества. В своём отчёте автор делает вывод, что корпорация Google проводит наиболее эффективную политику с целью уменьшения кликового мошенничества. Её техники включают как статический, так и динамический типы анализа, хотя конкретные меры и не описаны. В отчёте так же обсуждается альтернативная система поощрений, в которой вместо использования системы на основе отношения запросы/клики более выгодно использовать степень конверсии. Schluesse, Goglin и Johnson [10] разработали клиентский фреймворк для определения случаев, когда входные данные были сгенерированы автоматически. Технология нацелена на онлайн-игры, но так же упоминается, что её можно использовать для определения некоторых форм кликового мошенничества в онлайн-рекламе.
Fetterly, Manasse и Najork [5] провели похожее на наше исследование для обнаружения поискового спама. Они наглядно показали, что статистический анализ свойств веб-страниц, например, распределения заходов и исходов, соотношения хост-компьютер и кластеры почти совпадающих документов могут серьёзно помочь в определении документов как спамовых или нормальных.
Anick [2] взял как опознанных, так и предположительных ботов из внутренних адресов системы AltaVista для изучения поведения пользователя с использованием терминологической обратной связи. Для исключения трафика ботов из своего исследования мобильного поиска, Kamvar и Baluja рассматривали трафик, идущий исключительно от беспроводной сети [8]. Karasaridis, Rexroad и Hoeflin [9] анализируют транспортный уровень (сетевая модель по доставке данных) для обнаружения ботнетов IRC, работающих на DOS-атаки, кроме совершения прочих вредоносных действий. При этом, их метод не использует мониторинг портов для определения паттернов трафика. Однако работа не охватывает изучение ботнетов, атакующих поисковые системы.
В данном разделе мы описываем данные, которые используются в нашей работе. Мы получили случайную выборку из 100 млн. запросов популярной поисковой системе за 7 августа 2007. Мы разбили выборку по пользователям, так что если пользователь включён в наши данные, то всего его запросы за этот день так же включены в выборку. Для данного исследования мы отфильтровали данные, чтобы включить только тех пользователей, которые подавали запросы не менее 5 раз в день, что привело к сокращению выборки до 46 млн запросов.
В данной работе сессии пользователей захватывались при помощи куки, а каждому пользователю назначался уникальный идентификационный номер. Обычной практикой является так же захват сессий по IP-адресу. И хотя в некоторых случаях один IP-адрес обслуживал нескольких пользователей (т.е. являлся прокси), а в некоторых случаях один пользователь подавал запросы с разных IP-адресов (см. рисунок 4), технология захвата сессий по IP может пригодиться в нашем анализе [12]. Беглое изучение данных единственного дня показало, что 19,332,100 IP-адресов подают от 2 до 100 запросов в день. Во время анализа мы рассматривали большинство IP с низким количеством запросов как отдельных пользователей. Мы считаем, что классификатор, обученный на полученных куки так же мог бы помочь в валидации данных потенциальных сессий. В конце концов, единственный компьютер может генерировать как живой, так и машинный трафик одновременно. В таких случаях мы не пытались выделить множественные сигналы из единственного куки.
Приведём определения нескольких терминов. Запрос – это упорядоченный набор ключевых слов, поданный в поисковую систему. Поисковая система реагирует на запрос поисковой выдачей (impression set), которая является выборкой отображаемых результатов (как спонсируемых, так и органических). Поисковый запрос (query) может обладать несколькими уровнями запрашиваемости (requests), например, второй страницей результатов, на которой поисковая система покажет дальнейшую выдачу. Таким образом, общее число уровней запрашиваемости может быть выше общего числа поисковых запросов. Клик всегда относится к выдаче, показанной пользователю.
Здесь приводится описание нескольких ботов, обнаруженных в процессе изучения потока запросов. Первый бот сканирует индекс для поиска самых популярных спамовых слов. Обычно способом улучшения вебсайта является предоставление товаров или услуг на продажу; таким образом метрика релевантности запроса к ключевым фразам, найденным в почтовом и/или поисковом спаме явяется хорошим индикатором того, что запрос был сгенерирован машиной. Такой тип бота редко совершает клики, чаще он подаёт большое количество запросов и большая часть слов имеет высокую корреляцию с типичным спамом. Список из 12 запросов одного спам-бота приведён в таблице 1.
| ведение пабликов |
| списки рассылок |
| студенческие гранты |
| гороскопы |
| обучение онлайн |
| купоны на бесплатные товары |
| конвертировать видео |
| заказать отель в горах |
| бланки анкет онлайн |
| найти любовь |
| игрушки девяностых |
| товары супермаркетов |
Таблица 1. Пример запросов простого спам-бота.
