SEO-Константа
Яндекс.Директ + оптимизация
После рассмотрения алгоритма ClickRank, мы переходим к следующим поведенческим алгоритмам, которые называются BrowseRank Plus и MobileRank. В этой части работы мы рассматриваем использование процессов Маркова для расчёта важности интернет-страниц. Авторитетность веб-страниц является ключевым фактором, оказывающим влияние на информационный поиск. Множество алгоритмов, таких как PageRank и его модификации, предлагались для расчёта авторитетности в разных условиях, используя различные источники данных и допущения. Поднялся вопрос, возможно ли описать все вариации алгоритмов единым способом и есть ли какие-то правила для разработки алгоритмов по новым условиям. Чтобы ответить на эти вопросы, мы представляем в этой работе Общий Фреймворк Маркова. С этим фреймворком используется Сетевой Скелетный Процесс Маркова для моделирования случайного блуждания веб-пользователя по графу. Авторитетность страницы определяется как произведение двух величин: доступность страницы, средняя вероятность, что пользователь достигнет страницы и полезность страницы, среднее значение которой пользователь получает за визит. Оба фактора могут быть рассчитаны как стационарное распределение вероятностей соответствующей вложенной цепи Маркова и средней продолжительности визита на каждой странице Сетевого Скелетного Процесса Маркова, соответственно. Мы покажем, что этот общий фреймворк может описать множество существующих алгоритмов, включая PageRank, TrustRank и BrowseRank как свои частные случаи. Так же мы покажем, что фреймворк может помочь в разработке новых алгоритмов для решения более сложных проблем путём конструирования графов из новых источников данных, добавляя новые элементы в Сетевой Скелетный Процесса Маркова и используя новые методы для оценки двух вышеупомянутых факторов. В частности мы демонстрируем работу фреймворка с использованием нового процесса, названного Зеркальным Полумарковским Процессом. В новом процессе предполагается, что продолжительность визита страницы, будучи случайной величиной, зависит и от самой страницы и от её входящих ссылок. Результаты эксперимента на графе сёрфинга пользователей и мобильном веб-графе подтверждают эффективность Зеркального Полумарковского Процесса по сравнению с ранними моделями в нескольких задачах, даже в присутствии спама и когда принятые в алгоритмах допущения о предпочтениях пользователей работают некорректно или не работают вообще.
Авторитетность веб-страницы является важнейшим фактором в информационном поиске, так как она играет ключевую роль в сканировании Веб-страниц, индексировании просканированных страниц и ранжировании проиндексированных страниц. Для расчёта авторитетности было предложено множество эффективных алгоритмов, таких как PageRank (Брин и Пейдж 1998, Пейдж и др. 1998) и TrustRank (Gyongyi и др. 2004).
PageRank и его модификации обычно моделируются как дискретные процессы Маркова на ссылочном веб-графе для расчёта важности страницы. PageRank фактически имитирует случайное поведение пользователя среди гиперссылок. Применяя вышеописанные алгоритмы люди разрешили множество серьёзных проблем в информационном поиске. Однако эти алгоритмы так же имеют определённые ограничения в моделировании авторитетности веб-страниц. К примеру, PageRank моделирует только случайное блуждание по графу, но не учитывает интервалы времени, проведённого на отдельных страницах во время браузинга. Информация о длительности визита может быть хорошим индикатором качества страницы, что тесно связано с авторитетностью веб-страниц.
Чтобы решить эту проблему был предложен BrowseRank (Liu и др. 2008) для оценки пребывания пользователя на странице и расчёта на её основе важности веб-страницы. Он собирает данные о сёрфинге пользователя и строит граф браузинга пользователя, который содержит как информацию о переходах пользователя, так и данные о продолжительности его визитов. В BrowseRank используется непрерывный процесс Маркова для моделирования пользовательского поведения при сёрфинге, а стационарное распределение процесса рассматривается как оценки важности страниц.
