SEO-Константа
Яндекс.Директ + оптимизация
Технологии спама направлены на обман алгоритмов ранжирования в системах информационного поиска. Относительно недавно для борьбы со спамом был создан алгоритм TrustRank. Однако его слабым местом является неполный охват всевозможных тем в Интернете при работе с исходным набором данных, к тому же, TrustRank предвзято оценивает ресурсы, связанные с крупными интернет-сообществами. Нами предлагается использование тематической информации для разбиения исходного набора и расчёта оценок доверия для каждой темы по отдельности для решение вышеизложенных проблем. Комбинация раздельных оценок доверия используется для корректного ранжирования страницы. В наших экспериментах на двух крупных наборах данных показано, что версия Тематического TrustRank работает лучше оригинального алгоритма в задаче пессимизации спам-ресурсов. По сравнению с исходным TrustRank, наша технология способна пессимизировать до 43.1% спама из топовых результатов органического поиска.
Интернет-пользователи, в задачах поиска необходимой им информации, целиком и полностью зависят от систем информационного поиска. В случае с подавляющим большинством вопросов, с которыми пользователи обращаются к поиску, их поведение сводится к просмотру только первой страницы органической выдачи [26], которая обычно представляет собой только ТОП 10 предложенных результатов по данному запросу. Поскольку больший целевой трафик позволяет коммерческим ресурсам увеличивать свою прибыль, многие вебмастера обычно желают того, чтобы их любимые интернет-странички ранжировались в поисковых результатах настолько высоко, насколько это возможно. В то время, как одни вебмастера увеличивают рейтинг своих документов посредством улучшения их качественной составляющей, другие же, напротив, пытаются идти легким путем, манипулируя теми особенностями страниц, которые положены в основу алгоритмов ранжирования поисковых машин. Такое поведение, как правило, называется «поисковым спамом» [24, 12]. В работе Henzinger и др. [16] отмечается, что поисковый спам является одной из первостепенных проблем, стоящих перед системами информационного поиска. Несмотря на то, что в работах [24, 12, 6] было выявлено множество видов поискового спама, ни одна из них не предложила универсального метода его обнаружения. В целях противодействия спаму, Gyoengyi и др. [13] представили алгоритм доверия TrustRank. Главная идея данного метода основывалась на том предположении, что гиперссылка между двумя страницами свидетельствует о наличии доверия между указанными документами, то есть ссылка, ведущая с документа A на интернет-страницу B, передает доверие от документа A странице B. На предварительном этапе экспертами формировался некоторый исходный набор веб-сайтов, в число которых входили известные и надежные интернет-ресурсы. Каждому сайту из данной выборки назначалось исходное значение доверия. На следующем шаге, для пропагации доверительных оценок от родителя к потомкам использовалась специально настроенная (biased) версия алгоритма PageRank. После достижения точки конвергенции, хорошие сайты будут располагать относительно высокими доверительными оценками, в то время как некачественные ресурсы получат минимальное доверие. Несовершенство предложенной методики TrustRank заключается в недостаточном тематическом охвате тех сайтов-эталонов в первоначальном наборе, с которого начинается передача доверия. В Мировой паутине существует множество тематик, в каждой из которых можно найти свои качественные ресурсы. Используемый в алгоритме TrustRank процесс отбора страниц для формирования исходного набора не может гарантировать охвата подавляющего большинства тем. Таким образом, в случае применения алгоритма доверия в том виде, в котором он существует сейчас, в задаче детекции некачественных ресурсов мы можем достигать высокой точности при одновременном получении неудовлетворительного значения полноты.
Далее мы покажем, что классическая версия алгоритма TrustRank смещается в сторону того интернет-сообщества, которое имеет наибольшее число представителей в нашем исходном наборе, являющегося, как мы уже говорили ранее, точкой отчета для распространения доверительных оценок. Например, в том случае, если в первоначальной выборке присутствует большее количество эталонных страниц, относящихся к спортивной тематике, нежели чем тех документов, которые связаны с обработкой изображений, тогда странички, связанные со спортом располагают большими шансами получить высокие доверительные оценки, чем цифровые документы об обработке изображений. Следовательно, если некачественная страница посредством каких-либо уловок сумеет заполучить входящий на него гиперлинк с документа, состоящего в спортивном сообществе, вполне вероятно, что при таком сценарии, она будет оценена выше некоторых качественных документов, входящих в сообщество страниц, которое связано с обработкой изображений. Для решения указанных выше проблем, мы предлагаем внедрить в систему распространения доверия тематическую информацию. Для того, чтобы охватить все возможные тематики, мы предлагаем использовать те страницы, что зарегистрированы в таких авторитетных модерируемых каталогах как DMOZ Open Directory Project [21]. Для того, чтобы обойти проблему смещения, мы предлагаем дифференцирование степени доверия документов по различным тематикам, то есть наша страница должна обладать большим доверием в той тематике, которая ей соответствует. Это основано на том факте, что гиперссылка между двумя страничками, как правило, создается в контексте определённой тематики [4]. Наш подход, который называется Тематический TrustRank, разбивает исходное множество доверительных документов по тематически связанным группам, а затем рассчитывает TrustRank для каждой темы. Итоговый рейтинг основан на уравновешенной комбинации доверительных оценок по каждой конкретной тематике. В основном, крупные интернет-сообщества достаточно хорошо представлены в тематических каталогах. Так как классический TrustRank имеет тенденцию смещаться в сторону хорошо представленных сообществ, а самые крупные из них привлекают к себе большее количество поискового спама, мы намерены показать, что Тематический TrustRank, в среднем, может пессимизировать больший процент некачественных документов, чем оригинальный алгоритм TrustRank. Таким образом, в данной работе мы будем фокусироваться на улучшении производительности оригинального алгоритма в задачах пессимизации спам-страниц.
Настоящей работой мы привносим некоторый вклад в рассматриваемую тему. Во-первых, мы показываем, что классический алгоритм TrustRank имеет тенденцию к смещению в сторону наиболее крупных интернет-сообществ. Во-вторых, демонстрируем, что комбинация нескольких TrustRank’ов, основанная на случайных разбиениях может давать крайне нестабильные результаты. В-третьих, для определения соответствующих разбиений мы предлагаем использовать тематичность. В завершении всего, мы показываем, что в задачах пессимизации некачественных ресурсов, а, особенно, по части высокоранжируемых спам-сайтов, Тематический TrustRank имеет куда большую эффективность, нежели чем классический TrustRank. По сравнению с ним наша технология позволяет уменьшить объем спама на 43.1% среди веб-сайтов, отранжированных по методологии Google PageRank. Наш алгоритм использует только ссылочный граф и исходный набор, сформированный из различных тематик; в данном случае у нас нет необходимости исследовать содержимое документов или использовать текстовый классификатор. Это позволяет сделать весь процесс пригодным не только для применения в коммерческих системах информационного поиска. Оставшаяся часть исследования организована следующим образом: подготовительные и смежные работы приведены в Разделах 2 и 3, соответственно. Мотивы, послужившие толчком для текущей работы, приведены в Разделе 4. В разделе 5 даются детали алгоритма Тематического TrustRank. Проведенные нами эксперименты, а также их результаты продемонстрированы в Разделе 6. В Разделах 7 и 8 приведено обсуждение и итоги данной работы.