Второй бот со схожим паттерном большого числа запросов без кликов, но с иной словесной базой, является финансовым ботом. 18 запросов бота представлены в Таблице 2. Большая часть ключевых слов в запросе связаны с кредитами, деньгами и недвижимостью. Целью этого бота является уточнение, какие из сайтов максимально релевантны данным финансовым терминам в поисковом индексе.
| lsttimehomebuyer | badcreditmortgage | equity |
| lsttimehomebuyer | badcreditrefinance | equityloans |
| 2ndmortgage | banks | financing |
| 2ndmortgage | bestmortgagerate | finaneinghouse |
| badcredithomeloan | debtconsolidation | finaneinghouse |
| badereditloan | debtconsolidationloan | firstmortgage |
Таблица 2. Пример финансового бота.
Активность некоторых ботов более опасна. Бот, запросы которого описаны в Таблице 3, работает с системой по различным URL, которые являются либо веб-сайтами, принадлежащими спамерам и работающих, соответственно, как спам-сайты, либо со взломанными веб-сайтами для создания хост-спама. По-видимому, бот пытается продвинуть позиции сайтов в поисковой выдаче.
Некоторые боты не только повторно запрашивают одну и ту же информацию у системы по соответствующей категории, но и подают запросы в таком виде, что выдают себя неестественным поведением. Например, один из ботов, запросы которого показаны в Таблице 4, использует запросы только из одного слова длиной 3-4 символа. Этот бот, по-видимому, ищет финаносые новости, относящиеся к определённым компаниям.

Таблица 3. URL бот.

Таблица 4. Стоковые запросы бота.
Ещё одним стандартным поведением бота является случай, когда пользователь с одним идентификатором посылает запросы из множества городов за короткий промежуток времени. Пример показан в Таблице 5 (IP-адреса не разглашаются в целях конфиденциальности). Этот пользовательский ID подал 428 запросов за 4 часа, при этом запросы подавались из 38 разных городов. Кроме того, этот бот всегда использовал кнопки перехода на следующую страницу, когда они были доступны, но никогда не кликал на результаты выдачи. Запросы данного бота характеризовались невероятно высокой степенью терминов взрослой тематики. Мы подозреваем, что данный ID автоматизировал трафик через инструментарий анонимного браузинга, но, как ни странно, данные инструменты не посчитались куки в качестве машины.
| Время | IP-адрес | Город |
| 4:18:34 | IP1 | Шарлоттвилль, Вирджиния |
| 4:18:47 | IP2 | Тампа, Флорида |
| 4:18:52 | IP3 | Лос-Анджелес, Калифорния |
| 4:19:13 | IP4 | Джонсон сити, Теннесси |
| 4:22:15 | IP5 | Дели, Дели |
| 4:22:58 | IP6 | Питтсбург, Пенсильвания |
| 4:23:03 | IP7 | Кэнтон, Джорджия |
| 4:23:17 | IP8 | Санкт-Петербург, Миннесота |
Таблица 5. Бот с одним куки и разными IP-адресами.
Нередко живой и машинный трафик генерируются с одного и того же компьютера. В некоторых случаях эта активность идентифицирует работу ботнета. Однако встречается и сценарий, когда автор программы просто использует поисковую систему для отладки своего бота. Например, один из «пользователей» подал 6,534 запроса, сделав всего 5 кликов. По анализу его действий 5 кликов соответствовали первым пяти запросам за день: «керамическая плитка», «керамическая плитка в ванную», «керамическая плитка в ванную купить», «керамическая плитка в ванную магазин», «пирс 1». Эти запросы подавались в течение 7 минут, что соответствует обычному паттерну использования поисковика. Однако затем пользователь подал 6,529 запросов в течение 3 часов без единого клика, что явно показывает активность бота.
