SEO-Константа
Яндекс.Директ + оптимизация
Основными направлениями деятельности разработчиков поисковых систем по улучшению качества поисковой выдачи является как борьба со ссылочным спамом, куда можно отнести неестественные линки, так и противодействие активному засилью контентного спама, то есть непосредственно относящегося к содержимому документа. Наиболее типичным примером последнего могут считаться неуникальная информация, переоптимизированный и автоматически сгенерированный бессмысленный контент. Что же касается неестественных ссылок, то придя на смену некогда популярному в среде веб-мастеров обмену, автоматическое размещение ссылок на сторонних веб-ресурсах предполагает как применение программного обеспечения для автоматической регистрации продвигаемого сайта в различных каталогах, рейтингах, досках объявлений, блогах и форумах (поисковые машины достаточно быстро решили этот вид ссылочного спама, полностью исключив влияние исходящих ссылок с немодерируемых ресурсов), так и пользование услугами многочисленных брокеров их автоматизированной купли-продажи, крупнейшим из которых является биржа sape.ru. С точки зрения поисковых систем, которые достаточно долгое время закрывали глаза на развернувшуюся на отечественном рынке поисковой оптимизации торговлю ссылочными инструментами, предполагая, что факт проплаченности не может делать ее «плохой», основная задача подобного рода инструмента не реклама, а именно манипуляция ранжированием. Как правило подобного рода ссылки размещаются на продажных сайтах в скрытом и/или почти скрытом виде, поскольку предназначаются они не для посетителей данных интернет-ресурсов, а агентов сканирования (роботов) поисковых машин.
На стыке между этими двумя инструментами манипулирования результатами поиска находятся системы продвижения статьями, которые, во-первых, в любом случае остаются методом давления на построение ранга, а следовательно, не приветствуются поисковыми алгоритмами Яндекса, Google и Mail, а, во-вторых, не всегда количественное увеличение содержимого сайта-донора (ресурса, размещающего у себя статью) является показателем полезности предлагаемой посетителям информации. Более того, можно говорить, что даже продвижение статьями может снисходить до уровня генерации контента и, тем самым, автоматически попасть под категорию контентно-ссылочного спама. Поэтому, существует правило, по которому вся полезная с точки зрения вебмастера информация должна размещаться в максимальной доступности для посетителя (например, внутренние ссылки на полезные материалы размещаются на главной странице ресурса и/или в других достаточно посещаемых директориях сайта). Потребность в минимизации воздействия спама на результаты выдачи, привело к созданию новых и всевозможных модификаций уже существующих алгоритмов, в том числе небезызвестного Google PageRank.
В то время, когда человек без особого труда может отличить хорошую страницу от некачественной, на автоматическом уровне все обстоит куда сложнее, поэтому сейчас мы предлагаем вам познакомиться с технологией, позволяющей в полуавтоматическом режиме отличать качественные страницы с авторитетных сайтов от тех спам-документов, которые создаются вебмастерами для раскрутки основных интернет-ресурсов в поисковых системах. Мы предложили нашим экспертам вручную оценить предложенный нами набор страниц с целью выявления тех параметров, которые присущи исключительно качественным документам, а после чего использовали полученные данные для автоматической идентификации авторитетных страниц в интернете. Надо заметить, что наибольшей спамоемкостью обладают сайты взрослой тематики, которые достаточно часто добавляют в содержимое своих страниц тысячи слабовидимых и/или невидимых (замаскированных с помощью CSS, дизайна) словосочетаний, в том числе не относящихся к подобной тематике. Для переадресации пользователей на свои целевые ресурсы они создают огромные массивы входных документов-дорвеев (от англ. doorway — входная дверь, портал), которых отличает автоматически сгенерированный контент и отсутствие какой-либо пользовательской полезности. Однако сегодня поисковые системы учитывают как количество входящих ссылок, так и переходы посетителей (напомним вам, что доверие к ссылкам у поисковых машин утрачено) в тематическом кластере сайтов.