Gyoengyi и др. [13] предложили алгоритм доверия TrustRank. Данная методология исходила из достаточно простой идеи: хорошие сайты существенно реже цитируют некачественные интернет-ресурсы и пользователи доверяют им. Это доверие может быть распространено через гиперссылочную структуру Веба. Таким образом, отбирается некоторый перечень веб-сайтов, обладающих высокой степенью доверия, которые формируют нашу исходную выборку и каждому из которых назначается исходная ненулевая доверительная оценка, в то время как все прочие интернет-ресурсы имеют исходные значения равные нулю. Далее, для пропагации исходных доверительных оценок по исходящим гиперссылкам прочим документам используется настраиваемая (biased) версия алгоритма PageRank. После достижения точки сходимости, качественные сайты получают существенные доверительные оценки, в то время как некачественные ресурсы имеют более низкие значения доверия. Формула классического алгоритма доверия следующая:
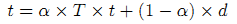
,где t является скор-вектором (score vector) TrustRank, α — коэффициент затухания; T — матрица переходов, в которой T(i,j) является вероятностью прохождения по ссылке со страницы j на документ i; наконец, d является нормированным скор-вектором доверия для нашего исходного набора (seed set). До начала расчета, t инициализируется со значением d. Разработчики алгоритма итерировали приведенное выше уравнение 20 раз с коэффициентом α = 0.85. Как указывали Gyoengyi и др., отбор эталонных страниц для формирования исходной выборки имеет решающее значение для успешной работы алгоритма TrustRank, и именно поэтому они применяли чрезвычайно строгую процедуру отбора тех 178 веб-сайтов из 31М отсканированных ресурсов, которые в конечном счете и сформировали начальный набор. Для каждого интернет-ресурса они рассчитали значения PageRank и TrustRank по графу сайтов. Сначала они разметили все веб-сайты по 20 блоков на основании убывающих значений их голосующей способности, а затем создали соответствующего им размера блоки для TrustRank. Из каждого блока была осуществлена случайная выборка по 50 сайтов, каждый из которых был вручную проинспектирован на наличие поискового спама. Результаты показали, что TrustRank позволяет улучшить алгоритм Google PageRank, сохраняя качественные ресурсы в блоках с высокой голосующей способностью, а некачественные, соответственно, перемещая в блоки наименее трастовых ресурсов.
В работе Henzinger и др. [16] было отмечено, что поисковый спам широко распространен в результатах органического поиска и без соответствующих мер по его нейтрализации, качество выдачи будет ухудшаться. Некоторые исследования были направлены на противодействие различным типам поискового спама и сейчас мы перечислим некоторые из этих работ. Fetterly и др. [9] предложили использовать статистический анализ для определения спамденсинга. Benczur и др. предложили алгоритм SpamRank [2], который исследовал распределение голосующей способности всех входящих гиперссылок для каждого интернет-документа. В том случае, если распределение не следует типичным паттернам, к данному документу применяются штрафные санкции. В работе Acharya и др. [1] было впервые предложено использовать исторические данные для идентификации страниц, использующих ссылочный спам. В работе Wu и Davison [28] были использованы наборы пересекающихся входящих и исходящих гиперссылок вместе с шагом пропагации для вычисления ссылочных ферм. В целях вычисления спама в комментариях, Mishne и др. [20] использовали языковую модель. Для определения ссылочного спама, Drost и Scheffer [8] предложили использовать методы машинного обучения. Сравнительно недавно, Fetterly и др. [10] описали методы по вычислению особого вида поискового спама, который конструирует веб-документы соединяя предложения из репозитория.
Несмотря на то, что идея сфокусированного (пользовательского) PageRank-вектора существовала изначально в [23], Haveliwala [14] был первым, кто предложил учитывать тематическую информацию при вычислении Google PageRank. В данной методологии использовались страницы из каталога DMOZ ODP для расчета значений PageRank внутри каждой темы, то есть вычислялся Biased PageRank. Далее рассчитывалось значение сходства пользовательского запроса для каждой имеющейся категории. Затем вычислялась единая оценка для каждого документа, содержащего данную фразу(ы) пользовательского запроса. Наконец, страницы ранжировались в соответствии с присвоенной им единой оценкой. Эксперименты показали, что Тематический PageRank имеет более высокую производительность по сравнению с классической моделью Google по части генерации лучших ответов по тому вопросу, с которым пользователь обращается к строке поиска.
Jeh и Widom [19] представили идею набора предпочтений, по которой глобальная оценка PageRank может использоваться при создании локальной (персональной) оценки. В этом случае, результаты органического поиска могут быть смещены в соответствии с данной персонализацией. Для реализации данного смещения авторы работы использовали формулу Biased PageRank. Chakrabarti и др. [3] описали ссылочное поведение в Мировой паутине посредством использования тематической классификации. Применив обучающий классификатор к темам ODP, они создали матрицу тематического со-цитирования (topic-topic citation matrix) между документами, которая продемонстрировала четкую доминирующую диагональ, означающую буквально то, что страницы, чаще всего, ссылаются друг на друга в пределах присущей им темы. Сравнительно недавно Chirita и др. в [5] описали метод комбинирования данных ODP с результатами органического поиска в целях генерации персонализированной выдачи. Используя заранее известные пользовательские профили, в работе рассчитывалось расстояние от данного документа до каждого URL, полученного в качестве ответа на вопрос из результатов органической выдачи; далее эти URL-адреса использовались для генерации новых выходных значений для пользователя. Наш подход также обращается к каталогам, которые составляются редакторами, однако в данном случае нашей целью является понижение доли веб-спама в поисковых результатах. Guha и др. [11] занимались изучением пропагации доверительных оценок в связанных социальных сетях. На основании реальной социальной общности веб-сайтов изучаются различные схемы пропагации как доверительных, так и недоверительных оценок.
