SEO-Константа
Яндекс.Директ + оптимизация
Основным мотивом к разработке текущего подхода обнаружения поискового спама, послужило то, что путем опытных наблюдений нам удалось обнаружить следующую закономерность: во-первых, страницы-участницы ссылочных ферм имеют между собой сильную связанность, а во-вторых, в системах линкофарма существуют общие для них узлы-посредники, имеющие как входящие, так и исходящие ссылки. Исходя из этого, мы сможем собрать несколько страниц-экземпляров обманной технологии в качестве первоначального набора, а затем расширить его за счет поштучного включения дополнительных, связанных с ним несколькими входящими и исходящими ссылками веб-документов. Вышеописанный процесс может продолжаться итеративно до тех пор, пока мы не подключим к расширенному набору все связанные с линкопомойкой сайты. Текущий механизм способен обрабатывать значительные объемы данных, с той единственной оговоркой, что предварительно нам необходимо найти несколько страниц для формирования первоначального, исходного набора для его последующей многократной разверстки. Отсюда, двумя ключевыми аспектами нашего алгоритма является генерация и расширение набора некачественных интернет-документов. Как уже упоминалось нами в предыдущей части материала, посвященного детекции поискового спама, наш метод предполагает следующие шаги:
Как и в случае описанного нами ранее алгоритма Google BadRank, в качестве отправной точки нам необходимо создать исходный посев страниц, в котором каждая из них будет определена нашим спам-фильтром как некачественный документ. Однако для начала нам потребуется ответить на принципиально важный для себя вопрос: на основании каких же именно характеристик мы будем относить тот или иной документ к спаму? В действительности, решение достаточно простое. В то время, как стандартная страница может иметь несколько входящих и исходящих ссылок, ведущих на какие-либо сторонние ресурсы, в линкофармах имеются узлы-посредники с общими для всей системы входящими и исходящими ссылками. Например, если какой-то документ связан с одним или двумя общими узлами, мы не станем помечать его в качестве проблемного, однако в случае наличия большого числа исходящих и входящих ссылок на документе-посреднике, мы отнесем такую страницу к элементу единой схемы манипуляции. В своей работе мы будем использовать порог ТIO таким образом, что всякий раз, когда количество общих гиперссылок в их входящей или исходящем множестве превышает и/или равняется установленному предельно допустимом значению, мы автоматически заносим такой узел в нашу спам-коллекцию. В наших экспериментах мы установили предельно допустимое значение в 3, что позволяет нам отыскивать линкфармы, состоящие всего лишь из 4-х элементов. Так как детализация проводилась нами на уровне сайтов или доменов, при
сопоставлении входящих и исходящих ссылок мы не придерживались их полному постраничному соответствию. Одним из преимуществ детализации на уровне доменов, а не URL-адресов, заключается в том, чтобы учесть достаточно распространенный в среде web мастеров трюк, заключающийся в создании на сайте специальной отдельной страницы для любительского и/или профессионального обмена ссылками. Алгоритм обнаружения первоначального набора спам-страниц:
Обозначим интернет-адрес страницы за p, а за d(p) — доменное имя p. На шаге инициализации мы задаем N страниц. В этом случае IN(p) и OUT(p) представляют собой множество входящих и исходящих ссылок соответственно.
Для того, чтобы пояснить вышеперечисленные шаги, давайте взглянем на Рис. 33. Мы имеем сеть из шести HTML-страничек, которые, как мы полагаем, размещены на разных доменах. Для данного элементарнейшего примера мы установим предельно-допустимое пороговое значение в 2. Входящими ссылками для узла А являются ссылки с [C,D,E], а исходящими — с узлов [B,C,D]. Следовательно, для страницы А общими узлами-посредниками будут являться набор [C,D], содержащий равное число элементов (два) для предельно допустимого порогового значения. Обратите внимание на то, что в этом случае мы добавляем в наше спам-множество не только узел А, но также C и D, поэтому в завершении всей операции оно выглядит как [A,C,D].