Однако по-прежнему существуют вопросы, которые нельзя адекватно разрешить с использованием вышеупомянутых алгоритмов. Приведём два примера.
С этими и многими другими проблемами на горизонте, возможно, будет необходимо разрабатывать новые технологии для разрешения проблем в нынешних и новых условиях. Для этого важно понять, существует ли общая теория алгоритмов и как она может помочь в разработке новых. Это является единственной целью данной работы.
Учитывая что предыдущие работы основывались на случайном блуждании по графу и использовали процессы Маркова в математическом моделировании, мы предлагаем использовать общий фреймворк Маркова для единого описания этих алгоритмов. В фреймворке мы рассматриваем как смоделировать важность страницы с точки зрения случайного пользователя, допуская, что имеется ссылочный граф и граф сёрфинга пользователя. В этом случае важность страницы соответствует значению, которое страница может передать пользователю. Можно считать, что на важность влияют два фактора: доступность страницы и полезность страницы. Первая отражает возможность достижения страницы сёрфером, а вторая является значением, которое передаётся пользователю при посещении. Сетевой Скелетный Процесс Маркова способен отобразить оба фактора в виде стационарных распределений вероятностей вложенной цепи Маркова (Embedded Markov Chain, EMC) и средней продолжительности визита. В частности, чем крупнее стационарное распределение EMC страницы, тем выше её доступность; чем больше средняя продолжительность визита, тем большую полезность предоставляет страница пользователю. Произведение стационарных распределений EMC и средней продолжительности визита будет являться авторитетностью страницы. Во многих случаях возможно доказать, что произведение пропорционально стационарному распределению самого Сетевого Скелетного Процесса Маркова, если оно существует.
Существующие алгоритмы PageRank и BrowseRank хорошо вписываются в данный фреймворк. К примеру, PageRank основан на дискретном процессе Маркова, который является частным случаем Сетевого Скелетного Процесса Маркова, а BrowseRank основан на непрерывном процессе Маркова, ещё одном частном случае Скелета.
Более того, общий фреймворк так же даёт нам инструкцию по созданию новых алгоритмов. Мы можем разработать новые методы путём создания графа по новым источникам данных, добавляя новые элементы (family members) к Сетевому Скелетному Процессу Маркова или разрабатывая новые методики оценки стационарного распределения процесса-Скелета и средней продолжительности визита. Для демонстрации использования фреймворка мы предлагаем использовать новый процесс, названный Зеркальным Полумарковским Процессом. В новом процессе продолжительность визита зависит не только от данной страницы, но ещё и от предыдущих страниц, посещённых пользователем. Допуская такое предположение, мы можем разрешить вышеописанные проблемы существующих алгоритмов. Что касается мобильного веб-графа, если мы пессимизируем оценку продолжительности визита страницы, когда переход на неё был совершён с того же сайта или партнёрского сайта, то соответственная полезность страницы будет понижена и проблема коммерциализации будет решена. В сценарии BrowseRank если предположить, что распределение продолжительности визита на странице различается вместе с тем, как различаются переходы с различных сайтов и провести нормализацию среди разных источников, то расчёт важности веб-страницы будет точнее отражать правду, связанную с продвижением сайтов или кликовом мошенничеством в полученных данных.
Мы проверили Зеркальный Полумарковский процесс и соответствующие алгоритмы как на мобильном веб-графе, так и на графе сёрфинга. Результаты эксперимента показывают, что новые алгоритмы могут работать эффективнее существующих алгоритмов в нескольких задачах, таких как нахождение ранжированных в топе страниц и фильтрации спама/мусора. Это хорошо подтверждает эффективность предложенного фреймворка.