Наиболее важным компонентом классического алгоритма доверия является отбор интернет-сайтов для исходного множества (seed set), из которого, собственно, и будут распространяться доверительные оценки. Различные подходы к ее формированию приводит к различным результатам. Процесс отбора страниц, который был использован разработчиками алгоритма TrustRank не гарантирует широкого охвата Мировой паутины. И в целях его достижения, наиболее естественным способом представляется использование тематической информации. Такие каталоги, в которых классификация страниц веб-сайтов проводится вручную, подобные Yahoo! и DMOZ Open Directory Project рассматриваются нами как ценные интернет-ресурсы, расширяющие нашу выборку. Вместо того, чтобы применять к сайту единую доверительную оценку мы решили предложить расчет доверительных оценок для различных тематик, каждая из которых отражает благонадежность данного сайта в определенной тематике. Мы полагаем, что комбинация указанных оценок станет более хорошим показателем надежности интернет-ресурса. Для реализации данной задачи мы можем разбить наше исходное множество по темам. Допустим, мы располагаем исходным набором T, который может быть разбит на n подмножеств T1, T2, …, Tn, каждая из которых будет содержать mi (1≤i≤n) выборок. Для представления дверительных оценок,
расчитаных посредством использования T в качестве иходного набора мы
используем t; для представления доверительных оценок, расчитаных
посредством использования Ti в качестве исходного набора мы используем
ti (1≤i≤n). Следующее уравнение является модификацией теоремы
линейности, доказанной Jeh и Widom [19]:
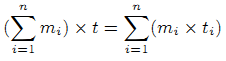
Приведенное выше уравнение показывает, что произведение доверительной оценки и общего количества выборок равно сумме произведений доверительных оценок каждого разбиения и количества выборок в данном разбиении. Преобразуем это уравнение следующим образом:
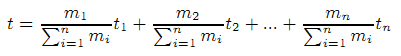
Из представленного выше уравнения мы можем наблюдать, что большие разбиения привносят больший вклад в доверительные оценки. В том случае, если в исходном множестве, которое используется в алгоритме TrustRank, наблюдается доминирование представителей какого-либо тематического сообщества, тогда очевидно, что TrustRank будет смещаться в сторону страниц данного сообщества. Как правило наиболее крупные веб-сообщества также связаны с популярными темами. Спамеры также проявляются повышенный интерес к популярным тематикам. На сегодняшний день поисковый спам становится всё более изощренным; он уже не видит препятствий в том, чтобы использовать хорошие/исходные документы для цитирования их некачественных страниц. Например, спамеры могут скопировать качественный контент из различных интернет-ресурсов, замаскировав, таким образом, свое манипулятивное содержимое и/или разместив в нем рекламу. В результате чего могут складываться ситуации при которых человеку, не обладающему определенными знаниями в области продвижения сайтов, будет затруднительно идентифицировать некачественный документ. Следовательно, вероятность того, что в крупных веб-сообществах будет наблюдаться более высокое содержимое спам-страниц, оказывается вполне реальной. Доказательством этому может служить работа Wu и Davison [27], в которой было обнаружено, что среди страниц, содержащихся в наборе ответных данных по популярным пользовательским запросам, технология клоакинга встречалась более чем в два раза чаще, нежели чем среди тех документов, которые содержались в наборе ответных данных по обычным запросам пользователей. Отсюда, смещение TrustRank может невольно оказаться на руку поисковому спаму, успешно размещающему гиперссылки на свой сайт из большого интернет-сообщества. Следовательно, сейчас мы будем исследовать методы, позволяющие уравновесить указанное смещение.
Как уже упоминалось в Разделе 1, представленных в исходном наборе объектов-образцов может оказаться недостаточно для тематического охвата всего разнообразия тем, существующих в интернете. Кроме того, как было продемонстрировано в Разделе 4, алгоритм TrustRank будет смещаться в сторону наиболее представительных в данном наборе веб-сообществ. Для того, чтобы решить указанные проблемы, мы вводим в систему распространения доверия тематическую информацию. Для решения вопроса, связанного с тематическим покрытием, мы предлагаем использовать страницы, представленные в таких авторитетных модерируемых каталогах, как DMOZ Open Directory Project [21]. Для решения вопроса, касающегося смещения, мы предлагаем дифференцирование степени доверия документов по различным тематикам, опираясь на тот факт, что две связанные гиперссылками страницы, как правило, относятся к одной тематике [4, 7]. Наш подход разбивает набор трастовых документов-образцов на тематически связанные группы, а затем подсчитывает значения TrustRank для каждой темы. Итоговое ранжирование основано на сбалансированной комбинации данных доверительных оценок по каждой отдельной тематике.
Мы разбиваем исходный набор (seed set) на части, соответствующие различным темам. Используя каждое из этих разбиений в качестве исходного набора, мы рассчитываем доверительные оценки для каждого узла веб-графа, используя алгоритм доверия TrustRank. В качестве упрощенного примера можно рассмотреть Рисунок 1, представляющий собой малый граф с 8-ю узлами.
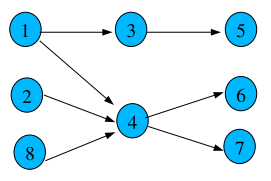
Рисунок 1. Веб-граф, состоящий из восьми узлов.
Из данных 8-и узлов, 1-ый, 2-ой и 8-ой являются образцами исходного набора. Предположим, что 1-ый узел соответствует одной тематике t1, в то время, как 2-ой и 8-ой узлы отвечают иной тематике t2. Очевидно, что тема t2 представлена в нашей исходной выборке более широко. Мы разбиваем исходный набор по темам. Результаты доверительных оценок, сгенерированных посредством применения двух исходных наборов, представлены в столбцах t1 и t2 Таблицы 1, соответственно.
Таблица 1. Результаты доверительных оценок на малом графе.
| Узел | t1 | t2 | t1 + t2 | t |
|---|---|---|---|---|
| 1 | 0.408 | 0.000 | 0.408 | 0.140 |
| 2 | 0.000 | 0.214 | 0.214 | 0.140 |
| 3 | 0.173 | 0.000 | 0.173 | 0.060 |
| 4 | 0.173 | 0.364 | 0.538 | 0.299 |
| 5 | 0.147 | 0.000 | 0.147 | 0.051 |
| 6 | 0.049 | 0.103 | 0.152 | 0.085 |
| 7 | 0.049 | 0.103 | 0.152 | 0.085 |
| 8 | 0.000 | 0.214 | 0.214 | 0.140 |
Таблица 1. Результаты доверительных оценок на малом графе.
Для того чтобы представить единую меру доверия к странице (оценку Тематического TrustRank) посредством применения настоящего подхода, мы рассматриваем две техники комбинирования сгенерированных нами тематических доверительных оценок, названные простым суммированием и смещением качества.