Отнесение конкретной страницы и/или группы ресурсов к поисковому спаму должно осуществляться в зависимости от каких-либо часто встречающихся характеристик в том или ином документе. Поскольку, в одном случае мы можем иметь активно цитируемый кластер качественных веб-сайтов, которые просто рекомендуют своим посетителям посещение своих добросовестных соседей по сети, а при ином сценарии — внутренняя или внешняя схема манипуляции результатами выдачи. Проводя аналогии с тем спамом, который периодически попадает к каждому из нас на электронную поту, у всякого спам-документа в поиске имеются устойчивые наборы только ему присущих характеристик, отличающих его от качественного источника информации. Например, уже упомянутый замаскированный текст явно не представляет для нас интереса, посему мы смело можем записывать его в категорию обманных технологий. Аналогично можно поступить в случае нахождения страницы, которая содержит в себе тысячи URL’ов ссылающихся на подобного рода хосты:
order-website-optimization.wseob.ru,
order-website-promotion.wseob.ru,
У индексатора не останется каких-либо сомнений в необходимости приостановить сканирование такого документа, когда он обнаружит, что всем именам хостов (тем ключевым фразам, которые в них содержаться некоторые поисковые машины добавляют больший вес, чем их употребление в простом текстовом виде) соответствует один и тот же IP-адрес. Несмотря на то, что борьба с поисковым спамом сопряжена с большими финансовыми и ресурсными затратами, Google и Яндекс постоянно совершенствуют свои алгоритмы, поскольку в противном случае качество их поиска будет снижаться, а это незамедлительно приведет к отказу пользователей обращаться к их поиску. Основная цель нашей работы заключается в том, чтобы помочь тем специалистам, которые занимаются проблематикой поискового спама, в частности исследованиями характеристик документов в сети. На текущем этапе развития технологий идентификация спама посредством только автоматических методов достаточно сложна и для начала нам придется «научить» наш алгоритм отличать хороший документ от плохого. Для реализации этой задачи приглашенной группе экспертов был предложен некий набор цифровых документов, посредством анализа которого они должны были сообщать нашему алгоритму о нахождении как некачественных, так и качественных образцов (первый шаг), попавших в общую выборку. Затем, основываясь на полученных от экспертов характеристиках качественных документов, наша программа должна была самостоятельно (второй шаг) отобрать в новой выборке хорошие страницы. Основной вклад нашей работы заключается в том, что:
Представим сеть в виде ориентированного графа ζ = (υ , ξ), состоящего из некоего множества υ упорядоченных пар вершин (страниц), соединенных множеством ξ направленных ребер (дуг, ссылок). Несмотря на то, что в реальности, HTML-страничка (p) может содержать целое множество гиперссылок на другую страничку (q) сети, в нашей упрощенной модели мы укажем только одну единственную ссылку (p, q) ∈ ξ, а также удалим все внутренние линки. Тогда, наш упрощенный орграф (в части наших экспериментов мы будем исследовать уже не отдельные HTML-страницы, а их связанную группу — сайты) может быть изображен следующим образом:
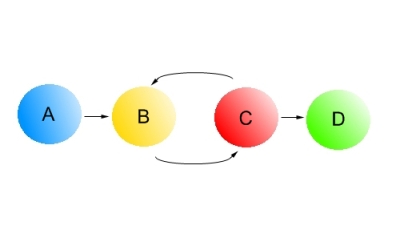
Рис.1 Упрощенная модель ориентированного графа, состоящего из четырех вершин и четырех ребер.
Каждая вершина-страница нашего орграфа имеет как входящие, так и исходящие ссылки. Количество входящих ссылок на страницу (p) является полустепенью захода ι(p) вершины, соответственно полустепень исхода ω (p) вершины — количество ссылок, исходящих из страницы (p). Если посмотреть в качестве наглядного примера на наш Рис. 1, то мы увидим, что на данном ориентированном графе HTML-документ С имеет одну полустепень захода вершины и две полустепени исхода. Вершина без исходящих ссылок называется висячим узлом (листом), а без входящих дуг — корневой. Изолированной вершиной будет считаться такая страница, которая полностью лишена каких-либо входящих и исходящих дуг, то есть степень вершины равна нулю. Если еще раз обратиться к нашему с вами замечательному Рис. 1, то страница А как раз будет являться корнем нашего графа, а D его листом.