Чтобы подытожить, опишем основные характеристики предложенного фреймворка:
PageRank (Brin, Page 1998, Page и др. 1998) и его модификации (Boldi и др. 2005; Haveliwala 1999;Haveliwala и Kamvar 2003; Haveliwala и др. 2003; Haveliwala 2002; Langville и Meyer 2004; McSherry 2005; Richardson и Domingos 2002) рассчитывают авторитетность, рассматривая веб как граф страниц, соединённых ссылками. Этот подход предполагает, что ссылочный веб-граф применяется пользователями для случайного блуждания. Дискретный процесс Маркова используется для моделирования случайного блуждания, а стационарное распределение процесса рассматривается как важность страницы. Другие работы (Bianchini и др. 2005; Kleinberg 1998) так же основаны на случайном блуждании по ссылочному графу.
Так как PageRank можно легко обмануть линкофермами (Gyongyi и Garcia-Molina 2004), было предложено несколько мощных алгоритмов против ссылочного спама. К примеру, TrustRank (Gyongyi и др. 2004) учитывает надёжность веб-страниц при расчёте важности страницы. При таком подходе выборка исходных страниц считается надёжными страницами, а затем их оценка доверия передаётся прочим страницам по ссылкам в веб-графе. Так как пропагация начинается с доверенных страниц, TrustRank имеет более высокий иммунитет к спаму, чем PageRank.
BrowseRank (Liu и др. 2008) является недавно предложенным методом, который рассчитывает авторитетность страниц на основании данных о пользовательском поведении. Конкретнее, граф сёрфинга пользователя создаётся по истории просмотренных страниц. В этом графе содержится больше информации, такой как продолжительность визитов пользователей. BrowseRank предполагает, что чем чаще пользователи кликают на страницу, тем вероятнее, что она важная. Непрерывный Процесс Маркова используется для моделирования случайного блуждания по графу сёрфинга пользователя. Затем BrowseRank рассматривает стационарное распределение процесса как авторитетность веб-страницы. Другие работы, такие как (Berberich и др. 2004; Yu и др. 2005) так же используются информацию о времени, чтобы рассчитать важность страниц. В алгоритме T-Rank (Berberich и др. 2004), новизна определялась датами самых свежих обновлений страниц и ссылок, а затем новизна и частота обновления использовались для настройки случайного блуждания и итоговой цепи Маркова в расчёте PageRank. В алгоритме Timed PageRank (Yu и др. 2005) входящим ссылкам веб-страницы назначаются свои веса в зависимости от времени их создания. Коэффициент затухания настроен таким образом, что самые свежие ссылки получают самый большой вес. Другими словами, ссылочная информация с различных снимков графа сжимается до одного веб-графа и после этого на него применяется алгоритм PageRank. Как следствие, обе вышеупомянутые работы могут рассматриваться как расширение взвешенного алгоритма PageRank, который так же охватывается предложенным фреймворком.
Для начала рассмотрим ключевые характеристики для расчёта важности веб-страниц и представим Сетевой Скелетный Процесс Маркова.
Мы предполагаем, что веб-пользователь случайно блуждает по веб-графу. Под случайным блужданием подразумевается траектория, состоящая из успешных случайных переходов по узлам графа. Веб граф может быть ссылочным графом или графом просмотров. В первом случае каждый узел в графе — это веб-страница, а каждое ребро — это ссылка с одной страницы на другую. Во втором случае каждый узел в графе — это веб-страница, а каждое ребро — это переход с одной страницы на другую. Информацию о переходах можно получить собирая данные о поведениии миллиардов веб-пользователей (Liu и др. 2008). Таким образом, случайный сёрфер — это пользователь, комбинирующий характеристики всех веб-пользователей.
Важность веб-страницы можно рассматривать как среднее значение, которое страница передаёт случайному пользователю во время сёрфинга. Отметим, что посещение страницы пользователем случайно и значение, которое страница может передать пользователю за его посещение так же случайно. Таким образом на авторитетность страницы могут влиять всего два фактора:
Доступность страницы, в основном, определяется структурой графа. К примеру в ссылочном графе если у страницы много входящих ссылок, то она, возможно, более часто посещается пользователями. На полезность страницы могут влиять разные факторы, например, контент страницы, посещённой ранее. Фактически полезность страницы может зависеть не только от самой страницы, но так же и от прочих, относящихся к ней страницам.