5.2.1 Простое суммирование
В данной технологии мы суммируем отдельные тематические доверительные оценки для генерации оценки Тематического TrustRank. Если обращаться к примеру на Рисунке 1, то простое суммирование тем продемонстрировано в столбцах t1 и t2 Таблицы 1. Мы будем называть эти оценки оценками Тематического TrustRank, присваиваемыми веб-документам. Кроме этого, в столбце t Таблицы 1 указаны оценки, сгенерированные посредством выполнения алгоритма TrustRank, который использует цельную выборку. Можно увидеть, что оба алгоритма присваивают узлам 1,2 и 8 высокие оценки. В то время, как классический TrustRank присваивает равные оценки всем трем узлам, в нашем алгоритме исходный узел 1, относящийся к меньшему по размеру сообществу, получает более высокую оценку Тематического TrustRank, нежели чем исходные узлы 2 и 8 по отдельности, которые входят в большее по размеру сообщество. Это происходит потому, что простое суммирование оценок предполагает равнозначное отношение к сообществам, но поскольку меньшему из них принадлежит начальный узел 1, то по окончании всех расчетов ему присваивается большая доверительная оценка, чем узлам 2 и 8. По аналогичной причине, Тематический TrustRank уменьшает разницу между узлом 5 и теми оценками, которые присуждены узлам 6 и 7. Теперь давайте рассмотрим пример, в котором узел 6 является спам-документом. Классический алгоритм TrustRank ранжирует его выше, нежели чем узел 3, который располагается всего лишь в одном шаге от исходного узла 1. Мы полагаем, что узел 3, который расположен только в одном шаге от исходного набора трастовых узлов имеет меньшую вероятность считаться некачественным ресурсом, в отличие от узла 6, который, в свою очередь, находится уже в двух шагах от исходного множества, то есть степень доверия к природе документа уменьшается по мере увеличения числа шагов от исходной выборки.
5.2.2 Смещение качества
В данной технологии мы вводим понятие смещения «качества» в комбинации отдельных тематических доверительных оценок. Мы предлагаем взвесить каждую отдельную тематическую доверительную оценку посредством фактора смещения wi топика i, назначая, таким образом, по полученным тематическим доверительным оценкам большую важность одним сообществам, чем другим. Возможным показателем смещения является среднее значение Google PageRank, полученное посредством усреднения значений PageRank по всем первоначальным страницам определенного сообщества. Отсюда следует, что чем выше показатель PageRank исходных страниц конкретного сообщества, тем больше мы доверяем оценке, поставленной этому сообществу алгоритмом.
Здесь мы предлагаем ряд усовершенствований базового алгоритма тематического доверия. Данные улучшения касаются отбора документов для исходной выборки.
5.3.1 Взвешивание выборки
В классической модели алгоритма TrustRank каждому исходному узлу назначаются равные значения в начальном векторе d (см. Уравнение 1). Для каждой исходной страницы данное значение представляет собой то, насколько высока вероятность того, что пользователь перейдёт на указанный трастовый документ в том случае, если он откажется от перехода по любым исходящим ссылкам с ресурса. Мы исследуем поведение алгоритмов TrustRank и Тематического TrustRank посредством изменения данного начального значения. Вместо того, чтобы назначить каждому исходному узлу постоянное значение, мы используем значение, пропорциональное его авторитетности или качеству. По сути, мы говорим о том, что некоторые страницы из исходной выборки являются более авторитетными, чем остальные. Мы используем нормализованное значение PageRank каждого исходного узла в нашей выборке в качестве начального значения узла.
5.3.2 Фильтрация выборки
В полученном из каталогов (если говорить более конкретно, из открытых тематических каталогов) наборе исходных страниц могут присутствовать как низкокачественные документы, так и поисковый спам. Второй случай возможен в силу тех причин, что не всегда редакторы располагают навыками детекции поискового спама или могут включать манипулятивные страницы по причине ценного содержимого последних. Кроме того, спамеры, занимающиеся перехватом доменных имен, могут использовать для своих проектов истекшие домены, которые могут все еще числиться в данных каталогах и, соответственно, нанести ущерб качественной составляющей исходного множества. Для устранения подобного рода ситуаций мы применяем некоторые технологии фильтрации нашей выборки. Отфильтровывая низкокачественные документы мы ожидаем увеличения производительности алгоритма тематического доверия. Для оценки качества исходных страниц мы можем использовать значения PageRank или Тематического TrustRank.
5.3.3 Учет разветвленной тематической структуры
Как правило тематические каталоги используют древовидную структуру. Большинство существующих работ учитывают только верхние тематические уровни такого дерева, так как учет всей разветвленной структуры данных с большим количеством тем достаточно дорогостоящий. В то же время интуитивно понятно, что более глубокий учет тематической структуры позволит достичь большей аккуратности в категоризации интернет-страниц. Для производительности алгоритма Тематического TrustRank безусловным плюсом будет являться именно более разветвленная тематическая структура, поскольку она позволит обеспечить большее разбиение нашего исходного набора. Например, некоторая страница, посвященная спортивной тематике, может быть хорошим исходным документом, но она не сможет охватить все существующие виды спорта. То есть эта страница будет трастовым документом для одного вида спорта, к примеру, тенниса, но не для другого, допустим, лыжного спорта. Имея достаточного размера данные (предоставлены швейцарской поисковой системой search.ch) с разветвленной тематической структурой, что будет описано в Разделе 6.1, мы также можем проверить использование более детальной классификации и оценить нашу производительность.
Для оценки предложенного нами алгоритма тематического доверия мы используем два набора данных. Первый набор представляет собой отсканированные данные Стэндфорского проекта WebBase [17]. Мы решили использовать набор данных за январь 2001 года, поскольку этот набор также применялся в прочих исследованиях (например, [14, 15, 19]). Мы скачали ссылочный граф, а также использовали Internet Archive [18] для проверки содержимого страниц в том случае, если это было необходимо. Ссылочный граф содержал в себе порядка 65М актуальных интернет-страниц. Для нашей исходной выборки мы также скачали ODP RDF-файл за 22 января 2001 года с ресурса dmoz.org [21]. Второй набор данных, предоставленный швейцарской поисковой системой search.ch [25], содержал в себе порядка 20М страниц и 350К сайтов, относящихся к доменной зоне .CH. Поскольку швейцарский провайдер поиска также предоставил нам перечень сайтов или доменов, применяющих различные манипулятивные практики (3589 сайтов), мы использовали его в качестве набора размеченных данных для тестирования. Мы также использовали существующий в той поисковой машине каталог ресурсов [25] с 20 различными темами, который схож с ODP за тем исключением, что в нем преимущественно представлены страницы, относящиеся к доменной зоне .CH. Так как в своих расчетах мы решили использовать граф сайтов и только страницы из тематического каталога, мы применили простейшую трансферную политику: если сайт имеет страницу в определённой тематике каталога, мы помечаем его как относящегося к той же теме. Поступая подобным образом, мы разметили 22000 сайтов в качестве исходного набора, разбитого на 20 эти тем. Мы обнаружили, что за исключением 20005 уникальных в плане своей тематики сайтов, остальные принадлежали сразу нескольким тематикам.