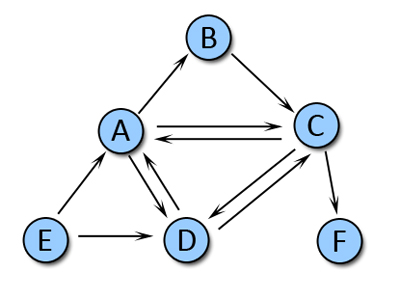
Рис. 33. Простой пример формирования набора спам-документов
Для того чтобы увеличить сформированный набор спам-документов, нам потребуется еще один шаг по его расширению, который будет осуществляться с помощью нашего алгоритма ParentPenalty. Поскольку всякая ссылочная ферма должна активно ссылаться на прочие документы внутри своей собственной группы, мы будем придерживаться следующей логики: если страница ссылается только на один, пусть даже подозрительный документ мы не станем применять к этой порочной связи жестких санкций. Однако, в случае наличия множества исходящих линков, мы будем считать ее составным элементом единой схемы по манипуляции результатами органического поиска. Также мы будем применять для своих оценок предельно-допустимое пороговое значение, и увеличивать исходное множество постепенно, для начала добавляя всего лишь несколько документов, в содержимом которых имеется больше всего внешних исходящих ссылок.
Как мы уже говорили, для шага по расширению множества мы будем использовать наш алгоритм ParentPenalty. Основным посылом для нашего логического рассуждения будет являться то, что в случае проставления внешней исходящей ссылки с какого-либо документа на некоторое число некачественных страниц, нам также следует подозревать данный веб-документ (саппортер) в поддержке спама. Таким образом, как и в алгоритме Google PageRank мы имеем голосующую способность, передаваемую от одной HTML-страничке к другой, за тем исключением, что в расчетах учитываются не входящие, а исходящие ссылки. Помните, в предыдущей части нашего материала мы знакомились с Google BadRank, который также учитывал исходящие ссылки? Наш алгоритм также имеет ряд принципиальных и, как нам кажется, вполне уместных модификаций от данного анти-спам алгоритма, о которых мы поговорим несколько позже. Для оценок страниц на предмет спама мы будем использовать иной предельно допустимый порог (TPP) в 3 ссылки, суть коего сводится к следующему: если количество внешних исходящих ссылок со страницы на подозрительных соседок по сети равно и/или превышает пороговое значение, мы помечаем ее как спам. Всякий раз, при проставлении подобного рода отметки о некачественности документа мы также сверяем количество ссылок с цитирующих его страниц с предельно допустимым значением. Итерационный процесс продолжается до тех пор, пока все подозрительные web-страницы не будут помечены надлежащим образом. Также, для того чтобы существенно расширить наш набор некачественных страниц мы будем включать в него документы даже в том случае, если URL-источник и URL-цель принадлежать одному и тому же домену. Алгоритм ParentPenalty:
Предположим, что после инициализации мы получили массив A[N], в котором плохие документы обозначены за 1, хорошие — 0, а пороговым значением является TPP
Давайте еще раз вернемся к нашему примеру на Рисунке 33 и к полученному ранее первоначальному набору [A,C,D]. Если в качестве предельно допустимого значения мы используем 2, то в случае наличия двух и/или более исходящих линков на какой-либо узел из данного набора, мы будем считать его подозрительным. Узел B имеет только 1 исходящую ссылку, E — две, а узел F — 0.
Таким образом, мы отмечаем узел E как спам-страничку и назначаем ей значение в 1. Поскольку никакие другие не были уличены нами в неэтических методах продвижения, наш алгоритм ParentPenalty завершает свою работу с расширенным спам-набором [A,C,D,E].
Задачей предыдущих шагов было нахождение плохих страниц в пределах имеющегося набора данных. Теперь нам необходимо отыскать такой способ, который бы позволил бы нам включить эту информацию в алгоритм сортировки результатов поисковой выдачи, и одним из очевидных механизмов является понижение весов или удаление элементов в матрице смежности интернет-графа для нашего набора данных. Поскольку у нас имеются страницы помеченные в качестве участников линкофармов, мы можем применить к ним строгие санкции, то есть удалить их из web-графа, хотя на практике это было бы излишне. В качестве простого примера того, что в ряде случаев нам следует всего лишь пессимизировать голосующую способность между веб-документами, а не полностью исключать их из поиска, можно привести ресурсы аффилированных компаний и их дочерних структур. Их часто интересует продвижение сайтов, и они ссылаются друг на друга, создавая некое подобие ссылочной схемы, но, вместе с тем, могут предоставлять пользователю поисковой системы достаточно ценную информацию и удовлетворять их насущные потребности. Безусловно, наложение штрафа на подобного рода связи предполагает, что в дальнейшем эти документы смогут получать необходимые им голоса от других честных авторити-страниц, так как мы минимизируем лишь то ссылочное влияние, которое возникает при участии сайтов в какой-либо обманной практике. Если же говорить о методологии понижения весов более подробно, то назначение веса каждой ссылке будет осуществляться пропорционально общему количеству голосов, отданных за плохой документ, то есть в случае наличия на какой-либо страничке-участнице ссылочной фермы 10 исходящих линков, в матрице смежности они будут иметь значение 0.1. Так мы не берем во внимание качество содержимого исследуемых страниц и их полезность для пользователей поиска, в нашем примере мы решили придерживаться жесткого наказания за спам и полностью удалять ссылки на некачественные ресурсы, поэтому в своей матрице смежности мы указываем значение 0.
