SEO-Константа
Яндекс.Директ + оптимизация
Ключевой технологией всех без исключения современных систем информационного поиска является анализ гиперссылочной структуры. Большинство предыдущих работ, посвященных гиперссылочному анализу, использовали только ту информацию, что была получена в ходе единственного мгновенного снимка состояния ссылочного веб-графа. Поскольку агенты накопления данных поисковых машин обходят наш с вами веб с заданной периодичностью, в действительности они получают данные по веб-графу в виде временного ряда. Историческая информация, содержащаяся в этих рядах состояний, может быть использована для улучшения производительности алгоритмов гиперссылочного анализа. В настоящей работе мы доказываем, что авторитетность интернет-страницы следует рассматривать как динамическую величину, а также предлагаем определять значимость веб-документа не только в зависимости от его голосующей способности на текущем веб-графе, но и собранной исторической значимости по той информации, что получается из предыдущих состояний веб-графа. В частности, новый алгоритм, который называется TemporalRank, разработан нами для расчета предложенного показателя авторитетности страниц. Мы попытаемся использовать кинетическую модель для интерпретации указанной значимости веб-документов, а также показать, что ее можно рассматривать в качестве решения обыкновенных дифференциальных уравнений. Эксперименты, проведенные с использованием пяти мгновенных снимков состояний гиперссылочного графа, демонстрируют, что предложенный алгоритм способен превосходить такой известный алгоритм ссылочного анализа как Google PageRank по многим показателям, а также послужить эффективным фильтром для ссылочного спама.
За последнее десятилетие интернет продемонстрировал экспоненциальный рост. Однако, в тоже самое время, быстро увеличивается количество веб-сайтов с содержимым откровенно низкого качества, что привносит множество неудобств как пользователям поисковым машин, так и сами системам информационного поиска. Для решения этой проблемы критически важным становятся использование на поиске методов эффективной оценки авторитетности интернет-документов. Была проделана большая работа по части определения и расчета авторитетности документа посредством анализирования гиперссылочной структуры веба таким алгоритмами, как HITS [8], Google PageRank [3][11]; здесь также стоит упомянуть такие работы как [2] [6] [7] [9] [10]. Алгоритм PageRank является хорошим показателем авторитетности веб-страницы. Однако последние исследования [12] показали его уязвимость перед некоторыми манипулятивными методами. Кроме того, он не устойчив к ссылочному спаму [4][5]. В целях решения указанных проблем, мы полагаем, что определение эффективной оценки авторитетности веб-документа должно быть основано на множестве распределенных по времени мгновенных снимков состояний веб-графа. Спам страницы обычно обладают нестандартными паттернами изменения гиперссылочной структуры, увеличивающими их качество, а также сильно выделяющими их на фоне прочих документов. До нашего исследования некоторые работы предлагали учитывать в гиперссылочном анализе историческую информацию. Berberich и др. [1] разработали алгоритм T-Rank — метод анализа гиперссылочной структуры, который учитывал такие темпоральные аспекты, как новизну и обновление содержимого страниц, а также гиперссылок. Yu и др. [13] предложили PageRank взвешенный по времени, в котором ведущим на страницу линкам присваивались веса в соответствии с дополнительной временной информацией об их создании. Преимущество этих методик заключалось в том, что они извлекали и применяли темпоральную информацию, однако они не привнесли ничего принципиального нового в существующий фреймворк Google PageRank, использующий только единственный мгновенный снимок состояния ссылочного веб-графа. В настоящей работе мы постулируем, что подсчет авторитетности интернет-документа не должен основываться на статическом процессе. Вместо этого, необходимо работать с динамическим процессом, который рассчитывает упомянутую авторитетность с двух позиций: авторитетности, полученной исходя из расчетов по текущему веб-графу и аккумулированной исторической информации, полученной из предыдущих веб-графов. Следовательно, традиционный Google PageRank находит свое отражение в новой оценке авторитетности. Для расчета новых значений авторитетности мы разработали эффективный алгоритм, который называется TemporalRank, а также показали, что он может быть интерпретирован посредством кинетической модели и решён через дифференциальные уравнения. Эксперименты, проведенные на наборе реальных графов показывают нам, что наш алгоритм может быть более эффективным в оценках авторитетности цифровых документов, нежели чем традиционные подходы, а также превосходно вычислять и отфильтровывать ссылочный спам.