В последнем примере один из пользователей подавал одинаковые запросы 1,892 раз в течение всего дня. 1,874 из этих запросов сопутствовали клики. Возможным мотивом для такой высокой степени кликов является желание узнать, почему топовые результаты ранжируются так высоко. Узнав их характеристики, пользователь может улучшить свои страницы аналогичным образом. Если пользователь обращается к индексу по запросу «самые лучшие цветы в Санкт-Петербурга» и затем обрабатывает html первых 1000 результатов, он сможет найти наиболее часто встречающиеся ключевые слова на этих страницах, включая правильные title, заголовки и т.д., а затем использовать их на своём сайте.
В Таблице 6 показана сводка характеристик, потенциально способных упростить задачу детекции автоматического трафика в потоке запросов. Обычно мы разделяем эти особенности на две группы. В первой содержатся характеристики физической модели человека. Вторая группа включает в себя отличительные особенности современного машинного трафика. В двух нижеследующих подразделах мы подробно рассматриваем каждую характеристику. Для всех характеристик были построены гистограммы, нормализованные по 100,000 пользователей. Зоны, относящиеся к поведению ботов обведены красным. Вертикальная ось отображает количество пользователей, которым присуща данная характеристика, а горизонтальная ось соответствует дискретному диапазону характеристики. В нескольких случаях мы нормализовали график по 1 млн. пользовательских ID для более наглядного отображения интересных зон.
| Название | Описание | Тип характеристики |
| Число уровней запроса, запросов, кликов | Количественная мера | Физическая |
| Скорость запросов | Максимальное число запросов за 10 с | Физическая |
| Число IP-адресов или локаций | Местоположение исходящего трафика | Физическая |
| Степень кликов | Отношение количества запросов к количеству кликов | Поведенческая |
| Алфавитная оценка | Индикатор упорядоченности по алфавиту | Поведенческая |
| Спамовая оценка | Индикатор ассоциированности слов со спамом | Поведенческая |
| «Взрослая оценка» | Индикатор отношения слов к порнографии | Поведенческая |
| Энтропия ключевых слов | Информационная энтропия слов в запросе | Поведенческая |
| Энтропия длины ключевых слов | Информационная энтропия длин слов в запросе | Поведенческая |
| Периодичность запросов | Периодичность запросов и кликов | Поведенческая |
| Оценка расширенного синтаксиса | Число терминов расширенного синтаксиса в запросе | Поведенческая |
| Энтропия категорий | Информационная энтропия категорий отдельных запросов | Поведенческая |
| Репутация | Чёрный список IP-адресов, user agent, кодов стран и т.д. | Поведенческая |
Таблица 6. Сводка характеристик.
В данном разделе мы освещаем несколько характеристик, относящихся к взаимодействию пользователя и поисковой системы. Людям присущи физические ограничения, касающиеся скорости ввода запросов, чтения результатов и кликанья по URL. Например, обычный человек может ввести и пролистать всего лишь несколько запросов за 10 секунд. Пользователь с сотней запросов за 10 секунд сильно выходит за рамки нормального пользовательского поведения. Автоматический трафик не ограничен скоростью ввода и чтения результатов, поэтому следующие характеристики могут быть использованы для выделения неживого трафика в потоке запросов.
Первым и самым главным индикатором машинного трафика является объём данных. Боты чаще всего подают значительно больше запросов за день, чем это делает обычный человек. Объём является характеристикой, статистическое распределение которой помогает определить тип данного пользователя.
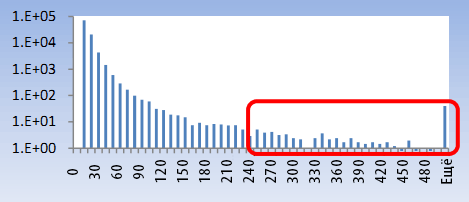
Рисунок 2. Число запросов.
К примеру, на Рисунке 2 показана распределение числа поисковых запросов от каждого пользователя в нашей выборке. И хотя считается возможной подача человеком более 200 запросов за день, гистограмма показывает, что такое поведение неестественно и встречается довольно редко. В процессе анализа было обнаружено, что большая часть трафика подобного объёма являлась автоматической. Один из пользователей подал запрос «mynet» 12,061 раз в течение дня.
Так как боты автономны, они способны подавать запросы с гораздо более высокой скоростью, чем это может делать человек, пользуясь вводом с клавиатуры. Различная статистика скорости запросов, включающая среднюю скорость, максимальное и медианное значение, помогает отличить генерацию запросов ботом от человеческой. Мы изучили скорость подачи запросов человека и сделали вывод, что пользователи редко подают более 7 запросов за 10-секундный интервал. На рисунке 3 мы изобразили распределение максимального количества запросов от человека за любой 10-секундный интервал в течение анализируемого дня. Пользователи со скоростью более 8 запросов за 10 секунд являются ботами.