Очевидно, Сетевой Скелетный Процесс Маркова — это стохастический процесс, который содержит цепь Маркова в качестве своего Скелета. Он был предложен и изучен в теории вероятностей (Hou и Liu 2005; Hou и др. 1998) и применялся во многих отраслях от теории очередей до расчёта надёжности.
ССПМ — это стохастический процесс Z, определённый следующим образом. Отметим, что мы пытаемся привести интуитивное определение. Предположим, что X — это цепь Маркова с пространством состояний S и матрицей вероятностей переходов P. Пусть X0, X1, …, Xn, … определяет последовательность X, где Xn — это состояние, а Xn+1 определяется распределением вероятностей P(Xn+1|Xn), (n = 0, 1, …). Далее предположим, что Y — это стохастический процесс в ряду положительных вещественных чисел R+. Пусть Y0, Y1, …, Yn, … определяют последовательность Y, где Yn,(n = 0, 1, …) — это положительное вещественное число. Предположим, что есть состояния системы S0, S1, …, Sn,…, и Sn ⊆ S, (n = 0, 1, …). Y определяется распределением вероятности P(Yn|Sn), n = 0, 1,… . Тогда Скелет процесса Маркова Z — это стохастический процесс, основанный на X и Y. Последовательность Z может быть отображена как:
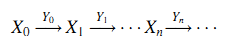
где Xn определяет состояние, а Yn определяет продолжительность визита в состоянии Xn, (n = 0, 1, …). Xn зависит от Xn-1 и Yn зависит от множества состояний Sn (n = 1, 2, …).
Множество существующих стохастических процессов — это частные случаи ССПМ. Мы перечислим лишь несколько из них.
После интуитивного объяснения, мы хотели бы дать строгое математическое определение ССПМ.
Определение 1. Стохастический процесс Z = {Z(t), t≥0} с продолжительностью ζ называется Скелетным Процессом Маркова, если существует такая последовательность случайных моментов времени {τn}n≥0, что τ0 = 0, τ1 < … < τn < τn+1 < … < ζ, limn → ∞ τn = ζ и {Z(τn)}n≥0 формирует цепь Маркова.
В теории вероятностей СПМ были неплохо изучены и применялись в теории очередей, вопросах надёжности и прочих смежных областях (Hou и Liu 2005; Hou и др. 1998). Стоит отметить, что в (Hou и Liu 2005; Hou и др. 1998) определение СПМ является более точным, чем наше, где требовалось (помимо прочего), что для каждого n≥0 будущее развитие Z (называемое Z (τn + ·)) при данной информации Z (τn) должно быть условно независимо от истории Z до τn (см. (Hou и Liu 2005) определение 1.1.1).
Пусть Z — Скелетный Процесс Маркова. Определим Xn = Z(τn) и Yn = τn+1 — τn для всех n = 0, 1, … . Тогда X = {Xn, n ≥ 0} — это цепь Маркова, а Y = {Yn, n≥0} последовательность положительных случайных величин. Очевидно, что пара (X, Y) уникально определяется Скелетным Процессом Маркова Z. И наоборот, если Z(t) = X(τn) для τn ≤ t < τn+1, то Z так же уникально определяется (X, Y). Конкретнее, предположим, что дана цепь Маркова X = {Xn, n≥0} и последовательность положительных случайных величин Y = {Yn, n≥0}. Тогда СПМ Z удовлетворяющий Z(t) = X (τn) для τn ≤ t < τn+1 может быть уникально определён следующим образом (1):
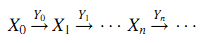
Точнее, СПМ Z с вышеобозначенным свойством может быть уникально определён парой (X, Y) посредством установки τn = ∑nk=0 Yk и установки Z(t) = Xn если τn ≤ t < τn+1. Для упрощения будем писать Z = (X, Y), если СПМ Z определяется (X, Y) по данной формуле.