В данном разделе мы предлагаем фреймворк расчета авторитетности интернет-страниц по ряду состояний веб-графа, а также используем кинетическую модель для объяснения взаимосвязи между рассчитанной таким образом авторитетностью и Google PageRank с физической точки зрения.
Исходя из наших обсуждений Раздела 1, мы предлагаем оценку авторитетности страниц с использованием как текущего веб-графа, так и исторической информации, содержащейся в его предыдущих состояниях. Рассчитанную подобным образом авторитетность документа мы называем TemporalRank. Обозначая TemporalRank страницы i в t-м веб-графе посредством TRt(i), t=1,…,k, имеем следующую формулу (1):
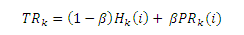
Здесь PRk(i) является показателем PageRank страницы i, рассчитанного по текущему веб-графу Gk и соответствующего текущему значению ее авторитетности; Hk(i) является собранной исторической информацией авторитетности, полученной из предыдущих веб-графов G1, G2,…,Gk-1; β (0<β<1) — это весовой коэффициент, необходимый нам для того, чтобы сбалансировать наше доверия между текущими и историческими данными, то есть: чем больше β, тем сильней мы доверяем гиперссылочной информации на текущем мгновенном снимке состояния веб-графа. Следующим шагом является определение Hk(i). Простейший подход заключается в линейной комбинации голосующей способности страницы i на предшествующих веб-графах следующим образом (2):
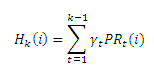
Здесь γt, t = 1,…, k-1 является коэффициентом затухания, указывающий нам на то, сколько авторитетности должно быть привнесено в итоговый показатель значимости интернет-страницы из тех данных авторитетности, что были получены по каждому мгновенному снимку состояния веб-графа. В общих чертах, более ранний снимок должен привнести меньшее количество авторитетности в показатель Hk(i). Таким образом, γt должен представлять собой группу коэффициентов затухания от t=k-1 до t=1. Комбинируя формулы (1) и (2), имеем (3):
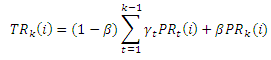
Из формулы (2) можно увидеть, что TemporalRank может быть рассчитан посредством линейной комбинации значений голосующей способности интернет-страниц ряда веб-графов. Ключевой проблемой формулы (3) является определение надлежащих весовых коэффициентов γt. Мы подробно остановимся на этом в нашем следующем подразделе.
В этом подразделе мы используем кинетическую модель, интерпретирующую предложенный нами ранее алгоритм TemporalRank, а затем выведем из данной модели рациональные весовые коэффициенты γt, t = 1,…, k-1 для линейной комбинации голосующей способности. Мы полагаем, что авторитетность страницы соответствует скорости объекта, движимого под действием некоторой виртуальной силы. Если в текущем мгновенном снимке состояния гиперссылочного графа Gt странице i присваивается значение PageRank PRt(i), соответствующая движущая сила добавляется к виртуальной силе Ft(i), действующей на этот интернет-документ. Это означает, что текущее значение голосующей способности оказало положительное воздействие на указанную виртуальную силу. В тоже самое время, затухание показателя TemporalRank TRt(i) обращается силой противодействия, которая оказывает отрицательное воздействие на данную виртуальную силу. В итоге, мы можем использовать следующее уравнение, моделирующее описанную выше кинетическую систему (4):
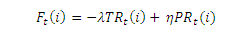
Здесь η (η > 0) является улучшенной константой, описывающей отношения между движущей силой и PRt(i), а λ (λ ≥ 0) — коэффициентом затухания. Фактически, уравнение (4) распространено во многих кинетических системах. Например, предположим, что наш автомобиль, движется по трассе со скоростью v, тогда сила противодействия R, действующая на нее (5):
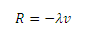
