SEO-Константа
Яндекс.Директ + оптимизация
До того момента, как мы представим вам сам алгоритм DiffusionRank, давайте попытаемся продолжить наши рассуждения, которые были начаты во вступительной части материала, раскрывающего нам логическую основу, положенную в этот оригинальный метод ссылочного ранжирования. С помощью матриц (I+ γ/N R)N или eγR мы можем определить изоморфные отношения между узлами полученного ранее случайного графа (в принципе, это справедливо и для статичного ориентированного графа). Пусть fi(0)=1, fi(0)=0, если j ≠ i, тогда вектор f(0) представляет собой единицу тепла узла vi, при том важном допущении, что во всех остальных узлах температура равна нулю. Используя соответствующие уравнения, мы можем найти распределение температуры для f(0) на случайном графе в момент времени 1. Строкам матрицы (I+ γ/N R)N или eγR соответствует распределение температуры; тогда элемент hij, стоящий на пересечении i-ой строки и j-го столбца матрицы (I+ γΔtR)N или eγR обозначает то количество единиц тепла, которое узел vi может получить от vj за временной интервал от 0 до 1. Таким образом, показатель hij может использоваться в качестве оценки подобия узлов vj и vi, следующей из их связанности. Наша интуиция заключается примерно в следующем: пропускная способность между цифровыми документами, то есть то количество единиц тепла h(i,j), которое сток vi может получит от истока vj в заданный момент времени, будет обусловливаться с одной стороны пропускной способностью существующего между ними канала (чем шире труба, тем быстрее будет протекать передача тепла между качественными сайтами), а с другой — последовательностью соединения, длиной пути и т.д.

Рис.57 Алгоритм DiffusionRank
Формально алгоритм DiffusionRank может быть представлен с помощью рисунка 57, где элемент Uij в обратной матрице переходов U равен 1/Ij в том случае, если существует ссылка из узла i в j; в обратной ситуации ставим 0. Мы полностью позаимствовали процедуру отбора страниц для своей выборки с применением обратного Google PageRank из методологии TrustRank, за исключением предусмотренного в [1] фиксированного размера трастовой выборки. Несмотря на то обстоятельство, что обратный (инверсивный) PageRank не является идеальным инструментом для решения таких интересных практических задач, как достижение максимального вершинного покрытия, мы находим его достаточно привлекательным по причине того, что данный алгоритм исполняется за полиномиальное время, то есть время, которое мы потратим на решение задачи в некоторой степени зависит от ее сложности. Кроме того, положенная в его основу интуиция сводится к тому, что для создания seed set из числа веб-документов, ссылающихся на некоторое множество интернет-страниц, которые, в свою очередь, также ссылаются на прочие ресурсы в сети, и т.д., мы всего-навсего должны инверсировать наши гиперссылки. Зададим основной случайный граф как P = αB⋅A + (1 — αB)⋅1/n⋅1nхn, индуцированный веб-графом. В результате чего, имеем: R = -I+P. Отметим, при более общих настройках, где P = αB⋅A + (1 — αB)⋅1/n⋅g⋅1T, алгоритм DiffusionRank представляется обобщенным алгоритмом доверия при условии, что коэффициент γ (о нем мы поговорим несколько ниже) стремится к бесконечности, а вектор телепортации g устанавливается аналогично TrustRank. Однако вторая фаза, использующаяся в методологии Google TrustRank, в нашей модели будет опущена. Это необходимо сделать по той простой причине, что с нашей точки зрения стохастический вектор g должен определяться историей просмотра интернет-страниц (за исключением тех, которые были защищены, удалены из истории обозревателя или посещены пользователем в приватном режиме), реальным распределением популярности веб-страниц в Сети и тд. В любом случае, даже если мы попытаемся учесть в нашем случайном распределении трастовые документы, отобранные посредством применения обратного Google PageRank в первой фазе, это будет противоречить основной идее тепловой диффузии на случайном графе.