Перейдем теперь к представлению орграфа двумя следующими матрицами, которые в дальнейшем будут играть для нас очень важную роль. Одной из них является матрица переходов T:
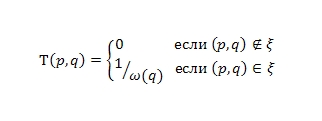
Матрица переходов соответствующая нашему ориентированному графу на Рис. 1 выглядит так:
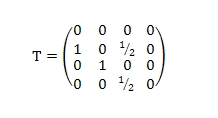
Мы также введем обратную матрицу переходов U, где U ≠ Ττ:
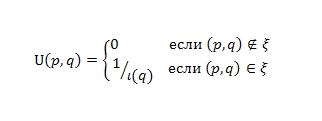
Обратная матрица переходов соответствующая нашему ориентированному графу на Рис. 1 выглядит следующим образом:
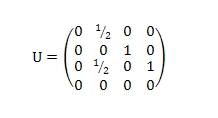
Так как наш алгоритм доверия TrustRank зиждется на PageRank, то в целях нашего дальнейшего исследования стоит упомянуть, что итеративный алгоритм Google PR основывается на идеи элементарнейшего статистического учета ссылочной авторитетности (популярности, цитируемости) сайтов и заключается в простейшем подсчете количества входящих ссылок. Поэтому, чем больше авторитетных документов сети будет ссылаться на нашу с вами интернет-страничку, тем будет выше ее показатель PageRank. Соответственно, данный алгоритм базируется на взаимодействии между документами и для нашей с вами страницы (p) он рассчитывается по следующей формуле:
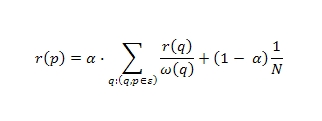
,где α — это коэффициент затухания.
Матричный эквивалент можно представить следующим образом:
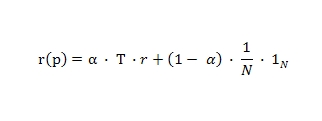
Следовательно, вес страницы (p) будет складываться частично из голосующей способности ссылающихся на нее документов, а также за счет того, что статистически каждой странице в сети уже присвоен первоначальный вес. Расчет показателя Google PageRank может быть выполнен итеративно (от лат. iteratio — повторяю), например, используя метод Jacobi [1]. В то время, когда с точки зрения математического подхода мы должны учитывать сходимость, то есть такую виртуальную точку, при которой нам следовало бы сообщить о достижении достоверного значения весов по истечению всех наших с вами итераций, он предполагает более общий подход к данной проблеме, при котором мы фиксируем количество Μ совершенных итераций. Если быть внимательным, то можно обратить внимание на то, что классический PageRank присваивает равные изначальные веса для всех документов в сети, но его модификация может предполагать и нулевые показатели. Пример матричного уравнения:
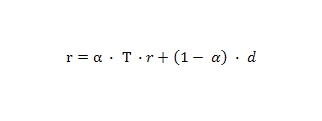
,где вектор d применяется для присвоения какому-то набору определенных документов статистического значения отличного от нуля. Затем, полученное значение распространяется в процессе всех наших итераций на те сторонние веб-документы, которым они передают свою голосующую способность.