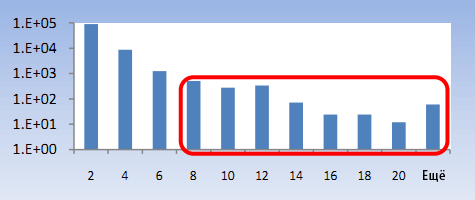
Рисунок 3. Максимальное количество запросов за 10 секунд.
Человек не может находиться в двух местах одновременно. Мы создали список IP-адресов, с которых подавались запросы по пользовательским ID с целью обнаружить потенциальные ботнеты. Если пользовательский куки совпадает по двум или более IP-адресам, которые физически располагаются на большой дистанции друг от друга, то, скорее всего данные компьютеры являются элементами ботнета. Однако в ином случае это может быть пользователь, запрашивающий систему опосредованно через инструменты анонимизации, но не запретивший приём куки.
Корреляции IP-адресов следует уделять особое внимание, так как мобильные устройства могут утром использоваться в одном городе, а в течение дня, возможно, в других городах и даже странах. Так же при устаревшем подключении к Интернету через dial-up модем, провайдеры могут каждый раз назначать пользователю новый IP-адрес при логине. В итоге следует игнорировать небольшие различия в дистанции географического местоположения. На рисунке 4 показана гистограмма пользователей с несколькими IP-адресами, нормализованная по 1 млн. человек. На рисунке 5 показаны те же самые пользователи, но при этом нормой в одном географическом регионе считаются только первые два октета (блока по 6 единиц) IP-адресов. Мы выделили зону, где встречается поведение, явно присущее ботам. Боты из таблицы 5 могут быть отмечены по данной характеристике.
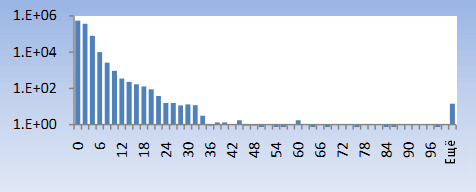
Рисунок 4. Отдельные IP-адреса (все 4 октета).
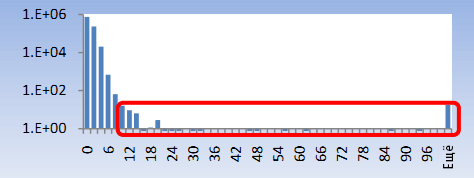
Рисунок 5. Отдельные IP-адреса (первые 2 октета).
В предыдущем разделе были показаны физические характеристики, по которым можно отличить машинный трафик от человеческого. Однако автоматизированный трафик может быть создан с учётом имитации человеческого поведения. По этой причине мы выделили ряд дополнительных характеристик, облегчающих классификацию запросов. В нескольких случаях мы приводим конкретные примеры отличий бота от человека.
Крупная доля автоматизированного трафика используется для сбора информации, например для изучения индекса поисковой системы или для получения данных с целью персонального использования, а поэтому в таком трафике встречается совсем немного кликов. Ранее освещённая скорость кликов обычного пользователя неплохо варьируется, но в среднем человек кликает хотя бы один раз в 10 запросов. Исследование данных показало, что множество пользователей без единого клика являлись ботами. При анализе крупной коллекции данных о поведении за день, эта характеристика весьма наглядно отражает действительность.
Данный принцип проиллюстрирован двумя распределениями на рисунках 6а и 6б. На рисунке 6а мы изобразили коэффициент кликов всех пользователей в опытном образце хотя бы с небольшим числом кликов. С увеличением числа запросов растёт и доля пользователей с нулевым числом кликов. Если сузить исследование только до пользователей-людей, то это поведение покажется странным, однако если учесть, что среди людей есть боты, то доля пользователей без единого клика будет логично обусловлена тем, что они – боты.
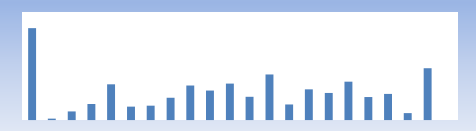
Рисунок 6а. Коэффициент кликов, минимум запросов.

Рисунок 6б. Коэффициент кликов, 10-кратный масштаб.