Заметим, что мы удаляем все ссылки между страницами, уличенными в использовании схем ссылочной манипуляции. Несмотря на то, что наши алгоритмы могут достаточно эффективно обнаруживать link farm, это еще не позволяет нам решить проблему «взаимного усиления» [1]. Поэтому мы будем использовать один из вариантов модификации алгоритма HITS, который был предложен Bharat и Henzinger, и в коем мы будем присваивать ребру вес 1/k в том случае, если у нас имеется k страниц, ссылающихся из одного хоста на единственный документ, расположенный на другом хосте.
Таким образом, мы только что подготовили нашу матрицу смежности для ее последующего ранжирования с помощью таких алгоритмов построения выдачи, как Google PageRank и HITS, а также взвешенной популярности (подробно изучено в [2]), под которой в данной работе будет пониматься обобщение простейшего метода ранжирования web-документов по количеству входящих ссылок. Так как мы понизили веса элементов в матрице (используя вариант Bharat и Henzinger) и даже приравняли некоторые из них к нулю из-за маркирования страниц как спам-документов, мы используем сумму всех взвешенных значений входящих ссылок в матрице смежности в качестве метрики и ранжируем все страницы в соответствии с ней. Мы считаем взвешенную популярность алгоритмом ранжирования по той простой причине, что он очень прост, имеет высокую скорость и может давать результаты куда лучшие (будет продемонстрировано далее), чем классический метод HITS.
Как мы упоминали в предыдущей части нашего с вами материала, Google BadRank имеет схожую с нашим алгоритмом философию: страница веб-сайта штрафуется за цитирование некачественных документов. Однако, в случае с алгоритмом Google мы не имеем четкого понимания того, насколько далеко должно распространяться это наказание. Если страница A ссылается на документ B, который, в свою очередь, ссылается на некоторое множество плохих страниц, то было бы вполне логично применить к данному документу B соответствующие санкции, но стоит ли их применять к нашей исходной страничке A? Давайте приведем маленький пример, в котором университет информационных технологий ссылается со своей главной страницы на персональный сайт одного из своих студентов, являющегося активным участником какой-нибудь программы по автоматическому обмену ссылками и имеющим в своем контенте несколько исходящих ссылок на спам-ресурсы. Кого мы должны пессимизировать в этой ситуации? Конечно же сайт студента, и только его, поскольку ресурс университета здесь абсолютно ни при чем! Тем не менее, в алгоритме Google страница университета информационных технологий также получает некоторое ненулевое приращение BadRank, посредством пропагации соответствующего ранга от одной или большего числа страниц с ненулевым значением BR.
Идея же нашего алгоритма ParentPenalty более устойчива к вышеописанной проблеме. Посредством использования предельно допустимого порогового значения TPP мы определяем то, стоит ли нам распространять негативную оценку страницы-потомка на его на родителя. Логика следующая: в том случае, если количество плохих потомков равно и/или превышает наше пороговое значение, мы накладываем штрафные санкции на родителя. Затем, если количество оштрафованных нами страниц-родителей равно и/или превышает предельно допустимое пороговое значение, мы также пессимизируем прародителей. Таким образом, пороговое значение играет очень важную роль в предотвращении пропагации негативного голоса для значительного числа поколений страниц.