Как уже неоднократно говорилось ранее, алгоритм TrustRank смещается в сторону более широко представленных в исходном наборе веб-сообществ. Мы решили подтвердить это поведение TrustRank экспериментально, применив классическую версию алгоритма доверия и наш Тематический TrustRank к данным WebBase. Для начала мы выбрали ТОП-50 страниц на основании присвоенных им оценок TrustRank. Затем, мы разложили их общие доверительные оценки на тематические слагаемые, в соответствии с Уравнением 3 (см. Рисунок 2).
Рисунок 2. Разложение доверительной оценки на тематические слагаемые.
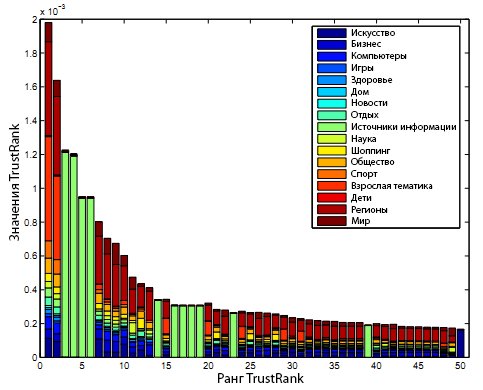
Видно, что в ТОП-50 доминируют такие темы, как «Источники информации», «Страны и регионы» и «Игры». Эти темы также имеют наибольшее число представителей в нашем исходном наборе, тем самым, подтверждая факт смещения классического алгоритма TrustRank к наиболее крупным интернет-сообществам. Аналогичным образом, мы выбираем ТОП-50 страниц на основании присвоенных им оценок Тематического TrustRank (простое суммирование) и разлагаем их тематические доверительные оценки на тематические слагаемые (см. рисунок 3).
Рисунок 3. Разложение тематической доверительной оценки на тематические слагаемые.
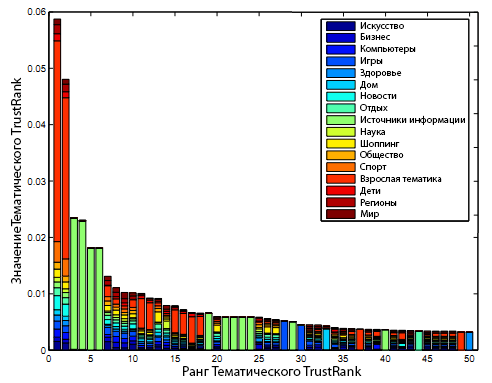
Если взглянуть на Рисунок 3, можно обнаружить ослабление влияния со стороны «Источников информации», «Стран и регионов» и «Игр», по сравнению с теми тематиками, которые внесли больший вклад в общую доверительную оценку документа, представляющую собой более сбалансированную версию комбинирования этих отдельных тематических оценок.
В текущем разделе описываются результаты, полученные для набора данных швейцарской поисковой системы search.ch.
6.3.1 Основные результаты
Следуя методике, описанной в классической работе TrustRank [13], сперва мы рассчитали Google PageRank по графу сайтов, который был предоставлен системой информационного поиска search.ch. Далее мы разместили эти сайты в 20 блоках, каждый из которых содержал интернет-ресурсы с суммарным значением показателей авторитетности равным 1/20 от суммы значений PageRank всех сайтов. Затем мы использовали 20005 эталонных ресурсов из каталога search.ch для расчета TrustRank каждого интернет-сайта. После этого, мы также разместили каждый веб-сайт в один из 20 TrustRank-блоков. При данном размещении мы руководствовались тем, что каждый TrustRank-блок должен содержать одинаковое по отношению к каждому PageRank-блоку, количество сайтов.
Для Тематического TrustRank мы использовали исходный набор для каждой из 20 тематик с целью расчета тематических доверительных оценок каждого интернет-ресурса. После этих расчетов, каждому сайту был присвоен вектор из 20 тематических доверительных оценок, каждая из которых представляла собой степень надежности ресурса в пределах заданного тематического сообщества. Для генерации оценок Тематического TrustRank мы применили технологию простого суммирования. Далее все сайты были отранжированы в соответствии с присвоенными им оценками. Как и в случае с классическим алгоритмом доверия, мы разместили эти ресурсы в 20 блоках. Опять же, критерием размещения являлось то, что всякий блок Тематического TrustRank должен иметь то же самое количество веб-сайтов, что и соответствующий ему PageRank-блок.
Мы оценили производительность каждого алгоритма ранжирования. Рассматривая наличие спам-ресурсов в самых популярных блоках как наиболее пагубное, мы использовали в качестве своей первой метрики, оценивающий эффективность всех алгоритмов, количество спам-ресурсов в первых 10 блоках. Нашей второй метрикой является общая пессимизация рангов данных спам-сайтов, которая определяется как сумма разниц в блок-позициях маркированных спам-сайтов при использовании тестируемого алгоритма ранжирования и методологии Google PageRank. Соответственно, чем существенней эта разница, тем большей эффективностью обладает наш алгоритм ранжирования в пессимизации рангов ресурсов, использующих инструментарий поискового спама. Результаты, которые мы получили для всех алгоритмов, представлены в Таблице 2(а).
| Алгоритм | # спама в 10 блоках | Общая пессимизация |
| PageRank | 90 | N/A |
| TrustRank | 58 | 4537 |
| Тематический TrustRank | 42 | 4620 |
Таблица 2(а). Основные результаты по набору данных search.ch.
В первых десяти PageRank-блоках оказалось 90 спам-сайтов. Классический алгоритм TrustRank пессимизировал ранги 32 из этих ресурсов, оставив нетронутыми 58 сайтов. В то же время Тематический TrustRank пессимизировал ранги 48 ресурсов, сохранив в существующих блоках только 42 веб-сайта. На Рисунке 4 продемонстрировано распределение некачественных сайтов по десяти блокам для всех трех алгоритмов ранжирования.
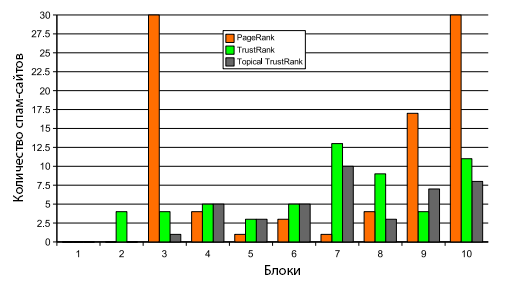
Рисунок 4. Распределение поискового спама по первым 10 блокам, содержащих в себе ресурсы из коллекции search.ch.