Например, один из пользователей подал 56,281 запрос без единого клика. А другой пользователь подал 1,162 запроса и кликал каждый раз. Изучая эти запросы оказалось, что пользователь скачивал выдачу индекса по ключевой фразе «168.216.com.tw.». Пользователь из Раздела 4, кликнувший 1,874 раза из 1,892 запросов так же был бы обнаружен по данной характеристике.
Некоторые списки запросов от ботов были упорядочены по алфавиту. Возможно, авторы программ использовали сортировку по алфавиту для облегчения поиска или анализа данных. При подаче запросов в поисковую систему такой способ будет явно причислен к автоматическому и легко вычислен. Возвращаясь к ботам из Таблицы 2, видно, что их поведение хорошо вписывается в рамки данного условия. Для расчёта «алфавитной оценки» пользователя, мы упорядочиваем его запросы по алфавиту и для каждой пары запросов [i, i + 1] мы добавляем 1, если i + 1 после сортировки идёт сразу после i. Соответственно, мы удаляем 1, если i + 1 идёт перед i. Число нормализуется по общему количеству запросов. В большинстве случаев алфавитная оценка приближается к нулю, как показано на рисунке 7. Дискретизация [-0.05, +0.05] содержит более 50% запросов в распределении. Почти во всех случаях, когда пользователь подавал много запросов и алфавитная оценка выходила за пределы [-0.30, +0.30] по нашему мнению трафик был автоматическим.
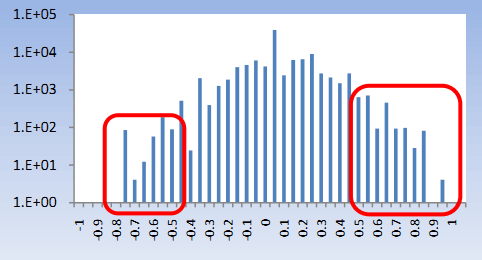
Рисунок 7. Алфавитная оценка.
Спам-боты подают множество запросов, состоящих из спамовых слов, примеры которых приведены в Таблице 1. Как следствие, характеристика, оценивающая количество спамовых слов в поисковых запросах может быть полезна для обнаружения спам-ботов. Мы рассчитали спамовую оценку в виде парной характеристики [спамовое слово, вес] по всем запросам каждого пользователя. Данный вес отображает вероятность спамовости данного слова. К примеру, слово «Виагра» имеет намного больший спамовый вес, чем слово «кофе». На рисунке 8 показана нормализованная гистограмма спамовой оценки запросов, извлечённых из индивидуальных куки. Помеченная область гистограммы соответствует пользовательским ID, подававшим запросы с большим количеством спамовых слов. Оценка пользователей рассчитана как простое сложение спамовых весов каждого запроса.
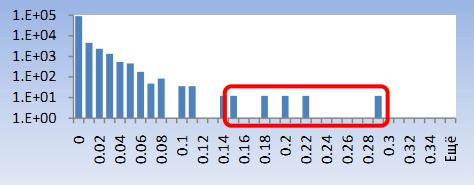
Рисунок 8. Спамовая оценка.
Индустрия «взрослых» развлечений быстро обосновалась в Интернете и заняла прочную нишу рынка. Многие деятели данной отрасли стараются привлечь новых клиентов посредством перенаправления пользователей на порнографические веб-сайты. Организации, занимающиеся созданием и поставкой подобного контента могут использовать ботов для оценки ранжирования их веб-сайтов или же для продвижения позиций своего сайта в поисковой системе. И хотя этот сегмент запросов так же является обычным для пользователей-людей, среди подающих такие запросы встречается много ботов. Как и со спамовой оценкой, мы используем пары [«взрослое» слово, вес] для расчёта «взрослой оценки» каждого пользователя. Нормализованная гистограмма на рисунке 9 показывает наличие «взрослых» ботов в потоке запросов.
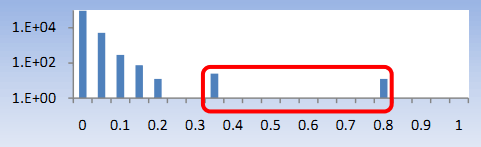
Рисунок 9. «Взрослая» оценка.