Для тестирования нашего алгоритма мы использовали два набора данных. Для формирования первого набора наших экспериментальных данных мы применили процесс сбора данных аналогичный в HITS. Сначала мы отправили запрос на search.yahoo.com для извлечения ТОП 200 релевантных ему URL-адресов; далее, с помощью повторной отправки запросов на Yahoo!, для каждого URL-адреса, извлеченного на предыдущем этапе, мы получаем ТОП 50 входящих ссылок. Для текущего эксперимента мы использовали 412 запроса (они включали в себя запросы из исследований [17, 23, 10, 12, 20, 21], названия разделов из каталога dmoz.org, популярные запросы из поисковых систем Lycos и Google) и скачали более чем 2.1 млн. уникальных веб-страниц, которые ссылались на ТОП 200 URL-ов. Второй набор данных, который нам любезно предоставила швейцарская поисковая система The Swiss Search Engine, содержал порядка 20 млн. веб-страниц и 317,640 уникальных домена. Мы построили для второго набора граф доменов и применили к нему наш алгоритм обнаружения ссылочных ферм ParentPenalty.
Возьмем запрос «научно-исследовательский центр IBM». На шаге инициализации, генерирующего первоначальное спам-множество, мы обнаруживаем только 10 URL-адресов (См. Табл. 11-А). Большинство URL из данной таблицы соответствуют сайтам добропорядочных компаний, однако все они имеют очень сильную связанность, что рассматривается нами как один из видов линкофарма. При расширении первоначального набора с помощью алгоритма ParentPenalty мы отмечаем в качестве спама более 161 URL-адреса. В нашей таблице интернет-адрес №5, №6 и №7 принадлежит одному бизнесу, и после расширения исходного множества с применением ParentPenalty, в новом наборе некачественных документов появилось еще 2 сайта-участника данного линкофарма. Для 1 и 2-го URL-адреса нам также удалось обнаружить по одному сильно-связанному веб-сайту. После удаления всех ссылок внутри множества некачественных HTML-страниц, а также понижения веса для всех ссылок, ведущих с одного хоста на один единственный документ, расположенный на другом хосте, мы получаем новую матрицу смежности для этого запроса. Используя алгоритм «взвешенной популярности» мы генерируем новый топ лист для текущего запроса (см. Табл. 11-В):

Табл. 11 Результаты для запроса «научно-исследовательский центр IBM»
Для следующего запроса «пикник» (Табл. 12) мы использовали алгоритм HITS. Надо сказать, что помимо большого процента иррелевантных запросу URL-адресов, ряд из них оказался сильно связанным множеством. Нам удалось идентифицировать 41подозрительный URL, среди которых в Таблице 12-А представлены №1, №2, №3 и №8. При расширении данного набора с помощью алгоритма ParentPenalty число обнаруженных спам URL-ов достигло 368, включая №9. После удаления всех ссылок между страницами-участницами link farm, наш алгоритм «взвешенной популярности» сгенерировал следующий ТОП10 сайтов (см. Табл. 12-В):

Табл. 12 Результаты для запроса «пикник»
Для сравнительной оценки релевантности результатов, полученных в процессе использования наших алгоритмов с теми результатами, которые получаются при применении HITS и BHITS, мы создали специальный оценочный веб-интерфейс, позволяющий реальным пользователям производить «слепую оценку» ответов поисковой машины. Для этого мы выбрали 20 запросов, для каждого из которых ТОП 10 URL-адресов генерировался как с помощью алгоритма Джона Клейнберга (Jon Kleinberg) HITS, так и посредством нашей «взвешенной популярности» с последующим удалением ссылок внутри спам-множества и перемешиванием URL-адресов, полученных разными методами. Двадцать восемь пользователи должны были оценивать каждый URL-адрес по имеющимся в их распоряжении запросам в соответствии с пятибалльной шкалой релевантности: «достаточно релевантный», «релевантный», «затрудняюсь ответить», «не релевантный» и «абсолютно иррелевантный». При этом, всякому интернет-адресу можно было дать только 1 оценку; у каждого пользователя имелось право воздержаться от каких-либо оценок в принципе. Распределение пользовательских предпочтений для HITS, BHITS и нашего алгоритма продемонстрировано в Таблице 13:
| Категория | HITS | BHITS | Наш алгоритм |
| Достаточно релевантный | 12.9% | 24.5% | 47.1% |
| Релевантный | 10.7% | 18.3% | 25.5% |
| Затрудняюсь ответить | 6.6% | 10.5% | 7.3% |
| Не релевантный | 26.8% | 14.8% | 12.0% |
| Абсолютно иррелевантный | 42.8% | 31.9% | 7.8% |
Табл. 13 Результаты оценок
Как вы можете видеть, по сравнению с оригинальным алгоритмом Джона Клейнберга наш метод «взвешенной популярности» имеет существенно большее число оценок со значением «релевантный» и «достаточно релевантный». Если мы объединим первые две категории, то наша технология достигает точности в 72.6%, в противовес алгоритму HITS и BHITS, имеющих по 23.6% и 42.8% соответственно. Следовательно, предложенный нами алгоритм создает более релевантную выдачу для отобранных поисковых запросов; рисунок 34 показывает, что для подавляющего числа запросов наш метод набирает больше очков, чем BHITS.