Важное замечание: в интерпретации алгоритма DiffusionRank для графа социальных сетей (например, FaceBook, Google+, Twitter, Вконтакте) его первоочередной задачей является обнаружение группы трастовых пользователей, которые могут не столь высоко ранжироваться, но, тем не менее, быть известными для широкого круга прочих аккаунтов. После локализации этих доверенных пользователей, мы наделяем их «властью» определять те вершины графа социальной сети, которым мы могли бы доверять, однако предоставленный им властный ресурс будет иметь ограниченную возможность влиять на окончательные результаты «голосования», то есть наличие «трастовой диктатуры» здесь полностью исключается.
Отметим, что в силу увеличивающегося влияния социальных сетей на оценку и продвижение сайтов в системах информационного поиска, вычисление аффилированных аккаунтов (как и веб-блогов) приобретает для нас все более актуальное значение. Однако, как вы прекрасно понимаете, эта тема требует отдельного исследования.
Во-первых, данное решение имеет как дискретную, так и непрерывную замкнутую форму. Дискретность дает нам преимущество быстрого подсчета, а непрерывность — упрощенный анализ теоретических аспектов.
Во-вторых, данное решение может использоваться как естественный инструмент для выявления межгрупповых взаимоотношений, то есть строящихся по принципу «Group to Group» (G2G). Для элементарнейшего примера, давайте обозначим за G2 и G1 две отличные группы, содержащие страницы (j1, j2,…,js) и (i1, i2, …,it) соответственно. Тогда, общее количество тепла, полученное группой G1 от группы-источника G2 может быть выражено как ∑u,vhiu,jv, где элемент ядра теплопроводимости hiu,jv, стоящий на пересечении i-ой строки и j-го столбца матрицы, обозначает то количество единиц тепла, которое некоторая страница js получает от it за временной интервал от 0 до 1. Давайте исследуем этот вопрос более подробно: в f(0) = (f1(0), f2(0),…,fn(0))T, если i ∈ {j1, j2,…,js}, тогда fi(0)=1; в противном случае 0. Теперь, используя соответствующую формулу, подсчитаем f(1) = (f1(1), f2(1),…,fn(1))T и, наконец, суммируем те fj(1), где i ∈ {i1, i2,…,in}. Полученные результаты представлены на рисунке 58.
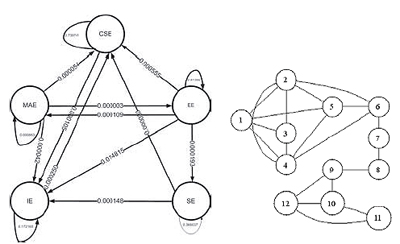
Рис.58 Два графа
Указанные в левой части нашего рисунка 58 пять групп соответствуют пяти факультетам Китайского Университета Гонконга (The Chinese University of Hong Kong). Среди них: факультет компьютерных технологий (CSE), механической и аэрокосмической инженерии (MAE), факультет электротехники (EE), промышленного инжиниринга (IE) и программирования (SE); значение коэффициента γ=1, нормализированные числовые показатели выражают количество диффундированного тепла между данными группами; при показателях меньших, чем 0.000001 ребра игнорируются. Анализируя полученные межгрупповые взаимоотношения, мы, например, можем увидеть, что наиболее сильная коммуникация образуется между группой-источником EE и ее целью IE.
В-третьих, данное решение может применяться в задачах рассечения (разреза) веб-графа. Небольшой пример для неориентированного графа представлен в правой части нашего рисунка 58. В том случае, если нам известна принадлежность узлов 1 и 12 к двум разным сообществам, тогда было бы вполне логичным обозначить узел 1 как эквивалент единицы положительной температуры, а 12 — отрицательной. По прошествии времени 1, если γ = 0.5, распределение тепла составляет [0.25, 0.16, 0.17, 0.16, 0.15, 0.09, 0.01, -0.04, -0.18 -0.21, -0.21, -0.34]; если γ = 1, тогда [0.17, 0.16, 0.17, 0.16, 0.16, 0.12, 0.02, -0.07, -0.18, -0.22, -0.24, -0.24]. Как и в первом, так и во втором варианте мы можем достаточно легко разделить наш граф: положительной температуре соответствуют узлы {1,2,3,4,5,6,7}, а отрицательной — {8,9,10,11,12}. Аналогичная процедура может быть выполнена для ориентированного и случайного графа.