Многие боты вводят запросы с избыточным количеством слов. Как итог, запросы ботов подвержены тенденции обладания ненормальной энтропией, выходящей за рамки обычных паттернов использования. Мы создали карту из пар [слово, количество] для каждого пользовательского ID. Для назначения оценки каждому пользователю, использовалась классическая формула информационной энтропии H(k):
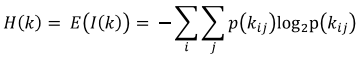
где kij является j-тым словом в i-том запросе, поданном пользователем. На рисунке 10 показано распределение энтропий ключевых слов в исследуемых данных. В одном примере бот обладал нулевой энтропией ключевой фразы, запрашивая слово «mynet» 10,497 раз. Так же можно рассматривать энтропию каждого запроса без парсинга на отдельные слова.
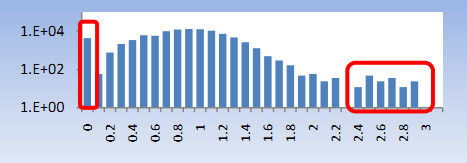
Рисунок 10. Энтропия запросов.
Обычные слова в запросах обладают естественным распределением энтропии длин слов, как и длины обычного запроса. Некоторые боты подают запросы по определённым классам слов, которые выходят за рамки данного распределения. Например, энтропия длины слова одного из ботов в Таблице 4 будет ниже, чем у человека. Энтропия длины слова WLE (Word Length Enthropy) рассчитывается как:
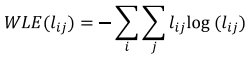
где i – это индекс каждого отдельного запроса, поданного в поисковую систему отдельным пользователем, а lij – это длина отдельного слова j в запросе i. Энтропия длины слова показана на Рисунке 11 (нормализована по 1 млн. пользователей). Так же можно использовать в качестве характеристики самый длинный запрос в сессии.
Частой практикой является регулярная генерация трафика ботом, например, каждые 15 минут [4]. Для задействования этого свойства мы упорядочиваем запросы по времени их подачи каждым пользователем и рассчитываем разницу во времени. По всем полученным приращениям (дельте) мы рассматриваем количество запросов у каждого пользователя. Затем мы рассчитываем информационную энтропию приращений.
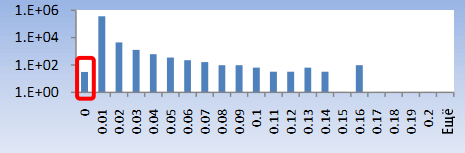
Рисунок 11. Энтропия длины слов.
Её можно рассчитать по различным интервалам приращений (секунда, 10 секунд, минута и т.д.). Посекундное распределение изображено на рисунке 12. Так же эту характеристику можно использовать для исследования времени посещения (dwell time) [1]. В комбинации с прочими характеристиками, такими как число уровней запроса, это свойство может оказаться нам на руку. К примеру, пользователь с 30 запросами может показаться человеком, но если энтропия приращений времени его запросов равна нулю, то это не человек, а машина.
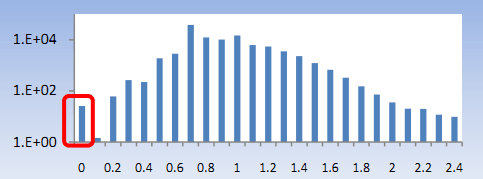
Рисунок 12. Энтропия интервалов.
Некоторые боты используют расширенный синтаксис запросов для извлечения конкретных данных из индекса. К примеру, использование префикса «intitle:» во многих поисковых системах запускает поиск ключевых слов исключительно в полях «title» веб-страниц.
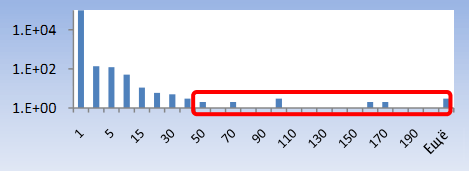
Рисунок 13. Расширенные запросы.
Аналогично, префикс «inURL:» сузит результаты поиска до анализа псевдонимов веб-страниц. Для обнаружения ботов, использующих расширенный синтаксис запросов, мы подсчитываем общее количество специальных префиксов и суффиксов в запросах каждого пользователя за этот день. Гистограмма анализа показана на Рисунке 13. Менее 0.01% пользователей использует более 5 элементов расширенного синтаксиса в исследуемой выборке. Например, один из ботов подал 110 запросов, каждый из которых искал что-либо в title документов.