Если говорить про общую пессимизацию рангов некачественных веб-сайтов, то для классического TrustRank она составила 4537, а для алгоритма Тематического TrustRank — 4620 ресурсов. Результаты, которые приведены в упомянутой ранее Таблице 2(а), будут использованы нами как образец для последующего сравнения алгоритмов.
6.3.2 Результаты, полученные при случайном разбиении исходного набора
Для того, чтобы обосновать необходимость учета тематической информации при разбиении исходного множества, мы провели тестирование при котором выборка разбивалась случайным образом. Уравнение 2 сообщает нам, что в том случае, если каждое разбиение содержит равное число страниц-экземпляров, то суммирование доверительных оценок, присвоенных страницам в данном разбиении, даст нам оценку TrustRank. Для того, чтобы сравнение было объективным, мы создали случайные исходные наборы одинакового размера (такого же, как размер разбиений по темам). Мы провели случайное разбиение 10 раз по всему набору данных, предоставленных поисковиком search.ch. Всякий раз мы рассчитывали доверительную оценку ресурса в пределах каждого разбиения с последующим суммированием полученных оценок. Затем мы рассчитали распределение рангов 3589 отмеченных спам-сайтов. Количество некачественных ресурсов в пределах первых 10 блоков и их общая пессимизация отражены в Таблице 3.
| № разбиения | # спама в топ-10 блоках | # пессимизированных сайтов |
|---|---|---|
| 1 | 47 | 4575 |
| 2 | 69 | 4482 |
| 3 | 48 | 4581 |
| 4 | 52 | 4593 |
| 5 | 48 | 4539 |
| 6 | 74 | 4556 |
| 7 | 50 | 4521 |
| 8 | 46 | 4569 |
| 9 | 61 | 4568 |
| 10 | 54 | 4525 |
| Среднее | 54.9 | 4551 |
Таблица 3. Результаты случайного разбиения по набору данных search.ch.
Результаты в Таблице 3 показывают, что эффективность случайного разбиения не отличается той стабильностью, которую мы наблюдали по данным, приведенным в Таблице 2(а). Все 10 случайных разбиений продемонстрировали более некачественные результаты, нежели чем при их тематическом исполнении. Случайные разбиения 1, 3, 4, 5, 7, 8 и 10 показали несколько лучшие результаты, чем классический алгоритм TrustRank, однако 2, 6 и 9, наоборот, продемонстрировали ухудшение производительности. Наличие случаев с повышенной производительностью (наряду с улучшенной средней производительностью) поддерживает идею, что корректное разбиение идёт на пользу алгоритму. Возможно, еще более важным является наглядная демонстрация того, что даже наше начальное тематическое разбиение дает существенный прирост производительности, в отличие от того подхода, который основывается на случайных разбиениях.
6.3.2 Результаты по смещению качества
Здесь мы исследуем улучшение смещения качества, описанное в Разделе 5.2. Для этого мы назначаем веса каждой тематической доверительной оценке, используя среднее значение Google PageRank эталонных сайтов в пределах каждой темы до сложения оценок. Мы наблюдаем незначительное улучшение по сравнению с образцовым поведением, касающееся 40 некачественных ресурсов в первых 10 блоках. Общая пессимизация рангов составила 4620 сайтов, что идентично количеству в образце. Распределение спам-сайтов в первых десяти блоках показано на Рисунке 5.
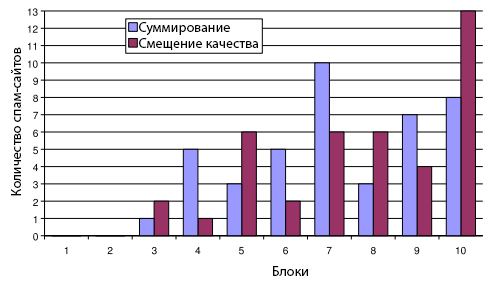
Рисунок 5. Сравнение технологий простого суммирования и смещения качества в наборе данных search.ch.
6.3.4 Результаты взвешивания выборки
По классической методике TrustRank, которая описана в работе [13], каждому начальному узлу назначается одинаковое начальное значение в пределах 1, распределённой по общему числу начальных узлов.
Чтобы узнать, как влияет на производительность различное значение вероятности перехода с исходных страниц, мы назначили каждому узлу начальное значение пропорционально его PageRank. В данной исходной выборке сперва рассчитывается сумма значений PageRank всех узлов. Затем каждому узлу назначается начальное значение в зависимости от пропорции его PageRank к сумме всех PageRank. Применяя эту технику взвешивания выборки мы рассчитываем значения TrustRank и Тематического TrustRank для каждого сайта. Результаты сведены в Таблицу 2(b).
| Взвешивание выборки | # спама в 10 блоках | Общая пессимизация |
| TrustRank | 63 | 4357 |
| Тематический TrustRank | 37 | 4548 |
Таблица 2(b). Производительность алгоритмов при взвешивании исходной выборки данных search.ch.
Из Таблицы 2(b) видно, что число спам-сайтов из первых 10 блоков отличается от числа в образце. В алгоритме TrustRank это число увеличилось, а в Тематическом TrustRank — уменьшилось.
Данный метод взвешивания полезен для уменьшения числа спамовых ресурсов в топовых блоках. И хотя в топ-10 блоках больше спам-сайтов по алгоритму TrustRank, сравнивая с результатами образца мы обнаружили меньше спамовых сайтов в первых 5 блоках. Но общая пессимизация спама для обоих алгоритмов всё равно хуже, по сравнению с образцом.
6.3.5 Результаты фильтрации выборки
Как упоминалось в Разделе 5.3.2, спам-сайты могут находиться в исходной выборке, в частности, в случае отбора страниц из открытых каталогов. К примеру, мы обнаружили 95 спам-сайтов, отнесённых к разным темам в наборе данных search.ch.
Очевидно, что такие случаи крайне нежелательны, так как спамовые сайты получат неадекватную доверительную оценку. К тому же, если эти спам-сайты указывают на другие спамовые сайты, то дочерние ресурсы унаследуют оценки доверия. Таким образом, желательно отфильтровывать низкокачественные ресурсы из исходной выборки до начала расчёта оценки Тематического TrustRank. Можно проверять исходную выборку вручную, но такой вариант подходит только тогда, когда в ней есть несколько сотен элементов. Однако в нашем случае их намного больше: 20005 сайтов по данным search.ch и 2.1М исходных страниц из ODP. К тому же, эти числа постоянно увеличиваются (например, сегодня в ODP уже более 4М страниц). Следовательно, ручная фильтрация выборки не подходит.