В-четвертых, данное решение может эффективно применяться для противодействия схемам манипуляции результатами органического поиска. Пусть группа G2 содержит в себе трастовые странички (j1, j2,…,js), тогда для каждого документа i ∑vhi,jv является тем количеством тепла, которую i получит от интернет-страниц (j1, j2,…,js). В своих подсчетах на статичном графе мы используем дискретную аппроксимацию формулы:
Расчеты на случайном графе осуществляется с помощью уже известного выражения дискретной аппроксимации:
Здесь начальное распределение температуры f(0) устанавливается таким специальным способом, при котором все трастовые страницы имеют единицу тепла при его полном отсутствии во всех других точках. Данные действия приводят к тому, что подозрительный документ имеет существенно низкий ранг даже в том случае, если он сильно связан по входящим на него ссылкам с группой трастовых сайтов прямо или опосредованно. Совсем иная ситуация обстоит с классическим алгоритмом Google PageRank [2], который, как было подробно описано в предыдущей части нашего с вами материала, независим от входящих значений, а потому существенно уступает предлагаемому нами решению. На основании той модели цитируемости спам-документа трастовой страницей, при которой пропускная способность канала должна быть минимальной, путь максимальным и т.д., можно сказать то, что при наличии трастовой выборки (задача отбора документов для нее решается по методологии, описанной на первом этапе TrustRank [1]) алгоритм DiffusionRank может эффективно применяться в борьбе с поисковым спамом. Сложность вычисления ядра дискретной диффузии аналогично PageRank; нам также потребуется N итераций, на каждой из которых выполняется умножение вектора на матрицу подходящей размерности.
Крайне важную роль в сопротивляемости алгоритма DiffusionRank поисковому спаму играет параметр γ, который является коэффициентом теплопроводности. При высоком коэффициенте теплопроводности скорость теплопередачи будет высокой, и наоборот, при малом его значении — низкой. Классическому Google PageRank соответствует такая ситуация, когда коэффициент теплопроводности бесконечно велик, то есть тепло как на случайном, так и на статичном графе диффундирует от одного узла к другому мгновенно. Далее мы даем математическую интерпретацию. Теорема: когда γ стремится к бесконечности и f(0) не нулевой вектор, eγRf(0) пропорционально устойчивому распределению PageRank. Пусть g=1/n 1. По Теореме Перрона [3] видно, что 1 является наибольшим собственным значением P = [(1 — α)g1T + αA], и оно строго больше любого другого собственного значения. Обозначим устойчивое распределение за x, тогда Px = x. Здесь x собственный вектор, соответствующий собственному значению 1. Предположив, что n-1 прочие собственные значения P: |λ2|<1,…,|λn|<1, мы можем найти обратную матрицу S = (x S1), такую что:
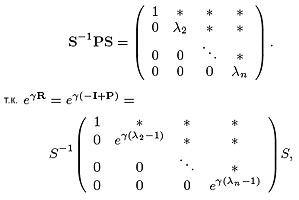
все собственные значения матрицы eλR равны 1, eλ(γ2-1),…,eλ(γn-1). Когда γ -> ∞, они становятся 1, 0,…,0, что можно интерпретировать как то, что 1 является единственным ненулевым собственным значением матрицы eλR при γ -> ∞. Видно, что при γ -> ∞ eλReλRf(0)=eλRf(0), тогда eλRf(0) является собственным вектором eλR при γ -> ∞. С другой стороны, eλRx = (I+γR+γ2/2! R2+γ3/3! R3+…)x = Ix+γRx+γ2/2! R2х+γ3/3! R3х+… x так как Rx = (-I+P)x = -x+x = 0, следовательно x собственный вектор матрицы eλR для любого γ. Поэтому x и eλRf(0) являются собственными векторами, соответствующие собственному значению 1 матрицы eλR при γ -> ∞ следовательно x = ceγRf(0). В соответствии с данной Теоремой мы можем увидеть, что наш алгоритм DiffusionRank является обобщением Google PageRank. В том случае, если γ =0 никакого манипулятивного воздействия на механизм ранжирования не происходит по причине отсутствия термодиффузии и неизменности самой системы, однако структура Сети полностью игнорируется вследствие того, что eγRf(0)=e0Rf(0)=If(0)=f(0); при γ = ∞ алгоритм DiffusionRank становится классическим PageRank, которым мы можем достаточно легко манипулировать. Ниже показано, что при γ = 1 мы можем достичь хороших практических результатов.