Здесь λ коэффициент затухания силы противодействия, а минус буквально означает то, что сила сопротивления направлена противоположено скорости v. В тоже самое время, автомобиль имеет движущую силу D, поэтому это уравнение можно записать в виде (6):
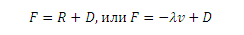
Определяя массу автомобиля как m, в соответствии со Вторым законом Ньютона, имеем (7):
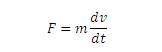
Используя изложенную аналогию, мы можем получить отношения между алгоритмом TemporalRank и виртуальной силой так, как это показано ниже (8):
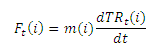
Здесь m(i) является коэффициентом некоторого внутреннего качества, присущего интернет-странице i, с тем же логическим значением, что и масса, присущая всякому физическому объекту. Комбинируя уравнения (4) и (8) мы получаем обыкновенные дифференциальное уравнение первого порядка (9):
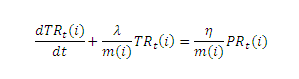
Данное обыкновенное дифференциальное уравнение может быть решено достаточно легко, и его общее решение представлено ниже (10):
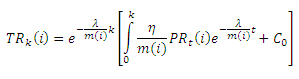
, где C0 является интегральной постоянной. Предположим, что в начале все страницы имеют равное исходное значение авторитетности (t=0). То есть, TR0(i)=1/N, где N количество цифровых документов, сформировавших заданный граф. Тогда, решение уравнения (10) может быть записано как (11):

По той простой причине, что темпоральные данные веб-графа являются дискретными, относительно времени, мы приводим приведенное выше решение к дискретной форме так, как это показано ниже (12):
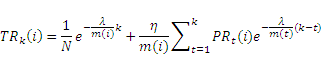
До сих пор мы используем для расчета показателя TemporalRank страницы i полученную формулу (12). Легко увидеть, что данная формула представляет собой линейную комбинацию значений Google PageRank документа i в ряду веб-графов. Если мы запишем это решение в иной форме, как это показано ниже (13),
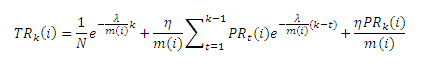
мы увидим, что первый элемент, составляющий правую часть формулы (13), является константой, относительно страницы i, представляющей собой начальное значение ее авторитетности; второй элемент представляет собой линейную комбинацию значений Google PageRank страницы i на предшествующих веб-графах, соответствующую Hk(i); наконец, третий элемент формулы содержит PageRank страницы i на текущем веб-графе. Это согласуется с тем, что мы обсуждали с вами в подразделе 2.1. Опуская при сравнении формул (13) и (3) константу, мы можем получить комбинацию коэффициентов следующим образом (14):
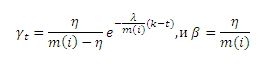
Из приведенных выше дериваций можно заметить, что кинетическая модель способна хорошо интерпретировать оригинальный фреймворк, использующий алгоритм TemporalRank, предложенный в подразделе 2.1, а также помочь нам привести весовые коэффициенты γt и β к некоторым более значимым параметрам λ, η и m(i). В соответствии с обсуждениями в предыдущих подразделах мы обобщим предложенный алгоритм TemporalRank в Таблице 1.
Таблица 1. Алгоритм TemporalRank

Набор данных, который мы использовали в своих экспериментах, представлял собой выборку подграфа, предоставленного коммерческой системой информационного поиска, которая содержала в себе пять мгновенных снимков графовых состояний (G1, G2, …, G5). Сканирование проводилось в первой половине 2006 года, и каждый снимок включал в себя порядка 30 млн. страниц и более 2000 млн. гиперссылок. Таблица 2 демонстрирует наши исходные данные.
Таблица 2. Количество интернет-страниц в каждом снапшоте
| Снимок | # веб-страниц |
| G1 | 31464052 |
| G2 | 31062569 |
| G3 | 30361077 |
| G4 | 29510456 |
| G5 | 28955134 |
Изменение количества интернет-страниц между каждыми двумя последовательными снимками графового состояния приведены в Таблице 3.