Как описывалось в Разделе 5.3.2, мы опробовали два метода автоматической фильтрации низкокачественных ресурсов в исходной выборке. Первый способ использует значения PageRank, а второй — значения TrustRank в исходных выборках, отфильтрованных по тематике. Для каждой темы сохраняется только первая половина выборки на основе доверительной оценки данной темы.
После фильтрации мы заново запускаем выполнение алгоритма Тематического TrustRank. Результаты показаны в Таблице 2(с). Видно, что использование PageRank для фильтрации не улучшает производительность, в то время как использование Тематического TrustRank повышает производительность по сравнению с образцовыми результатами.
| Фильтрация выборки | # спама в 10 блоках | Общая пессимизация |
| PageRank | 54 | 4536 |
| Тематический TrustRank | 42 | 4671 |
Таблица 2(c). Производительность Тематического TrustRank с фильтрацией выборки данных search.ch.
6.3.6 Результаты с двухслойной тематической иерархией
Мы изучаем влияние на производительность разбиения тем на более мелкие, уточнённые суб-тематики.
Для выборки search.ch мы использовали темы с двумя верхними слоями. Мы заметили, что существуют отдельные страницы (leaf pages), которые относятся только к верхнему слою темы. В таких случаях мы рассматриваем верхний слой как отдельную тему и относим к ней полученный набор страниц. Таким образом мы создали 326 различных тем. Среди них 312 оказались темами второго уровня, а остальные — темами верхнего уровня. Далее мы рассчитали доверительную оценку каждого сайта по этим 326 категориям, общую сумму оценок сайтов и сумму оценок каждого сайта по 312 темам второго уровня. Результаты сведены в Таблицу 2(d).
| Алгоритм | # спама в 10 блоках | Общая пессимизация |
| С верхним уровнем | 37 | 4604 |
| Без верхнего уровня | 38 | 4594 |
Таблица 2(d). Производительность Тематического TrustRank с использование дробления тем в данных search.ch.
Из Таблицы 2(d) видно, что оба варианта генерируют схожие результаты. В сравнении с результатами образца в Таблице 2(а), они понижают число спамовых сайтов в топ-10 блоках почти на 12%, однако общая пессимизация спама работает хуже. Это показывает, что раздробление тематик может приносить пользу только для топовых блоков.
6.3.7. Результаты по всем способам
Так как некоторых из вышеизложенных предложений улучшают производительность Тематического TrustRank, на ум приходит идея их комбинации.
Можно наблюдать, что 4 идеи, к примеру, использование двухслойных тем, фильтрации выборки, взвешивания выборки и смещения качества ортогональны, поэтому для нас важно использовать их в комплексе.
Сперва мы использовали 326 исходных наборов из двухслойных тем. К каждой теме была применена фильтрация путём сохранения топ-50% элементов на основе оценок Тематического TrustRank. Затем мы взвесили исходный набор, т.е. назначили каждому элементу начальный вес на основе значения PageRank. После расчёта доверительной оценки, мы использовали описанное в Разделе 5.2 смещение качества для комбинирования доверительных оценок. Наконец, мы рассчитали распределение спам-страниц на основе ранжирования, полученного в результате этой комбинации.
В ТОП-10 блоках были обнаружены только 33 спамовых ресурса, что показало уменьшение спама в 43.1% по сравнению с работой TrustRank в Таблице 2(а). Этот результат является наилучшим из всех наших техник по уменьшению спама. Общая пессимизация спама составила 4617 сайтов, что весьма близко к количеству сайтов по алгоритму Тематического TrustRank в Таблице 2(а).
6.3.8 Природа пессимизированных спам-ресурсов
Для понимания отличий во внутренней работе TrustRank и Тематического TrustRank, мы выбрали пример из отмеченных спамовых-сайтов, которые имели ранг тематического доверия ниже доверительной оценки. На рисунках 6 и 7 показан вклад индивидуальных доверительных оценок в общую, назначенных TrustRank и Тематическим TrustRank, соответственно.
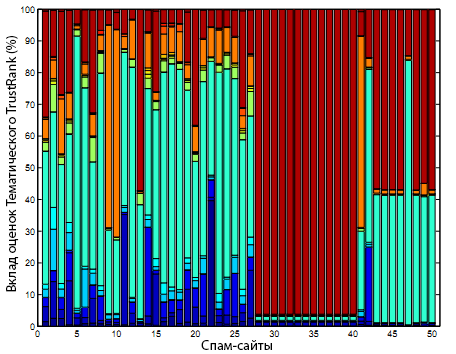
Рисунок 6. Вклад тематичности в работу TrustRank по спам-сайтам.
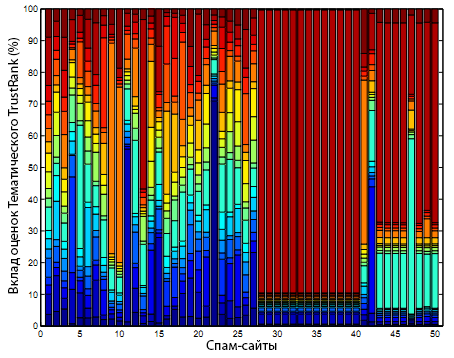
Рисунок 7. Вклад тематичности в работу Тематического TrustRank по спам-сайтам.
В случае TrustRank мы наблюдаем крупную долю сайтов с доминирующим вкладом тематической доверительной оценки. Но в Тематическом TrustRank эта доминанта снижена, что обеспечивает более сбалансированную общую тематическую оценку доверия.
Мы считаем, что в таком балансе комбинированной оценки Тематической TrustRank способен пессимизировать спам-сайты, которые наследуют доверие через пропагацию от крупных сообществ.
В данном разделе описаны результаты по данным WebBase. В качестве исходной выборки использовались тематические данные ODP. Здесь для расчёта используется ссылочный граф страниц.
Как и с данными search.ch, мы рассчитываем значения PageRank для каждой страницы и помещаем эти страницы в 20 блоков на основе их значения PageRank. Сумма всех оценок PageRank в каждом блоке составляет 5% от суммы всех значений PageRank.
Контент ODP со временем помещается в архив [22]. Мы использовали записи за январь 2001 для генерации исходных страниц, которые подходили выборке WebBase. Было извлечено 194К страниц из 17 тем верхнего уровня. Комбинация этих страниц послужила исходной выборкой. Для каждой страницы были рассчитаны значения TrustRank и Тематического TrustRank.
Было желательно рассчитать распределение спамовых страниц по всем алгоритмам. Однако из-за отсутствия спамовой маркировки в этой выборке, задача была достаточной сложной. Как вариант можно было извлекать образец в каждом из 20 блоков и проверять его вручную, однако после проверки 500 страниц мы обнаружили всего 16 спам-ресурсов. Такая пропорция спама была крайне мала для того, чтобы сделать адекватные выводы, поэтому ручной подход был признан неактуальным.