Определение 2. Пусть Z = (X, Y) — это Скелетный Процесс Маркова, описанный формулой (1). Тогда X называется Вложенной Цепью Маркова (EMC) Z.
Для нашей цели изучения случайного блуждания по ссылочному графу или графу просмотров, сфокусируемся на специальном классе скелетных процессов Маркова, описанных ниже.
Определение 3. Пусть Z = (X, Y) — это скелетный процесс Маркова на S, определённый формулой (1). Предположим, что (i) пространство состояний S конечно или дискретно, (ii) вложенная цепь Маркова X = {Xn. n≥0} однородна по времени, (iii) при данной информации X, положительные случайные величины {Yn}n≥0 условно независимы друг от друга. Тогда процесс Z называется Сетевым Скелетным Процессом Маркова.
Отметим, что когда S конечно или дискретно, тогда X = {Xn, n≥0} — это цепь Маркова тогда и только тогда, когда для всех n ≥0, P(Xn+1 = j| Xn = i, Xn-1 = in-1, …, X0 = i0) = P(Xn+1 = j| Xn = i); и временная гомогенность X означает, что вероятность одиночного (single-step) перехода независима от n, т.е. для любого n, P(Xn+1 = j|Xn = i) = P(X1 = j|X0 = i) =Δ pij, ∀ i,j ∈ S. Отметим так же, что условная независимость {Yn}n≥0 при данном X значит, что Y = {Yn, n≥0} определяется распределением условных вероятностей P(Yn≤t|{Xk}k≥0), n=0, 1, … . В различных областях применения можно предположить в дальнейшем, что для каждого n существует субвыборка Sn из {Xk}k≥0, такая что P(Yn≤t|{Xk}k≥0) = P(Yn≤t|Sn).
Пусть Z = (X, Y) — это ССПМ по определению, тогда Xn — это состояние, а Yn — продолжительность состояния Xn для каждого n. По объяснению выше Xn зависит от Xn-1, а Yn зависит от множества состояний Sn из {Xk}k≥0. Наша модель ССПМ охватывает все известные стохастические процессы, используемые в изучении важности веб-страницы (поэтому модель называется Сетевой СПМ). Ниже перечислим несколько примеров:
Заметим, что ССПМ отличается от процесса Маркова высокого порядка. В общем, в цепи Маркова высокого порядка X0, X1, …, Xn, …, состояние Xn зависит от нескольких предыдущих состояний и нет процесса Y. Например, в цепи Маркова второго порядка, Xn+2 определяется распределением вероятностей P(Xn+2|{Xn+1,Xn}),(n = 0, 1, …).
Так как ССПМ может естественным образом имитировать случайное блуждание пользователя, далее мы будем рассматривать только фреймворк ССПМ. Пусть Z = (X, Y) — это ССПМ в пространстве состояний S. В нашей модели пространство состояний S соответствует веб-страницам, а процесс Z является случайным блужданием по страницам. Пользователь случайно выбирает следующую страницу, которую он хочет посетить на основе данной страницы в соответствии с X. Далее он случайным образом выбирает продолжительность визита на данной странице и нескольких других страницах, которые он посещал ранее и нескольких других страницах, которые он посетит в будущем в соответствии с Y.
Таким образом две вышеупомянутые характеристики обуславливаются двумя мерами в ССПМ.
Более того, при данной странице можно определить важность страницы как произведение значения стационарного распределения X страницы и средней продолжительности визита. Отметим, что могут существовать и другие формы отображения важности страницы, кроме вышеописанного произведения. Причина, по которой мы используем это определение — это то, что во многих случаях произведение пропорционально ограничивающему распределению вероятностей ССПМ, если оно существует.