Таблица 3. Изменения количества интернет-страниц между каждыми двумя последовательными снапшотами.
| # новых страниц | # пропавших страниц | |
| G1 – G2 | 2952105 | 3353588 |
| G2 – G3 | 2830435 | 3531927 |
| G3 – G4 | 2838130 | 3688751 |
| G4 – G5 | 2916245 | 3471567 |
Для оценки производительности предложенного нами алгоритма TemporalRank мы использовали следующую тройку критериев: корреляция данных тулбаров (TC), корреляции данных пользовательских кликов на странице органической выдачи (CC), а также распределение спама по блокам. Часть пользователей согласилась использовать тулбары, предложенные коммерческой системой информационного поиска, которые регистрируют URL-адреса страниц в процессе их серфинга по вебу. Анализируя логи пользовательских просмотров, содержащихся в данных тулбаров, мы обнаружили 16737629 страниц, составляющих нашу выборку; мы подсчитали количество кликов по этим документам в качестве основы для нашей оценки. Рассмотрим следующую пару векторов: вектор ранжирования x с 16737629 элементами, выданный алгоритмом ссылочного анализа, и вектор кликов y по данным тулбар, который записывает количество кликов по страницам в соответствии с положением x. Корреляция данных тулбаров определяется в уравнении (15) как корреляция между векторами x и y, где M является длиной вектора x и y:
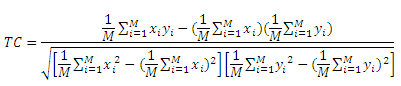
Система информационного поиска также записывают данные пользовательских кликов, приходящиеся по результатам органической выдачи, которые сигнализируют ей о том, какая интернет-страница была выбрана после введения в поисковую строку пользовательских запросов. Анализ поисковых логов показал наличие в нашем наборе данных 7067915 страниц, которые также содержались в кликовых данных системы информационного поиска. Как и в прошлый раз, мы использовали количество пришедшихся на интернет-страницы пользовательских кликов в качестве основы для нашей оценки. Для корреляции данных пользовательских кликов (CC) мы использовали методологию, схожую с корреляцией данных тулбаров. В общих чертах, если на страницу приходится больше кликов со страницы поисковых результатов, то мы рассматриваем ее как более авторитетную. Аналогично этому, с точки зрения алгоритмов гиперссылочного анализа, наибольший показатель ранжирования страницы указывает на ее более высокий авторитет по сравнению со всеми прочими документами. Следовательно, TC и CC могут послужить хорошими индикаторами производительности алгоритмов гиперссылочного анализа.
Для оценки эффективности предложенного подхода, мы также использовали в наших экспериментах распределение спама по блокам. Учитывая Google PageRank, мы можем сгенерировать перечень страниц в соответствии с убывающими значениями их голосующей способности. Мы разбиваем перечень по группам блоков, в каждом из которых содержится некоторое определенное количество цифровых документов. С учетом заданного набора заранее помеченных некачественных страниц, использующих ссылочный спам, далее мы можем подсчитать их число в каждом из имеющихся блоков. С этой целью мы попросили пять хорошо подготовленных экспертов отметить подмножество веб-графа на предмет некачественных страниц и, в результате чего, получили 11357 страниц, использующих ссылочные манипуляции. Если алгоритм гиперссылочного анализа обнаружит меньшее число спам-страниц в топовых блоках, нежели чем прочие методы, он будет рассматриваться нами в качестве наилучшего подхода.
3.3.1 Оценка посредством корреляций
Для понимания того, каким же образом эти факторы будут влиять на производительность нашего с вами алгоритма, для наших экспериментов мы сгенерировали следующие наборы данных:
Таблица 4. Наборы данных, содержащие различное количество графов.
| Имя | Содержащиеся веб-графы |
| S1 | G1, G2, G3, G4, G5 |
| S2 | G2, G3, G4, G5 |
| S3 | G3, G4, G5 |
| S4 | G4, G5 |
| S5 | G5 |
Мы запустили алгоритм TemporalRank с m=1 по пяти наборам данных с S1 до S5 с различными значениями λ (0, 0.001, 0.01, 0.1, 1, 10),а также показали соответствующую эффективность алгоритма по TC и CC на Рисунках 1 и 2.