Функции прогнозирования и доверия
Как уже говорилось ранее, отнесение какой-либо страницы веб-сайта к спаму не обходится без непосредственного участия человека и его субъективных оценок. Поэтому для формализации подобного рода оценок мы введем в наше исследование понятие двоичной функции прогнозирования ο его обнаружения на всех страницах (р) ∈ υ:

Рис. 2 Ориентированный граф, состоящий из хороших и плохих (черный цвет) узлов
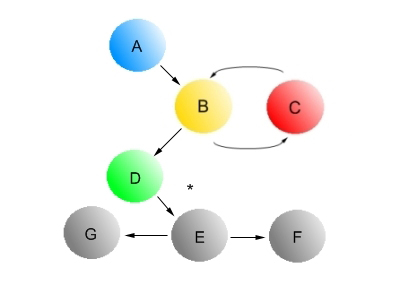
В качестве наглядного примера приведенной выше формулы, мы можем взглянуть на рис. 2, где наша двоичная функция прогнозирования с A по D возвращает нам значение равное единице. Тем не менее, стоит заметить что подобные расчеты на практике для всех интернет страниц будут сопряжены с огромными финансовыми и временными затратами, посему мы должны подходить к вызову данной функции прогнозирования избирательно, предлагая экспертам оценивать лишь некоторые образцы документов. Альтернативный метод, который мог бы применяться на практике, заключается в обоснованности даваемых оценок на эмпирических наблюдениях, в том числе на аппроксимации отчуждения (изолированности) хороших документов в сети, которые вряд ли будут ссылаться на некачественные сайты и иметь с ними сильную связанность. Действительно, плохие страницы редко предлагают своим пользователям ценную информацию и их единственной целью является введение посетителей в заблуждение, следовательно, у владельцев качественных веб-ресурсов нет никакого резона цитировать спам-контент. Однако в любом правиле существуют свои исключения, поэтому мы можем предположить еще и ту ситуацию, когда под каким-то предлогом и/или за определенное денежное вознаграждение (теперь вам стало понятно, почему поисковые системы объявили войну брокерам автоматической купли-продажи ссылок?) вебмастер хорошего сайта поставит ссылку на некачественный документ. Данную манипуляцию мы изобразили на нашем Рис.2, пометив ребро между страничкой D и E звездочкой. Давайте рассмотрим такой пример хитроумного распространения мусора, который заключается в том, что посредством необходимых спамерских программ злоумышленники наводняют немодерируемые доски объявлений и форумы (даже, если по всем своим параметрам они являются хорошими ресурсами) своими спам-сообщениями с гиперссылками на некачественный/вредоносный контент. Именно по этой причине, поисковые машины перестали учитывать в своих алгоритмах ранжирования немодерируемые веб-ресурсы. В широко развитой индустрии спама существует еще одна обманная техника, адресованная создателям качественного web-контента, которая действует по принципу «бесплатного сыра» и ее реализация заключатся в том, чтобы дать производителю сетевой информации какой-то полезный материал (это может быть техническая документация, новость, бесплатный шаблон для создания сайта и т.п.), который, вместе с тем, будет содержать сокрытые ссылки на раскручиваемый спам-ресурс. Помните, в самом начале мы упомянули про то, что продвижение сайтов статьями имеет достаточно относительную легальность? Верно, несмотря на размещаемую на сторонних хороших сайтах информацию, продвигаемый сайт может быть далек от совершенства. Отметим, что в кластере некачественных ресурсов аппроксимация отчуждения практически не наблюдается, и они достаточно активно могут цитировать авторитетные сайты с целью получения статуса посредников (хабов) и, как следствие, более высоких оценок со стороны алгоритмов поисковых систем.
Сейчас, для оценки документа без вызова функции прогнозирования ο мы попытаемся более формально определить степень нашего доверия к нему Τ с диапазоном значений от 0 (плохой документ, низкое доверие) до 1 (хороший документ, высокое доверие). Для идеальной страницы (р), функция доверия Τ (р) должна продемонстрировать нам предельно высокую вероятность соблюдения качества ее содержимого:
Безусловное доверие
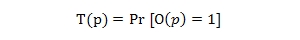
В качестве наглядной иллюстрации давайте предположим, что у нас имеется некоторая выборка из 100 интернет-страниц со степенью доверия каждого в 0.7. В случае применения той же двоичной функции прогнозирования ο и верного подсчета степени доверия Τ, для 70 страниц из 100 мы получаем значение функции прогнозирования равное 1, а для оставшихся 30 документов — 0. Заметим, что в реально функционирующей интернет среде очень сложно оказать какой-либо странице безусловное доверие, но, тем не менее, это должно поспособствовать более успешному подсчету вероятности определить качественный документ при непосредственном делении страниц/сайтов на хорошие и плохие. Например, нам даны две HTML-странички (p) и (q), где показатель доверия первого анализируемого документа оказался ниже последующего. Из этого можно сделать логический вывод о том, что страница (p) имеет меньшую вероятность оказаться хорошей и, соответственно, она должна быть представлена в результатах поиска с меньшим коэффициентом, нежели чем документ (q). Отсюда, мы имеем:
Ранжирующее доверие
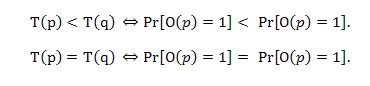
Для того чтобы понизить требования к нашей функции доверия Τ, мы введем в наши расчеты пороговое значение δ:
Пороговое доверие
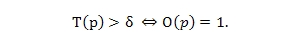
Иными словами, если документ (р) оценивается выше предельно допустимого доверия, то мы можем предположить его качественность, в противном случае мы ничего не можем о нем говорить. Обратите внимание на то, что показатель порогового доверия δ не всегда может обеспечить такую явную сортировку страниц, какая была описана в случае с безусловным доверием.