Пока мы используем преимущество сжатой формы экспоненциального ядра теплопроводимости, для наших итераций лучше всего подойдет уравнение для дискретного ядра термодиффузии, но здесь возникает вопрос, связанный с их числом: для заданного предельно допустимого порогового значения ε найдем такое N, при котором ||((I+γ/N R)N — eγR)f(0)|| < ε для всех f(0) в сумме дающих единицу. Так как решить данную задачу сложно, предлагаем использовать эвристический подход, обусловленный следующими наблюдениями. При R = -I+P имеем (I+γ/N R)N = (I+γ/N (-I+P))N =
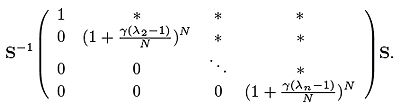
Если мы будем внимательны, то обнаружим, что собственными значениями (I+γ/N R)N — eγR являются (1 + γ(λn-1)/ N)N — eγ(λn-1). Наша эвристика сводится к достижению такой разницы между собственными значениями, которая была бы меньше предельно допустимого порогового значения для всех положительных λs. Мы также обнаруживаем, что в том случае, если γ = 1, λ<1, тогда |1+γ(λ-1)/ N)N — eγ(λ-1)|< 0.005 при N ≥ 100, и |1+γ(λ-1)/ N)N — eγ(λ-1)|< 0.01 при N ≥ 30. Таким образом, мы принимаем N=30 или N=100, или какое-либо другое число итераций соразмерно требованию точности. В настоящей работе мы будем использовать N=100 для получения действительных собственных значений в (I+γ/N R)N — eγR меньших чем 0.005.
Входные данные включали в себя малый граф, а также два реальных веб-графа среднего и большого размера. Малый граф представлен на рисунке 59 (а). На нем мы наблюдаем такую манипулятивную схему между узлом 1 и узлами A,B,C…, при которой все их множество ссылается на узел 1, а тот, в свою очередь, имеет обратные линки на них. Данные для двух реальных веб-графов (Китайский Университет Гонконга, октябрь 2004 года) включали в себя 18,542 и 607,170 страниц для среднего и большого веб-графа соответственно. В числе запущенных алгоритмов значились PageRank, TrustRank и DiffusionRank (мы не стали использовать в своих опытах Manifold Ranking по той причине, что нам неизвестны стохастический вектор g и K-параметр персонализированного PageRank из [4]). Все оценочные значения умножались на количество страниц таким образом, что сумма оценок соответствовала количеству интернет-узлов. С учетом этой нормализации мы могли сравнивать результаты на отличных по своему размеру веб-графах, поскольку после нее среднее оценочное значение будет являться единым для каждого графа. Сперва мы рассчитываем оценочную разницу: между A={Ai}ni=1 и B={Bi}ni=1 она определяется как ∑ni=1 |Ai-Bi|. Далее нас интересует разница попарного ранжирования (сравнения): она определяется как число существенных отличий между A и B. Например, пары (A[i],A[j]) и (B[i],B[j]) имеют существенную разницу в том случае, если выполняется одно из условий: и A[i] >[<]A[j]+0.1, и B[i] ≤ [≥]A[j]; и A[i] ≤ [≥]A[j], и B[i] > [<]A[j] + 0.1.