ССПМ является очень обобщённой моделью, которая не принимает допущений по распределению P(Yn≤t|Sn). Фактически, это означает, что продолжительность визита может зависеть от большого числа прочих состояний. Таким образом существует незанятое пространство для разработки новых алгоритмов на основе этого класса общих процессов.
Отметим, что предложенный фреймворк, в основном, нацелен на расчёт важности сущностей в графах. И хотя алгоритмы ссылочного анализа типа PageRank используются для различных целей в различных графах наподобие социальных сетей, графов отношений сущностей и графов запросов, мы фокусируемся на расчёте важности сущностей и общем фреймворке Маркова в данной работе.
Предложенный фреймворк хорошо подходит для расчёта авторитетности веб-страницы и имеет хорошую теоретическую базу. Кроме того, он способен охватить и объяснить многие существующие алгоритмы.
В PageRank используется дискретный процесс Маркова для моделирования случайного блуждания по ссылочному графу. Как проиллюстрировано примером 1 в Разделе [Сетевой Скелет Процесса Маркова], это является частным случаем ССПМ.
В соответствии с Определением 2, видно, что вложенная цепь Маркова X Дискретного Процесса Маркова эквивалентна Дискретной Цепи Маркова Z. В тех же условиях вложенная цепь Маркова X обладает уникальным стационарным распределением, определяемым π~, удовлетворяющим (2):
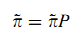
В PageRank доступность страницы рассчитывается вышеуказанным стационарным распределением π~, а полезность страницы установлена как 1 для всех страниц по допущению, что все страницы одинаково полезны для случайного пользователя, что показано P(Yn = 1) = 1.
Так как TrustRank — это модифицированный PageRank с началом итеративного процесса с надёжной исходной выборки, он тоже может быть описан фреймворком. Аналогично, прочие подходы PageRank-типа, такие как (Nie и др. 2005; Poblete и др. 2008) могут рассматриваться как частные случаи фреймворка.
В BrowseRank случайное блуждание по графу сёрфинга использует непрерывный процесс Маркова. В соответствии с примером 2 в разделе [Сетевой Скелет Процесса Маркова], это тоже частный случай ССПМ.
Определим Tj как случайную величину продолжительности визита на странице j, а Yn будет случайной величиной по экспоненциальному распределению P(Yn≤t|{Xn}), получим (3):
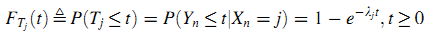
Здесь λj является параметром экспоненциального распределения, FTj(t) является кумулятивным распределением вероятностей случайной величины Tj. Средняя продолжительность визита страницы j рассчитывается как (4):
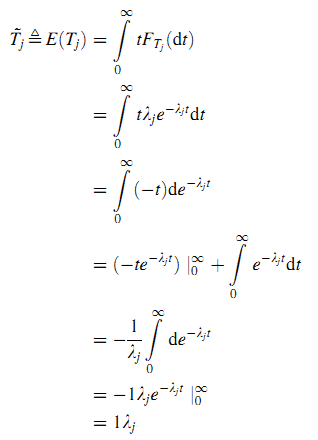
По определению 2 видно, что X — это вложенная цепь Маркова непрерывного процесса Маркова, а её уникальное стационарное распределение π~ рассчитывается как (2).
В BrowseRank это эквивалентно определению доступности страницы через стационарное распределение Вложенной Цепи Маркова непрерывного процесса Маркова и определению полезности страницы через среднюю продолжительность визита страницы. В соответствии с разделом [Моделирование важности веб-страницы] можно определить следующее распределение для расчёта оценок BrowseRank используя π~ и Tj~, где α — это нормализованный коэффициент. Формула (5):
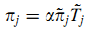
Легко заметить, что распределение пропорционально ограничивающему распределению вероятностей непрерывного Процесса Маркова.
Полезная информация по продвижению сайтов:
Перейти ко всей информации