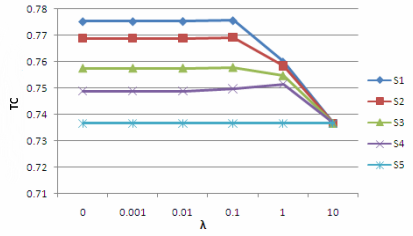
Рисунок 1. Производительность по корреляции данных тулбаров
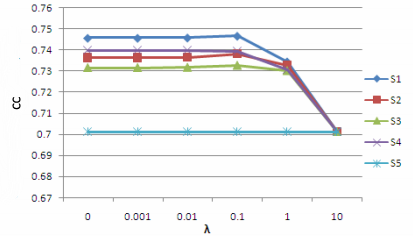
Рисунок 2. Производительность по корреляции данных пользовательских кликов
Необходимо отметить, что поскольку S5 содержит только единственный мгновенный снимок состояния веб-графа и m=1, производительность на этом наборе данных аналогично алгоритму ранжирования Google PageRank, который не зависит от коэффициента затухания. Из этих рисунков мы видим, что производительность TemporalRank по наборам данных S1-S4 оказывается лучше, нежели чем по S5 (соответствующего PageRank), вне зависимости от того какое значение принимает λ. Это свидетельствует о превосходстве предложенного нами метода перед классическим алгоритм ранжирования Google PageRank.
3.3.2 Оценка посредством распределения спама по блокам
Как уже упоминалось выше, далее мы проверяем результаты ранжирования с использованием методологии TemporalRank для того, чтобы оценить ранжирование наших с вами помеченных спам-документов. В частности, Рисунок 3 описывает распределение спам-страниц по блокам, каждый из которых содержит 1 млн. интернет-страниц (показано только ТОП 10 блоков), в целях исследования того, сколько же именно спама из мануально отмеченных 1502 спам-страниц окажется в них.
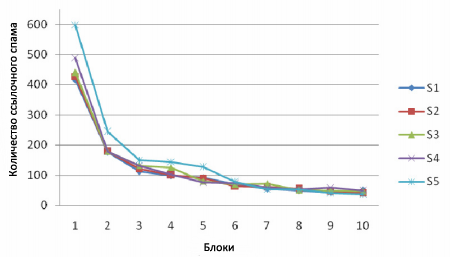
Рисунок 3. Распределение спама по блокам
И снова, результат по данным S5 фактически соответствует производительности PageRank поскольку этот набор содержит в себе только единственный мгновенный снимок состояния веб-графа. Исходя из Рисунка 3 видно, что по сравнению с классической методологией Google PageRank предложенный нами алгоритм TemporalRank способен подавлять недавно созданные для продвижения сайтов некачественные документы крайне эффективно. Кроме того, его производительность напрямую зависит с тем количеством веб-графов, который мы используем в наборе.
Мы предложили оригинальный фреймворк ссылочного анализа, использующего ряд веб-графов; определяющими факторами расчёта авторитетности страницы в нем являются гиперссылочная структура текущего веб-графа и собранная историческая информация, касающаяся ее авторитетности. Мы ввели кинетическую модель для интерпретации нашего фреймворка и разработки в нем эффективного алгоритма. Практические эксперименты показали, что посредством учета исторической информации, предложенный нами метод может достигать куда больших результатов, нежели ранние методы ранжирования цифровых документов и удаления ссылочного спама из топовых результатов органического поиска.
Текущая работа была выполнена в период стажировки первых двух ее авторов в Азиатской Исследовательской Лаборатории Майкрософт. Данное исследование проводилось при поддержке Национального научного Фонда Китайской Народной Республики, код проекта: 70471064; а также при поддержке Исследовательского Фонда Пекинского Технологического Института, код проекта: BIT-UBF-200308G10.
Перевод материала «Link Analysis using Time Series of Web Graphs» выполнил Константин Скоморохов
Полезная информация по продвижению сайтов:
Перейти ко всей информации