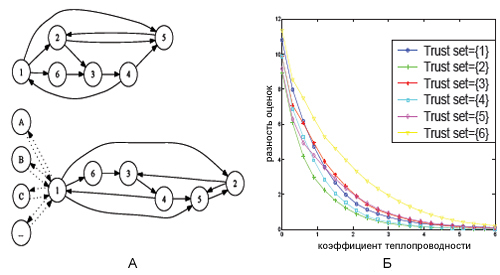
Рис.59 Малый граф (a) и аппроксимация PageRank (б)
Для тех узлов, которые имеют нулевую полустепень исхода (висячие узлы) мы будем применять модифицированную версию алгоритма Google PageRank [5], в которой висячие страницы случайно ссылаются на каждый интернет-узел в равномерном порядке. Во всех алгоритмах α=αI=αB=0.85, а количество итераций MB=100. Для Google PageRank и DiffusionRank стохастический вектор g имеет равномерное распределение; в DiffusionRank параметр γ=1. Продемонстрируем, что в случае, если γ стремится к бесконечности, разность оценок между Google PageRank и DiffusionRank стремится к нулю. На рисунке 59 (б) показано аппроксимирующее свойство DiffusionRank на малом графе, которое было доказано в Теореме. На оси абсцисс отмечены значения γ, а на оси ординат — разность оценок между PageRank и DiffusionRank. Рассматриваются все возможные трастовые наборы с L=1. Для L>1 результаты будут представлять собой линейную комбинацию некоторых из этих кривых в силу линейности решения уравнения теплопроводимости. На прочих графах, отличных от малого, результаты будут аналогичными.
Здесь мы описываем вам то, как изменяется ранговая оценка страниц по мере увеличения интенсивности манипуляционного воздействия. Мы определяем интенсивность манипуляций количеством добавляемых точек, ссылающихся на точку-объект манипуляции. Если взглянуть на рисунок 60, то на оси абсцисс мы откладываем число добавляемых к нашей манипулятивной схеме точек, а на оси ординат — соответствующие значения ранга объектов манипуляции. Для наглядности обратимся к следующему примеру: каждый узел-участник обманной технологии из рисунка 59 (а) имеет соответствующие ему значения Google PageRank, TrustRank (TR), DiffusionRank (DR), которые отражены на одном из шести графиков рисунка 60.
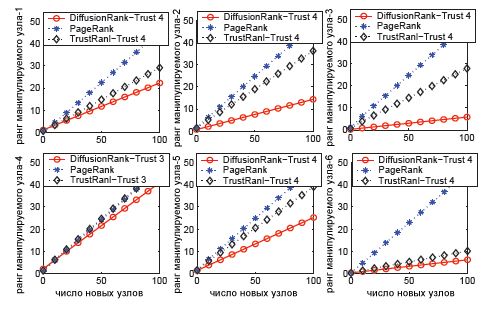
Рис.60 Ранговые значения манипулируемых документов на малом графе
Подсчитаем для каждого графика трастовые множества, используя данные обратного PageRank [1.26, 0.85, 1.31, 1.36, 0.51, 0.71]. Пусть L=1. Если 4 не является спам-узлом, тогда трастовым набором является {4}, в противном случае — {3}. Отметим, что во всех вариантах, по мере увеличения количества ссылающихся страниц, ранговые значения спам-узлов, присваиваемые алгоритмом DiffusionRank возрастают медленней. На большом и среднем (является подграфом большого) графе ситуация аналогична, что демонстрирует нам рисунок 61.