Как обобщение спамовой и взрослой оценки можно использовать характеристику, определяющую количество отдельных категорий, ассоциированных с данным пользователем. Мы используем иерархию категорий, каждая из которых назначается отдельному запросу. Затем мы отслеживаем энтропию категории у каждого пользователя.
Определённые зоны в логах запросов могут напрямую указать на активность ботов. К примеру, можно использовать данные из чёрных списков IP-адресов, user agent и, частично, коды стран. По каждому свойству создаётся таблица с использованием специальных методик анализа. В таких случаях мы просто сверяемся с данной таблицей во время анализа. В менее однозначных случаях используются распределения числа запросов и пар запрос-клик. Например, некоторые боты подают очень низкочастотные запросы необыкновенно часто. Так же, зачастую, наблюдаются сессии с набором полностью бессмысленных запросов. Для обнаружения этих ботов создаётся таблица пар запрос-частота, которая помогает оценить популярность запроса у пользователей. Наконец, таблица пар запрос-клик по URL может помочь в оценке вероятности, что пользователь перейдёт на определённую страницу. Пользователи, часто кликающие по маловероятным парам попадают под подозрение. Однако потенциальной уязвимостью последних двух характеристик является необходимость раздельного и регулярного обновления таких таблиц, а с учётом их большого объёма, это довольно нелегко.
В данном разделе приводится обсуждение предварительных результатов классификации трафика по предложенным характеристикам. Мы разметили 320 пользовательских сессий, из которых 189 были человеческими, а 131 являлись машинным трафиком. Распределение намеренно разбито на равные части, так как мы использовали активное обучение для алгоритма. Возможно, это тот случай, когда нам потребуется проводить обучение для реально используемого классификатора. К тому же, более крупный набор данных для разметки повысит точность работы.
В Таблице 7 приводятся результаты классификации при помощи инструментария Weka [12]. Во всех случаях использовалась 5-слойная кросс-валидация. Мы маркируем автоматический трафик как верный положительный (true positive) TP. Большинство классификаторов работало более чем с 90%-й точностью на этой небольшой выборке.
| Классификатор | TP | TN | FP | FN | % |
| Bayes Net | 183 | 120 | 11 | 6 | 95 |
| Naive Bayes | 185 | 106 | 25 | 4 | 91 |
| AdaBoost | 179 | 119 | 10 | 12 | 93 |
| Bagging | 185 | 115 | 16 | 4 | 94 |
| ADTree | 182 | 121 | 10 | 7 | 95 |
| PART | 184 | 120 | 11 | 5 | 95 |
Таблица 7. Результаты классификации по предложенным характеристикам (выборка из 320 элементов).
Мы так же использовали инструмент оценки характеристик от Weka для понимания важности каждой характеристики, который называется Информационный Прирост (дивергенция, относительная энтропия) с использованием Ranker Search Method. Топ 5 характеристик по порядку были: число запросов, энтропия запросов, максимальное число запросов за 10 секунд, коэффициент кликов и спамовая оценка с оценками инструментарием в 0.70, 0.39, 0.36, 0.32 и 0.29 значений важности, соответственно. Как и предполагалось, объём данных является ключевым индикатором существующей активности ботов.
В данной работе мы проводим исследование поискового трафика крупномасштабной системы информационного поиска. Отделение автоматизированного трафика от человеческого полезно как для повышения релевантности выдачи, так и с точки зрения производительности системы. Нами был предложен ряд особенностей физической модели взаимодействия человека и поисковой системы, а так же показаны основные характеристики поведения ботов при их генерации автоматического трафика. Анализ распределений отличительных особенностей показал, что они могут использоваться в качестве фундамента для маркировки пользовательских сессий. На данный момент мы разрабатываем эффективный метод применения этих особенностей в классификации трафика и продолжаем вручную размечать большое количество пользовательских ID в логах запросов. К примеру, мы анализируем вклад каждой характеристики при классификации крупного объёма данных. Наконец, сейчас мы исследуем несколько аспектов, которые могут улучшить предложенный ряд характеристики, к примеру, пролонгированный анализ логов (1 месяц) и эволюцию поведения пользовательских ID.
Авторы выражают благодарность Zijuan Zheng, Fritz Behr и Toby Walker за их обширный инструментарий анализа.
Перевод материала «A large-scale Study of Automated Web Search Traffic» выполнил Роман Мурашов
Полезная информация по продвижению сайтов:
Перейти ко всей информации