Метрики качества
Для выполнения следующей задачи нам необходимо сделать предположение о том, что в нашем распоряжении имеется некая случайная выборка χ цифровых документов, для которой мы можем вызвать функции прогнозирования Ο и доверия Τ, с тем, чтобы оценить качество работы нашего метода применительно к конкретной выборке. В дальнейшем мы обсудим по какому именно принципу мы подбирали для этого множества χ веб-документы, но в текущем рассмотрении мы опускаем подобного рода детали. Наша первая метрика будет тесно связана с ранжирующим доверием, и для нее мы введем в наш анализ бинарную функцию Ι (Τ, Ο, p, q), которая сообщит нам о наступлении такого события, при котором плохая страница получила равную и/или более высокую степень доверия, нежели чем какой-либо качественный документ.
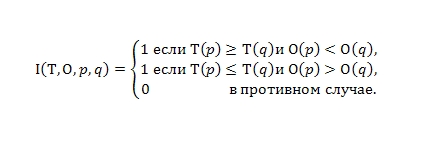
Затем, мы создадим из нашей выборки χ некое множество Ρ отранжированных по одному и тому же запросу пар веб-документов (p, q), p ≠ q и, вычислим процент безошибочного отнесения страниц в ту или иную категорию.
Попарное ранжирование
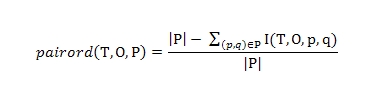
Таким образом, если pairord равен 1, тогда никаких ошибок в классификации пар документов обнаружено не было; в том же случае, если мы имеем 0, то во всех парах была допущена ошибка. В последующем материале мы покажем процесс отбора пар документов для выборки P. Две наши заключительные метрики (точность и полнота) связаны с пороговым доверием δ. В данном контексте мы определим показатель точности, как отношение хороших страниц ко всем веб-документам в выборке Х, которые имеют показатель доверия выше порогового значения δ:
Точность (Precision)
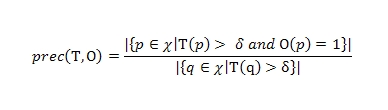
Тогда, мы будем определять полноту, как отношение хороших страниц с показателем доверия выше порогового значения δ к общему количеству хороших документов в выборке χ.
Полнота (Recall)
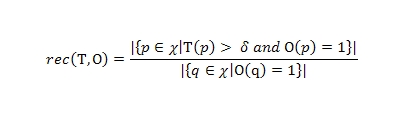
Страница материала:
Детекция поискового спама. Часть 1: Введение в алгоритм Google TrustRank
Детекция поискового спама. Часть 2: Расчет алгоритма Google TrustRank
Детекция поискового спама. Часть 3: От TrustRank к алгоритмам HostRank и DirRank
Детекция поискового спама. Часть 4: HostRank или PageRank, вычисляемый по графу хостов
Детекция поискового спама. Часть 5: От DirRank к алгоритму Truncated PageRank
Детекция поискового спама. Часть 6: Truncated PageRank и Вероятностный Подсчет
Детекция поискового спама. Часть 7: Знакомство с алгоритмом BadRank, обнуляющим Google PageRank
Детекция поискового спама. Часть 8: Google BadRank и ParentPenalty
Детекция поискового спама. Часть 9. Введение в алгоритм SpamRank
Детекция поискового спама. Часть 10: От исследования SpamRank к алгоритму Anti-TrustRank
Детекция поискового спама. Часть 11: Эксперименты с алгоритмом недоверия Anti-TrustRank
Детекция поискового спама. Часть 12: Применение принципов термодиффузионной
Детекция поискового спама. Часть 13: Детальный анализ алгоритма ранжирования DiffusionRank
Детекция поискового спама. Часть 14: Вычисление AIR на веб-графе, эквивалентного электронной схеме
Детекция поискового спама. Часть 15: Применение искусственных нейронных сетей
Полезная информация по продвижению сайтов:
Перейти ко всей информации