Другим методом детекции спама было сравнение числа пессимизированных спамовых страниц каждым алгоритмом. Чем выше такое число, тем лучше работает алгоритм.
6.4.1 Сравнение пропорций спама
Чтобы найти долю спама в оценках TrustRank и Тематического TrustRank мы сперва сгенерировали список страниц (1), PageRank которых был выше TrustRank. Затем мы сгенерировали ещё один список страниц (2), PageRank которых превосходил оценку Тематического TrustRank. В обоих списках содержалось порядка 8М страниц.
В первом списке было случайным образом выбрано 148 страниц и после проверки вручную среди них было обнаружено 30 спамовых страниц, т.е. доля спама составила 20.2%. Из второго списка мы выбрали 164 страницы и 50 (30.4%) из них были спамовыми. В соответствии с этими данными можно сделать вывод, что точность Тематического TrustRank примерно на 10% выше оригинального алгоритма (улучшение составляет порядка 50%).
6.4.2 Результаты по всем способам
Как было сказано в Разделе 6.3.7, комбинация идей по фильтрации выборки, взвешиванию, смещению качества и т.д. может повысить производительность. Мы провели похожий эксперимент на данных WebBase. Сначала выборка были отфильтрована, т.е. осталась только первая половина элементов по каждой теме на основе доверительной оценки. Затем выборка была взвешена, т.е. каждому узлу выдано начальное значение на основе оценки PageRank. После расчёта оценок доверия по каждой теме было использовано смещение качества (см. раздел 5.2) для создания взвешенной суммы оценок. Для оценки результатов комбинированной методики мы случайным образом выбрали 161 страницу, которые были пессимизированы как спамовые. Среди них 53 страницы использовали спамерские технологии, таким образом доля спама составила 32.9%, что опять продемонстрировало эффективность комбинированного подхода.
6.4.3 Распределение спама
Вручную было обнаружено 133 спамовых страницы, которые затем были использованы для построения графика (см. рис. 8) распределения спама по результатам работы трёх алгоритмов.
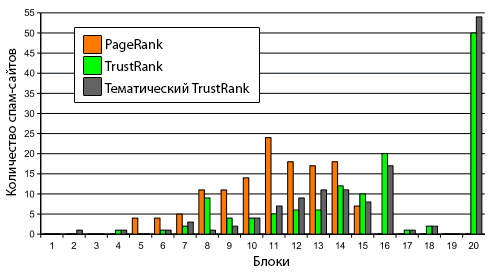
Рисунок 8. Распределение спама в наборе данных WebBase.
При работе Тематического TrustRank в топовых блоках содержится меньше спам-страниц (17), чем по исходному алгоритму доверия (21 в топ-10 блоках). Так же была рассчитана общая пессимизация спам-страниц: 604 по TrustRank и 628 по Тематическому TrustRank, соответственно, что показывает превосходство Тематической версии алгоритма.
6.4.4 Распределение оценок по данным WebBase
Из чистого любопытства мы построили распределение оценок PageRank, TrustRank и Тематического TrustRank для выборки WebBase. Мы разложили 65М страниц в выборке на 1000 супер-страниц. Каждая супер-страница содержала равное количество страниц, в первую были добавлены 65К самых высокоранжированных страниц, во вторую — следующий блок из 65К и т.д. Оценка супер-страницы записывалась как сумма оценок всех включённых в неё страниц. В случае Тематического TrustRank мы разделили оценку каждой супер-страницы на число тем (17 шт.) для адекватного отражения работы всех трёх алгоритмов в одном масштабе.
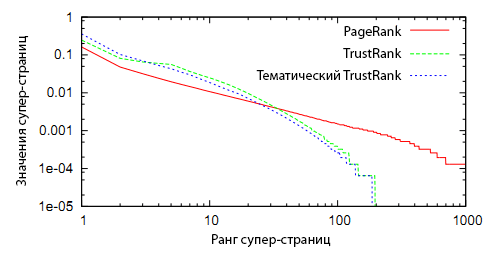
Рисунок 9. Распределение оценок трёх алгоритмов по данным WebBase.
На Рисунке 9 показано распределение оценок по всем трём алгоритмам в логарифмической шкале (log-log plot). TrustRank и Тематический TrustRank имеют похожие кривые распределения и отличаются от кривой PageRank. Видно, что оба алгоритма TrustRank обнуляются примерно на 20% страниц выборки, следовательно, 80% страниц из исходной выборки не попали в топ.
Пытаясь уменьшить смещение в сторону широко представленных в исходной выборке сообществ, мы предложили комбинированный подход для расчёта доверительной оценки. И хотя мы смогли пессимизировать спамовые страницы из крупных коммьюнити, побочным эффектом стал рост спам-страниц из более мелких сообществ — такова цена за простоту комбинации. В разделе 6.3.3 было показано, что производительность Тематического TrustRank может быть улучшена при помощи смещения качества, к примеру средним PageRank начальных узлов. Использование подобного смещения является многообещающим подходом в расчёте комбинаторной оценки доверия.
Возможно, существуют методики разбиения выборки, которые превосходят описанную в данной работе и мы планируем изучить их в будущих исследованиях.
Однако ближайшей проблемой является то, что одна и та же страница может быть помещена в несколько тематических категорий. Так как мы используем тематическую информацию, подобная мульти-тематичность может исказить оценку. В расчёте TrustRank данные мульти-тематические страницы учитываются только один раз. Работа с подобными страницами является областью будущих исследований.
Chakrabarti и др. в [3] указывали на то, что тема экспоненциально размывается начиная с первой страницы исходного набора. Таким образом, возможным улучшением Тематического TrustRank является введение классификатора, определяющего тематику дочерних документов страницы. Тогда вместо распределения родительской доверительной оценки, дочерние ресурсы будут получать свою долю пропорционально сходству своей темы с родительской.
Тематический TrustRank комбинирует тематическую информацию с доверием в Мировой Паутине на основе технологий ссылочного анализа. Мы выяснили, что TrustRank обладает определённым смещением оценки в сторону крупных интернет-сообществ. Так же мы продемонстрировали, что разбиение выборки по темам превосходит оригинальный алгоритм TrustRank, так же как случайное разбиение пессимизирует спам-страницы в топах. Так же мы изучили различные техники, которые могут повысить эффективность Тематического TrustRank и экспериментально доказали, что наша методика способна снизить долю спама на 19%-43.1% по сравнению с TrustRank.
Перевод материала «Topical TrustRank: Using Topicality to Combat Web Spam» выполнили Константин Скоморохов и Роман Мурашов
Полезная информация по продвижению сайтов:
Перейти ко всей информации