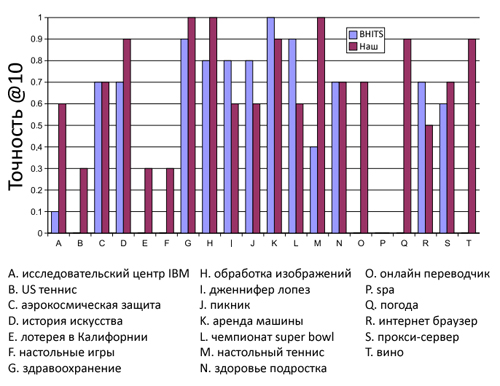
Тестируя корректность нашего подхода, мы предложили нашим пользователям субъективно оценить те веб-сайты, которые по результатам работы нашего алгоритма были признаны некачественными. Распределение пользовательского мнения, касательно обнаруженных спам-сайтов отражено в Таблице 14.
| Мнение | Процент |
| Достаточно релевантный | 5.4% |
| Релевантный | 4.8% |
| Затрудняюсь ответить | 4.1% |
| Не релевантный | 23.7% |
| Абсолютно иррелевантный | 61.7% |
Табл. 14 Пользовательская оценка спам-ресурсов.
Невзирая на то, что практически 85% некачественных узлов отмечаются нашими асессорами как «абсолютно иррелевантные», в некоторых случаях они не только соответствовали пользовательскому запросу, но и имели высокий показатель авторитетности. Более подробно данная проблема рассматривается ниже, а сейчас мы попытаемся обосновать необходимость в расширении нашего первоначального спам-множества (см. Таб. 15):
| Мнение | Процент |
| Достаточно релевантный | 45.9% |
| Релевантный | 24.8% |
| Затрудняюсь ответить | 7.8% |
| Не релевантный | 13% |
| Абсолютно иррелевантный | 8.3% |
Табл. 15 Пользовательская оценка для результатов без шага по расширению исходного набора.
Как видно, сумма «достаточно релевантный» и «релевантный» web-документ составляет только 70.7%, что несколько ниже, чем 72.6%, полученных при расширении множества спам-страниц. Многие, безусловно, будут скептически относиться к расширению исходного набора документов, поскольку не всякая HTML-страничка, ссылающаяся на подозрительный ресурс должна априори рассматриваться как плохая. Для того, чтобы исследовать данный аргумент мы создали условие, при котором, для отнесения того или иного веб-узла к нашему множеству некачественных сайтов, он должен не только сослаться на три спам-ресурса, но также иметь минимум один входящий линк с подозрительного интернет-сайта. Надо сказать, что данное условие не улучшило наших показателей, а в некоторых случаях даже привело к более худшим результатам. Не менее важным вопросом является выбор предельно допустимого порога для исходящих ссылок. Для того, чтобы продемонстрировать вам всю остроту данной проблемы мы выбрали шесть различных пороговых значений (от 2 до 7) для обоих этапов формирования нашего множества (см. Рис 35).
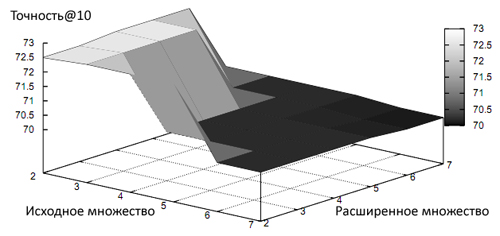
Рис. 35 Оценка точности с использованием различных предельно допустимых пороговых значений
В общей сложности мы применили 36 всевозможных комбинаций данного порогового значения. Вполне очевидно, что при расширении предельно допустимого порога точность работы нашего алгоритма будет снижаться, а это нехорошо.