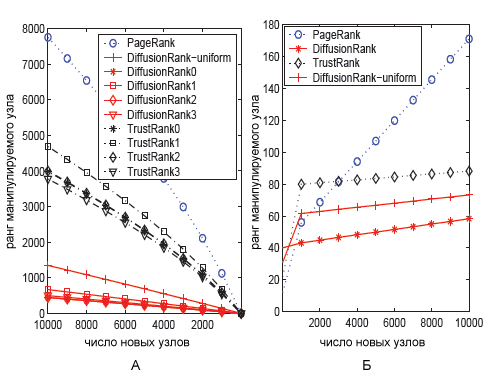
Рис.61 Ранговые значения манипулируемыех узлов на среднем (а) и большом веб-графе (б)
Для получения результатов (DiffusionRanki и TrustRanki) для первого случая (Рис. 61(а)) мы использовали четыре трастовых набора (L=1), обозначенных за i=0,1,2,3. Во втором случае (Рис. 61(б)) был использован только один трастовый набор (L=1). В обоих ситуациях мы можем оценить положительный эффект при работе алгоритма DiffusionRank при отсутствии трастового набора, когда априори мы доверяем всему множеству веб-узлов. Изменяя количество страниц, мы также сравниваем разницу между порядком сортировки А до манипулятивного воздействия на документ и порядком ранжирования PA после спам-манипуляций. На этом этапе оценивается стабильность всех наших алгоритмов; соответственно наименьшая разность в порядке ранжирования документов говорит нам о стабильности метода в том смысле, что спам-технологии оказывают воздействие на документ лишь в самой незначительной степени. Например, рисунок 62(а) показывает, что при добавлении новых узлов, ссылающихся на спам-документ, разность увеличивается. Если мы будем рассматривать несколько вариантов настроек параметра γ, то обнаружим, что при γ=1 наименьшая разность в результатах достигается именно с использованием алгоритма DiffusionRank.
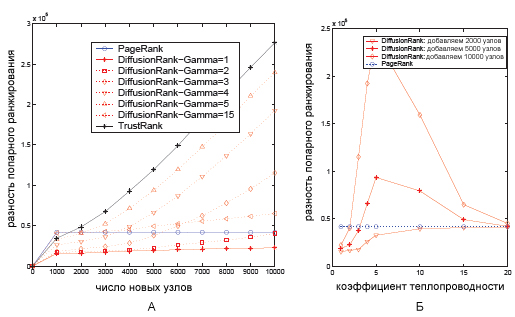
Рис.62 Оценка стабильности алгоритмов на среднем веб-графе (а) при различных коэффициентах теплопроводности (б)
Интересно, что после достижения максимального значения коэффициента теплопроводности γ, разница между алгоритмами PageRank и DiffusionRank будет уменьшаться, приближая результаты нашего алгоритма к классической методологии Google. Данная тенденция отражена на рисунке 62(б) с тремя различными настройками параметра γ — количество спам-узлов 2000, 5000 и 10.000 соответственно. Можно увидеть, что при γ<2 получаемые значения ниже тех, что дает PR, а при γ>20 разница между алгоритмами DiffusionRank и Google PageRank крайне несущественна. Отсюда мы полагаем, что DiffusionRank (при γ=1) является крайне устойчивым к различным схемам манипуляции ранговыми значениями документов и результатами органического поиска.
Страница материала:
Детекция поискового спама. Часть 1: Введение в алгоритм Google TrustRank
Детекция поискового спама. Часть 2: Расчет алгоритма Google TrustRank
Детекция поискового спама. Часть 3: От TrustRank к алгоритмам HostRank и DirRank
Детекция поискового спама. Часть 4: HostRank или PageRank, вычисляемый по графу хостов
Детекция поискового спама. Часть 5: От DirRank к алгоритму Truncated PageRank
Детекция поискового спама. Часть 6: Truncated PageRank и Вероятностный Подсчет
Детекция поискового спама. Часть 7: Знакомство с алгоритмом BadRank, обнуляющим Google PageRank
Детекция поискового спама. Часть 8: Google BadRank и ParentPenalty
Детекция поискового спама. Часть 9. Введение в алгоритм SpamRank
Детекция поискового спама. Часть 10: От исследования SpamRank к алгоритму Anti-TrustRank
Детекция поискового спама. Часть 11: Эксперименты с алгоритмом недоверия Anti-TrustRank
Детекция поискового спама. Часть 12: Применение принципов термодиффузионной
Детекция поискового спама. Часть 13: Детальный анализ алгоритма ранжирования DiffusionRank
Детекция поискового спама. Часть 14: Вычисление AIR на веб-графе, эквивалентного электронной схеме
Детекция поискового спама. Часть 15: Применение искусственных нейронных сетей
Полезная информация по продвижению сайтов:
Перейти ко всей информации