Для того, чтобы наглядно показать вам практическую ценность нашего алгоритма, мы применили его на втором наборе данных, которые нам предоставила поисковая система The Swiss Search Engine. Как на этапе отбора страниц для нашего первоначального спам-множества, так и на шаге по его расширению предельно допустимое пороговое значение было установлено в 3. В итоге, наш первоначальный набор имел 27,568 сайта, а расширенный — 42,833. Мы также вычислили Google PageRank для оригинальной доменной матрицы, а также для доменной матрицы после удаления ссылок между теми узлами, которые были помечены нашим алгоритмом как спам. Если вы взгляните на Рисунок 36, то увидите распределение 70,401 спам-сайтов для двух доменных матриц; сайты располагаются в 10 блоках, которые соответствуют значению их Google PageRank (блок 1 имеет самый высокий PR, а блок 10 — наименьшей); сумма значений PR для всех обозначенных узлов составляет 10% от общего PageRank интернет-графа.
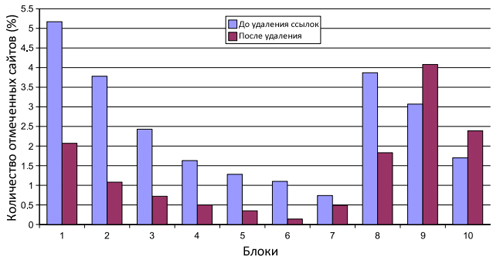
Рис. 36 Распределение сайтов, отмеченных с помощью нашего алгоритма
Философия нашего алгоритма сводится к обнаружению сильно связанных компонентов интернет-графа с последующим удалением ссылок между веб-сайтами, поскольку их сильная связанность не позволяет поисковой системе производить объективные оценки. В том же случае, если сайт действительно является качественным по всем своим характеристикам, а наш алгоритм решил отнести его к категории некачественных узлов, то его цитируемость сторонними ресурсами, не являющихся членами вышеупомянутых сообществ, вновь улучшит его видимость в результатах органической выдачи. Например, наш алгоритм отнес авторитетный домен admin.ch (Официальный Сайт Федеральных Властей Швейцарской Конфедерации) к спаму по той простой причине, что он ссылается на домены snl.ch (Швейцарская Национальная Библиотека), zivil-dienst.ch (Гражданская Служба), swiss-energy.ch (Швейцарский Федеральный Энергетический Офис), а те, в свою очередь, имеют обратные ссылки на него самого. Поисковая система The Swiss Search Engine предоставила нам черный список доменов, включающий в себя 732 спам-ресурса. Мы также описали распределение для их доменной матрицы как до применения нашего алгоритма, так и после его работы (см. Рис. 37).
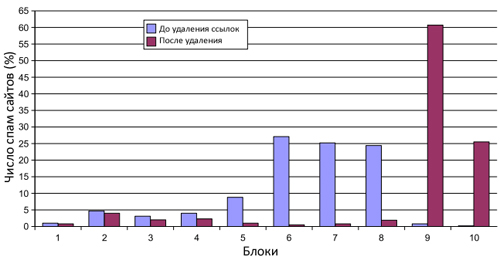
Рис. 37 Распределение сайтов в черном списке.
Страница материала:
Детекция поискового спама. Часть 1: Введение в алгоритм Google TrustRank
Детекция поискового спама. Часть 2: Расчет алгоритма Google TrustRank
Детекция поискового спама. Часть 3: От TrustRank к алгоритмам HostRank и DirRank
Детекция поискового спама. Часть 4: HostRank или PageRank, вычисляемый по графу хостов
Детекция поискового спама. Часть 5: От DirRank к алгоритму Truncated PageRank
Детекция поискового спама. Часть 6: Truncated PageRank и Вероятностный Подсчет
Детекция поискового спама. Часть 7: Знакомство с алгоритмом BadRank, обнуляющим Google PageRank
Детекция поискового спама. Часть 8: Google BadRank и ParentPenalty
Детекция поискового спама. Часть 9. Введение в алгоритм SpamRank
Детекция поискового спама. Часть 10: От исследования SpamRank к алгоритму Anti-TrustRank
Детекция поискового спама. Часть 11: Эксперименты с алгоритмом недоверия Anti-TrustRank
Детекция поискового спама. Часть 12: Применение принципов термодиффузионной
Детекция поискового спама. Часть 13: Детальный анализ алгоритма ранжирования DiffusionRank
Детекция поискового спама. Часть 14: Вычисление AIR на веб-графе, эквивалентного электронной схеме
Детекция поискового спама. Часть 15: Применение искусственных нейронных сетей
Полезная информация по продвижению сайтов:
Перейти ко всей информации